Analisis Regresi Linier Berganda dengan R

Analisis regresi linier berganda adalah analisis statistika inferensia yang digunakan untuk memodelkan hubungan antara satu variabel dependen (respon) dengan dua atau lebih variabel independen (prediktor).
Pada tutorial ini, kita akan mempraktikan tahap demi tahap analisis regresi berganda menggunakan bahasa R. Tutorial ini fokus pada analisis regresi berganda untuk inferensia, sehingga tidak akan membahas pada tahapan melatih model dengan pembagian data latih dan data uji, validasi silang ataupun melakukan prediksi data baru.
[Tutorial ini juga tersedia dalam Bahasa Python: Analisis Regresi Linier Berganda dengan Python]
Penyiapan Data
Data yang akan digunakan dalam tutorial ini adalah data Indeks Pembangunan Manusia (IPM) Tahun 2018 dari 119 Kabupaten/Kota di Pulau Jawa. Terdapat 16 kolom (selain kolom ID) dimana Nilai IPM akan menjadi peubah respon dan 15 lainnya sebagai peubah penjelas (merupakan indikator hasil agregasi data Potensi Desa 2018) dan seluruhnya bertipe numerik. Keterangan masing-masing kolom adalah sebagai berikut:
ID: Kode Kab/Kota (4 digit Kode BPS)IPM: Nilai IPMPR_NO_LIS: Proporsi keluarga yang tidak menggunakan listrik baik PLN maupun non-PLNPR_SAMPAH: Proporsi desa/kelurahan pada kabupaten/kota dimana sebagian besar warganya membuang sampah di sungai/saluran irigasi/danau/laut serta got/selokan dan lainnyaPR_TINJA: Proporsi desa/kelurahan pada kabupaten/kota dimana tempat pembuangan akhir tinja sebagian besar warganya adalah sawah/kolam/sungai/danau/laut atau pantai/tanah lapang/kebun, lubang tanah dan lainnyaPR_MKM_SUNGAI: Proporsi desa/kelurahan di kabupaten/kota yang memiliki pemukiman di bantaran sungaiPR_SUNGAI_LMBH: Proporsi desa/kelurahan di kabupaten/kota yang memiliki sungai yang tercemar limbahPR_KUMUH: Proporsi desa/kelurahan di kabupaten/kota yang memiliki pemukiman kumuhPRA_1000: Jumlah PAUD dan TK per 1000 pendudukSD_1000: Jumlah SD/MI per 1000 pendudukSM_1000: Jumlah sekolah menengah (SMP/MTs, SMA/MA, SMK) per 1000 pendudukRS_PKS_PDK_1000: Jumlah rumah sakit, puskesmas, puskesmas pembantu, poliklinik, praktek dokter per 1000 pendudukLIN_BID_POS_1000: Jumlah rumah bersalin, praktek bidan, posyandu, polindes per 1000 pendudukAPT_OBT_1000: Jumlah apotek dan toko obat per 1000 pendudukDOK_DRG_1000: Jumlah dokter dan dokter gigi per 1000 pendudukBID_1000: Jumlah bidan per 1000 pendudukGZ_BURUK_1000: Jumlah kejadian gizi buruk per 1000 penduduk
R
# Membaca data
data <- read.csv("https://raw.githubusercontent.com/sainsdataid/dataset/main/data_ipm_jawa_2018.csv")
# Melihat Struktur data
str(data)
# menghapus kolom id karena tdak diperlukan
data$id <- NULL# OUTPUT 'data.frame': 119 obs. of 17 variables: $ id : int 3101 3171 3172 3173 3174 3175 3201 3202 3203 3204 ... $ ipm_2018 : num 70.9 84.4 82.1 81 80.9 ... $ PR_NO_LIS : num 0 0 0 0 0 ... $ PR_SAMPAH : num 0 0 0 0 0 ... $ PR_TINJA : num 0 0.0154 0.0308 0 0 ... $ PR_MKM_SUNGAI : num 0 0.615 0.446 0.25 0.304 ... $ PR_SUNGAI_LMBH : num 0 0.169 0.369 0.432 0.679 ... $ PR_KUMUH : num 0.167 0.369 0.554 0.841 0.679 ... $ PRA_1000 : num 0.787 0.199 0.228 0.255 0.134 ... $ SD_1000 : num 0.829 0.311 0.279 0.398 0.234 ... $ SM_1000 : num 0.622 0.219 0.233 0.287 0.172 ... $ RS_PKS_PDK_1000 : num 0.331 0.337 0.298 0.393 0.269 ... $ LIN_BID_POS_P_1000: num 0.29 0.1046 0.1626 0.0552 0.1242 ... $ APT_OBT_1000 : num 0.0414 0.1349 0.1488 0.2293 0.2583 ... $ DOK_DRG_1000 : num 0.373 0.212 0.448 0.313 0.262 ... $ BID_1000 : num 1.906 0.0868 0.2123 0.04 0.1309 ... $ GZ_BURUK_1000 : num 0.16574 0.00757 0.00343 0.01622 0 ...
Analisis Data Eksploratif
Ringkasan Data
Sebelum masuk ke tahap pemodelan, sangat disarankan untuk melakukan eksplorasi data untuk lebih memahami kondisi data. Terdapat beberapa hal yang akan kita lakukan dan dimulai dengan mengecek ringkasan data. Hasil ringkasan data, memberikan sedikit gambaran bagaimana karakteristik masing-masing peubah. Misalkan untuk peubah respon kita yaitu ipm_2018, nilai terkecil pada data adalah 61,00 dan nilai terbesar adalah 86,11 denga nilai rataan adalah 71,23.
Kita juga perlu memastikan tidak ada data hilang. Jika ternyata terdapat data hilang, maka perlu dilakukan penanganan, entah dengan menghapus baris, kolom atau melakukan imputasi. Pada dataset yang kita gunakan kebetulan tidak terdapat data hilang sehingga dapat dilanjutkan dengan pengecekan lainnya.
R
# Melihat summary data summary(data) # mengecek missing value cek.na <- colSums(is.na(data)) # merubah menjadi dataframe agar lebih rapi cek.na.df <- data.frame(Variabel=names(cek.na), "Jumlah NA"=cek.na, row.names = NULL) print(cek.na.df)
# OUTPUT
ipm_2018 PR_NO_LIS PR_SAMPAH ... BID_1000 GZ_BURUK_1000
Min. :61.00 Min. :0.0000000 Min. :0.00000 ... Min. :0.04001 Min. :0.00000
1st Qu.:67.91 1st Qu.:0.0000000 1st Qu.:0.00000 ... 1st Qu.:0.31515 1st Qu.:0.03831
Median :71.23 Median :0.0001314 Median :0.04982 ... Median :0.42429 Median :0.07618
Mean :71.98 Mean :0.0015136 Mean :0.07444 ... Mean :0.42723 Mean :0.12594
3rd Qu.:74.92 3rd Qu.:0.0010234 3rd Qu.:0.10515 ... 3rd Qu.:0.52864 3rd Qu.:0.15679
Max. :86.11 Max. :0.0246482 Max. :0.35890 ... Max. :1.90602 Max. :0.93573
Variabel Jumlah.NA
1 ipm_2018 0
2 PR_NO_LIS 0
3 PR_SAMPAH 0
. ... .
15 BID_1000 0
16 GZ_BURUK_1000 0 Boxplot Sebaran Variabel Numerik
Semua variabel pada daset bertipe numerik, sehingga kita dapat membuat boxplot untuk masing-masing variabel. melalui boxplot kita dapat memperoleh informasi bagaimana data menyebar dan juga dapat digunakan unutk mengidentifikasi keberadaan outlier.
Dengan memanfaatkan fungsi lapply kita dapat membuat sekaligus semua boxplot dengan beberapa baris kode saja. Hasil visualisasi boxplot di bawah ini menunjukkan bahwa masing-masing variabel memiliki pola sebaran yang beragam. Sebagian besar terdapat titik-titik data yang diindikasikan sebagai outlier. Tentunya hal ini perlu dilihat dengan lebih seksama. Jika memang kondisi tersebut sesuatu yang wajar berarti tidak ada masalah. Namun jika memang dianggap ada yang tidak sesuai maka perlu dilakukan pengecekan dan penanganan kondisi tersebut.
Di sini, kita akan menganggap semua kondisi ini sesuai dengan fakta lapangan dan tidak akan melakukan penanganan apapun.
R
library(ggplot2) # untuk membuat boxplot
library(cowplot) # untuk menampilkan dalam grid
# membuat boxplot sekaligus untuk semua variabel
plots <- lapply(names(data), function(var_x){
p <-
ggplot(data) +
aes(x=!!sym(var_x)) +
geom_boxplot(color="black", fill = "darkgreen",
lwd=0.2, alpha=0.8)
})
# menampilkan plot dalam grid
plot_grid(plotlist = plots)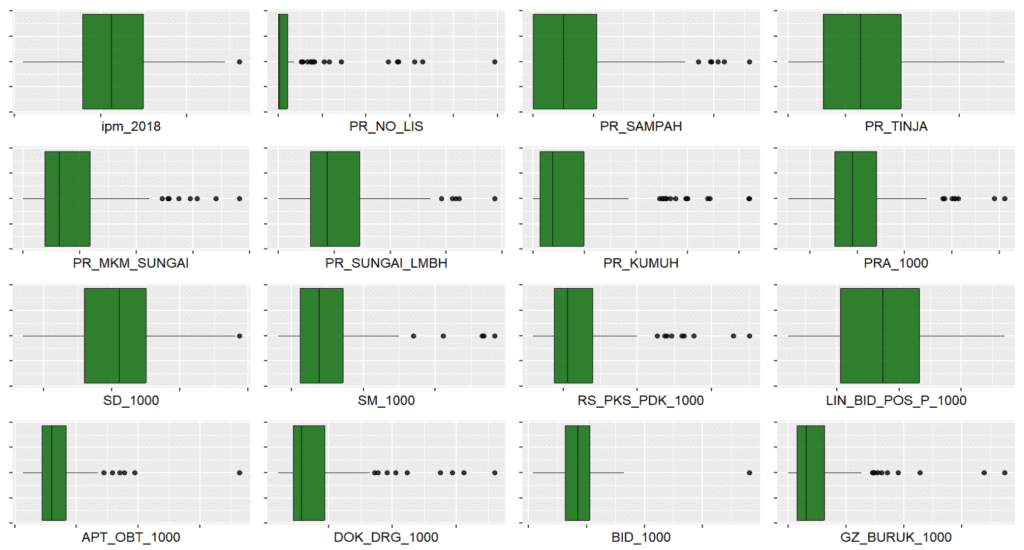
Boxplot Sebaran nilai masing-masing peubah (gambar: penulis)
Korelasi Antar Variabel
Melihat koerelasi antar variabel merupakan bagian penting. Hal ini dapat menjadi indikasi awal apakah terdapat kondisi multikolinieritas pada data yang kita miliki. Tentunya lebih jauh kita dapat melihat nilai VIF untuk lebih meyakinkan.
Dari plot korelasi berikut, terlihat beberapa kolom memiliki nilai korelasi yang tinggi, sehingga mungkin akan terdapat kondisi multikolinieritas. Adapun untuk korelasi antara peubah penjelas dengan peubah respon, terlihat beberapa peubah memiliki korelasi yang cukup tinggi seperti DOK_DRG_1000, SD_1000, PR_TINJA dan sebagainya.
Selain itu, korelasi ini dapat menjadi informasi awal untuk melihat bagaimana hubungan antara setiap variabe penjelas dengan variabel respon. Sebagai contoh, cukup mengejutkan melihat korelasi beberapa data yang tampak agak “aneh”. Misal, korelasi SD_1000 atau SM_1000 dengan nilai IPM memiliki korelasi yang negatif. Semakin banyak SD_1000 maka nilai IPM di Kabupaten/Kota tersebut semakin rendah. Sebaliknya Korelasi PR_KUMUH serta PR_SUNGAI_LMBH terhadap nilai IPM bernilai positif. Dimana artinya, semakin tinggi proporsi pemukiman kumuh, atau proporsi sungai yang tercemar limbah maka nilai IPM di kabupaten tersebut cenderung lebih tinggi juga.
Tentunya banyak hal yang mungkin menyebabkan kondisi tersebut terjadi, dan tentunya perlu dikaji secara lebih komprehensif. Namun untuk tulisan singkkat ini, kita tidak akan melihat jauh di luar teknis analisis regresi.
R
library(corrplot)
# menghitung korelasi antar kolom
corr_matrix <- round(cor(data), 2)
# membuat plot korelasi
corrplot(corr_matrix,
type="lower",
method = "color",
tl.cex = 0.6,
tl.col = "black",
addCoef.col = "#2F2F2F",
addCoefasPercent = FALSE,
number.cex = 0.6,
diag = FALSE)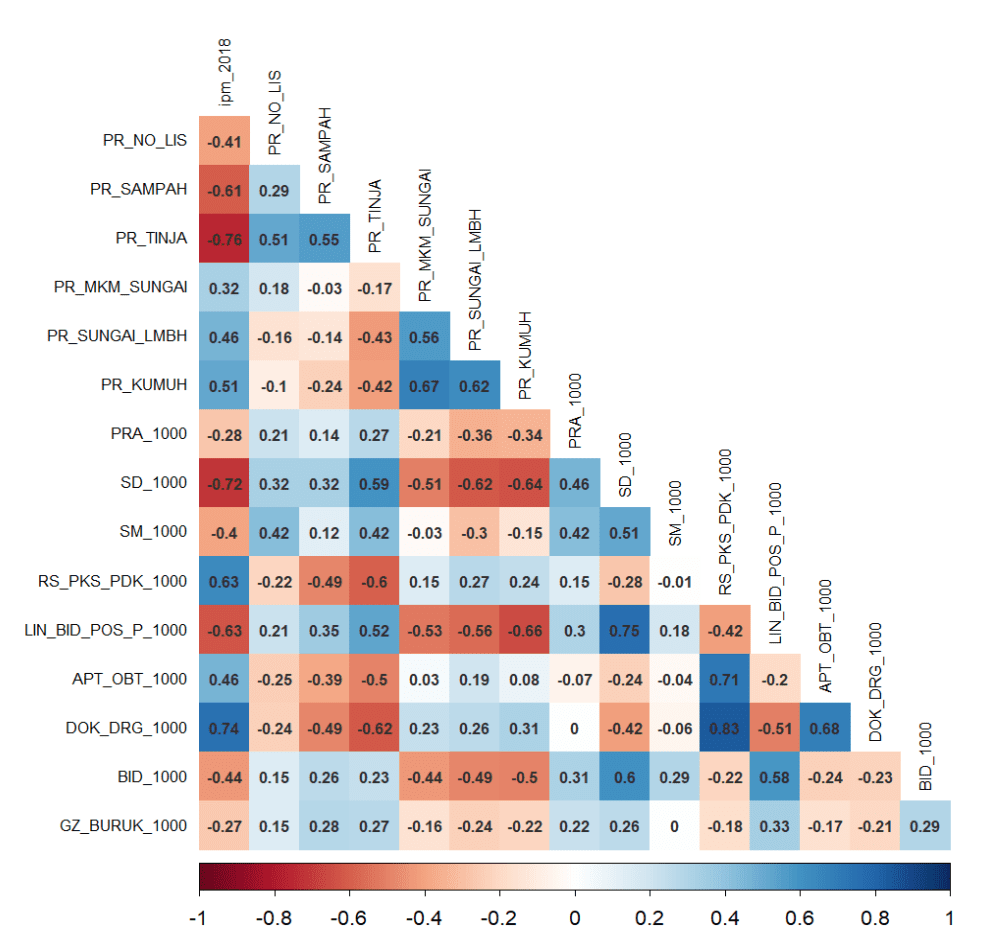
Plot korelasi antar variabel (gambar: penulis)
Model Regresi
Jika kondisi data sudah ‘clean’ maka kita dapat masuk ke tahap pembuatan model regresi linier berganda. Paket stats menyediakan fungsi lm yang dapat kita gunakan secara cepat sederhana untuk model regresi linier. Terdapat beberapa paket lain, namun untuk saat ini kita hanya akan menggunakan fungsi lm saja. Parameter yang perlu ditentukan pada fungsi lm adalah formula dan data. Formula menunjukkan nama variabel respon diikuti dengan nama-nama variabel penjelasnya (contoh: y ~ x1 + x2 + x3). Namun jika semua variabel pada data akan digunakan, maka kita cukup menuliskan simbol “y ~ .“.
Output dari model dapat dilihat dengan menggunakan fungsi summary.
R
# Melatih model regresi linear model_reg <- lm(ipm_2018 ~ ., data = data) # manampilkan ringkasan output model summary(model_reg)
# OUTPUT
Call:
lm(formula = ipm_2018 ~ ., data = data)
Residuals:
Min 1Q Median 3Q Max
-4.9279 -1.3472 -0.0228 1.2981 6.6353
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 77.69339 1.61562 48.089 < 2e-16 ***
PR_NO_LIS -54.16621 72.84019 -0.744 0.458793
PR_SAMPAH -12.32380 3.34207 -3.687 0.000364 ***
PR_TINJA -3.85873 1.63650 -2.358 0.020266 *
PR_MKM_SUNGAI -0.30645 2.23861 -0.137 0.891383
PR_SUNGAI_LMBH -0.06651 1.70957 -0.039 0.969043
PR_KUMUH 1.14777 1.87576 0.612 0.541953
PRA_1000 -1.47333 1.35941 -1.084 0.280981
SD_1000 -8.47723 2.23944 -3.785 0.000258 ***
SM_1000 -3.55704 2.85238 -1.247 0.215211
RS_PKS_PDK_1000 5.06631 3.63456 1.394 0.166340
LIN_BID_POS_P_1000 2.95048 2.03778 1.448 0.150685
APT_OBT_1000 -7.72740 2.88662 -2.677 0.008646 **
DOK_DRG_1000 13.50010 2.48140 5.441 3.61e-07 ***
BID_1000 -2.22060 1.52796 -1.453 0.149178
GZ_BURUK_1000 0.63440 1.56650 0.405 0.686335
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.282 on 103 degrees of freedom
Multiple R-squared: 0.8474, Adjusted R-squared: 0.8252
F-statistic: 38.14 on 15 and 103 DF, p-value: < 2.2e-16Output yang disajikan di atas menampilkan berbagai nilai-nilai yang biasa diintepretasikan dari hasil pemodelan. Beberapa di antaranya adalah:
Koefisien Regresi
Nilai ini menunjukkan nilai koefisien regresi ($\hat{\beta_i}$) untuk masing-masing variabel. Misalkan, untuk variabel PR_NO_LIS memiliki nilai koefisien -54,167 dan untuk SD_1000 bernilai 8,48. Tanda positif menunjukkan hubungan yang positif antara variabel penjelas dan responnya, sebaliknya tanda negatif menunjukkan hubungan negatif antara keduanya.
Statistik uji t
Komponen ini menunjukkan variabel penjelas mana saja yang signifikan. Jika nilai p-value lebih kecil dari nilai $\alpha$ tertentu, misal 0,05 maka peubah tersebut siginifikan pada tingkat keyakinan $100- $\alpha$. Informasi ini juga dapat dilihat dari kode signifikansi yang ditambahkan pada kolom terakhir. Tanda ‘***’ menyatakan variabel sangat signifikan bahkan untuk nilai $\alpha$ yang sangat kecil. Adapun untuk nilai yang standar dipakai yaitu $\alpha=0,05$ ditandai dengan simbol ‘.’ serta $\alpha=0,01$ ditandai dengan simbol ‘*’. Hasil di atas menunjukkan variabel mana saja yang signifikan atau tidak, dan terlihat bahwa banyak variabel yang tidak signifikan. Hasil ini tentunya perlu diuji lagi validitasnya dengan pengecekan asumsi serta kondisi yang tidak boleh dilanggar pada model regresi linier.
Statistik uji F
Jika statistik uji $t$ menunjukkan secara parsial signifikansi masing-masing variabel, maka statistik uji $F$ mengukur signifikansi model secara keseluruhan. Pada contoh ini, p-value $≈$ 0 ($p-value: < 2.2e-16$) menunjukkan model signifikan (bahkan dengan tingkat kesalahan yang sangat kecil, misal $alpha=0.00001$ atau lebih kecil lagi) . Dengan kata lain, terdapat setidaknya 1 variabel penjelas yang signifikan (atau setidaknya terdapat satu $i$ untuk $\text{i=1,2…,15}$ di mana nilai $\beta_i\neq0$. Hal ini tentunya juga sudah sesuai hasil pada uji parsial.
Koefisien Determinasi ($R^2$)
Nilai $R^2$ menunjukkan besarnya keragaman pada variabel respon yang dapat dijelaskan oleh variabel penjelas. Pada contoh ini nilai $R^2=0.8474$ artinya variabel-variabel penjelas pada model mampu menjelaskan sekitar 84,74 persen keragaman pada nilai IPM.
Adjusted $R^2$
Nilai adjusted $R^2$ adalah nilai $R^2$ yang diberikan penalti berupa banyaknya variabel penjelas yang digunakan. Ukuran ini biasanya digunakan saat membandingkan kinerja antar model dengan tetap mempertimbangkan kompleksitas model. Model yang lebih sederhana akan di penalti lebih kecil dibandingkan model yang kompleks. Sebagai contoh, Model A dengan 15 variabel memiliki nilai $R^2=0.84$ dan model B dengan hanya 5 variabel memiliki niai $R^2=0.82$. Jika dihitung nilai adjusted $R^2$, bisa jadi Model B akan memberikan nilai yang lebih tinggi dibandingkan Model A. Hal ini dapat dimaknai, dengan pengurangan kompleksitas model yang besar (dari 15 variabel menjadi hanya 5 variabel) model tetap memiliki kinerja yang baik dan hanya sedikit saja mengurangi $R^2$ (dari 0,84 menjadi 0,82). Jika terjadi situasi seperti ini mungkin kita akan lebih cenderung memilih model B dibandingkan A.
Pengecekan Asumsi
Analisis regresi linier berganda memiliki beberapa asumsi dan kondisi yang harus terpenuhi. Jika terdapat kondisi yang tidak terpenuhi bisa menyebabkan validitas hasil yang diperoleh kurang akurat atau bahkan keliru. Berikut penjelasan asumsi-asumsi pada analisis regresi linier berganda.
Linieritas
Premis utama dari analisis regresi linier berganda adalah adanya hubungan linear antara variabel respon dan variabel penjelas. Linearitas ini dapat diperiksa secara visual menggunakan scatterplot, yang seharusnya menunjukkan hubungan dengan kecenderungan garis lurus.
R
library(ggplot2)
library(cowplot)
var.respon <- "ipm_2018"
var.penjelas <- setdiff(names(data), var.respon)
plots <- lapply( var.penjelas, function(var_x){
p <- ggplot(data, aes_string(x = var_x, y = var.respon)) +
aes(x=!!sym(var_x)) +
geom_point(color = "blue") +
theme_minimal() +
theme(axis.text = element_blank(), axis.title = element_text(size = 8)
)
})
plot_grid(plotlist = plots, nrow = 5, ncol = 3)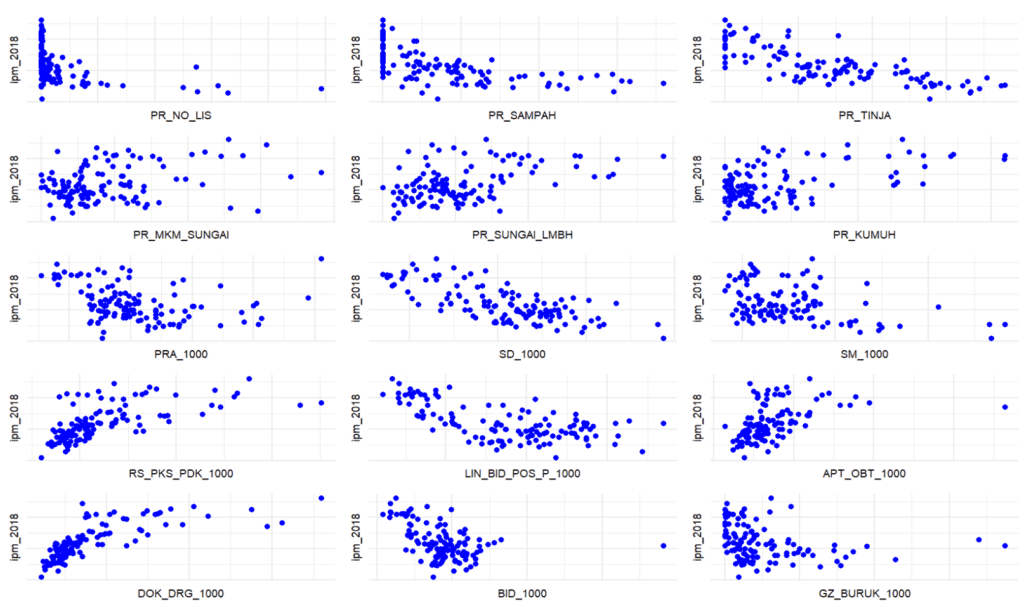
Scatter plot variabel respon dan variabel penjelas (gambar: penulis)
Berdasarkan scatter plot dapat dilihat pola hubungan antara variabel respon dengan variabel-variabel penjelasnya. Pada beberapa variabel penjelas, terlihat terdapat hubungan linier yang cukup kuat. Namun terdapat beberapa variabel yang sepertinya tidak berhubungan secara linier. Variabel-variabel ini yang kemungkinan tidak memiliki pengaruh signifikan.
Keputusan yang diambil tergantung dengan kepentingan peneliti, variabel yang tidak berhubungan linier seperti ini dapat dikeluarkan dari model ataupun dilakukan penanganan tertentu. Jika variabel-variabel tersebut misalkan tetap ingin dimasukkan, salah satu teknik yang dapat dicoba adalah transformasi data. Transformasi ini dapat berupa log natural, akar kuadrat, transformasi box-cox dan sebagainya.
Normalitas
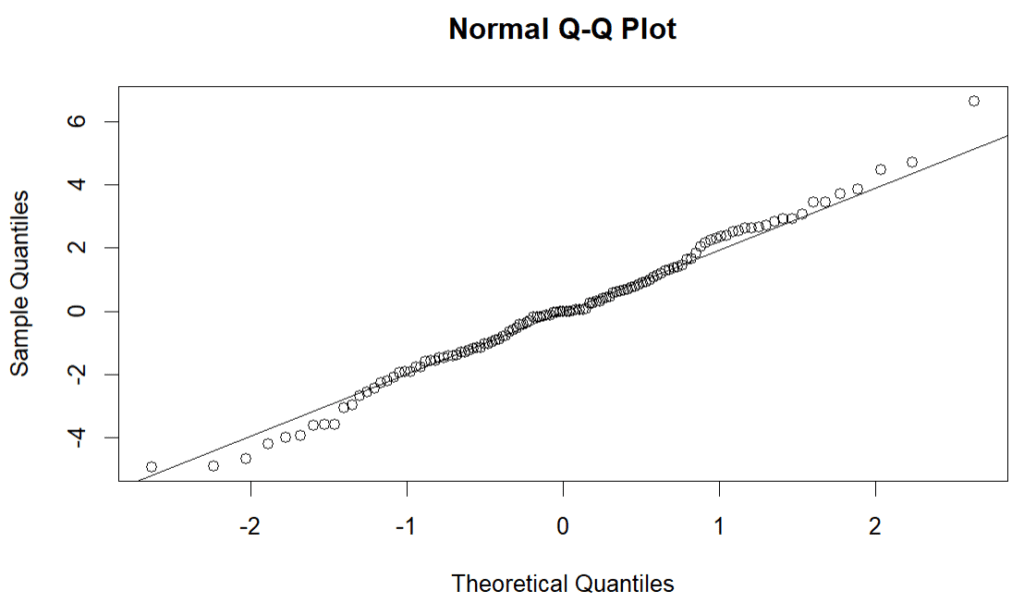
Analisis regresi linier berganda mengasumsikan bahwa residual (perbedaan antara nilai yang diamati dan nilai yang diprediksi) terdistribusi secara normal. Asumsi ini dapat dinilai dengan memeriksa histogram atau Q-Q plot dari residual, atau melalui uji statistik seperti uji Kolmogorov-Smirnov, Shapiro-Wilk dan sebagainya.
Pada hasil qq plot maupun uji formal menggunakan uji K-S (tidak tolak $H_0$), residual model memenuhi asumsi normalitas yaitu menyebar $\text{Normal}(0, \sigma^2)$.
R
# Mendapatkan residual dari model
model.res <- residuals(model_reg)
mean.res = round(mean(model.res), 4)
sd.res = round(sd(model.res), 4)
cat("Nilai tengah residual:", mean.res, "\n")
cat("Simpangan baku residual:", sd.res, "\n")
# Membuat Q-Q plot dari residual
qqnorm(model.res)
qqline(model.res)
# Melakukan uji Kolmogorov-Smirnov pada residual
ks_result <- ks.test(model.res, "pnorm", mean = mean.res, sd = sd.res)
ks_result# OUTPUT Nilai tengah residual: 0 Simpangan baku residual: 2.1323 Asymptotic one-sample Kolmogorov-Smirnov test data: residuals D = 0.049367, p-value = 0.9339 # data tidak normal jika p-value < alpha alternative hypothesis: two-sided
Homoskedastisitas
Ragam dari residual harus konsisten di seluruh tingkat variabel penjelas. Scatterplot dari residual versus nilai prediksi tidak boleh menampilkan pola yang terlihat, seperti distribusi berbentuk kerucut ataupun corong, yang artinya menunjukkan heteroskedastisitas. Jika diperlukan, terdapat pula uji-uji statistik yang dgunakan untuk mengecek asumsi ini seperti uji Breusch-Pagan, uji White dan sebagainya. Jika terdapat kondisi heteroskedastisitas, maka dapat juga dilakukan penanganan melalui transformasi data.
Pada kasus ini, berdasarkan uji BP (tidak tolak $H_0$) dan plot sebaran nilai residual terlihat relatif menyebar acak untuk setiap nilai prediksi dan tidak ada kecenderungan membentuk pola kerucut. Dengan demikian dapat dikatakan tidak terdapat heteroskedastisitas.
R
library(lmtest) # paket untuk uji model linier
# Melakukan uji Breusch-Pagan
breusch_pagan_test <- bptest(model_reg)
breusch_pagan_test
# Membuat plot residual vs nilai prediksi dengan scatter plot merah
plot(fitted(model_reg), model.res,
xlab = "Fitted Values", ylab = "Residuals",
main = "Residual vs Fitted Values",
col="red", pch = 20, cex=1.5)
# Menambahkan garis putus-putus merah di nilai 0
abline(h = 0, col = "blue", lty = 2)# OUTPUT studentized Breusch-Pagan test data: model_reg BP = 15.26, df = 15, p-value = 0.4329
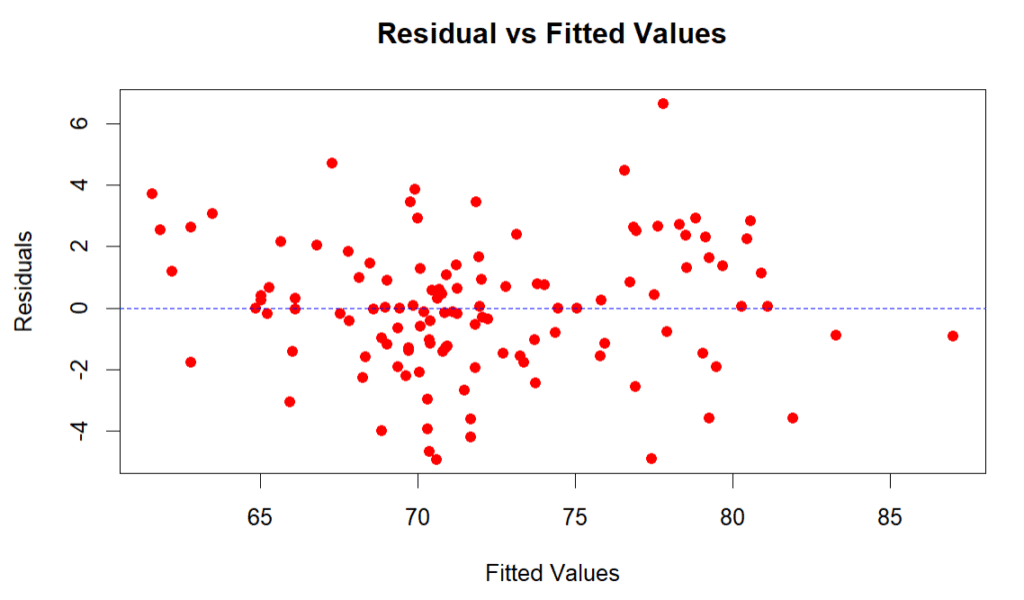
Plot residual vs fitted value (gambar: penulis)
Non-Multikolinieritas
Multikolinieritas (Ini sebenarnya bukanlah sebuah asumsi) merupakan masalah yang perlu ditangani. Analisis model dengan keberadaan multikolinieritas bisa menjadi tidak tepat. Ragam penduga menjadi lebih besar sehingga juga akan memperlebar selang kepercayaannya. Dampak dari selang kepercayaan yang lebih lebar yaitu uji dapat menjadi tidak signifikan meskipun seharusnya variabel tersebut memiliki pengaruh kuat. Hal ini juga tidak menutup kemungkinan sampai menyebabkan penduga keofisien menjadi berubah tanda (positif menjadi negatif atau sebaliknya). Jika terjadi demikian tentu hasil analisis menjadi sangat tidak reliable untuk digunakan.
Keberadaan masalah multikolinieritas dapat dilihat dengan cara berikut:
- Matriks korelasi, di mana batas koefisien korelasi 0,80 dapat menjadi ‘warning’. Pada bagian sebelumnya, kita sudah menyajikan matriks korelasi dan menunjukkan beberapa variabel penjelas dengan korelasi cukup tinggi.
- Variance Inflation Factor (VIF), dengan nilai VIF di atas 10 menunjukkan adanya masalah multikolinieritas.
R
library(car) # fungsi vif tersedia pada paket car # Menghitung VIF untuk setiap variabel dalam model vif_values <- vif(model_reg) data.frame(vif_values)
# OUTPUT
vif_values
PR_NO_LIS 1.674004
PR_SAMPAH 1.752889
PR_TINJA 3.883222
PR_MKM_SUNGAI 2.519156
PR_SUNGAI_LMBH 2.248597
PR_KUMUH 2.945363
PRA_1000 1.840095
SD_1000 4.638975
SM_1000 2.323137
RS_PKS_PDK_1000 5.283640
LIN_BID_POS_P_1000 3.867567
APT_OBT_1000 3.014481
DOK_DRG_1000 4.545848
BID_1000 2.377227
GZ_BURUK_1000 1.272896Jika terdapat masalah multikolinieritas tersebut kita mungkin perlu mengeluarkan salah satu atau lebih variabel-variabel dengan korelasi yang kuat.
Berdasarkan hasil di atas, ternyata tidak terdapat indikasi masalah multikolinieritas antar variabel penjelas. Hal ini dapat meyakinkan kita bahwa analisis regresi linier berganda yang kita lakukan sudah memenuhi asumsi-asumsi serta tidak terdapat masalah yang dapat mengganggu hasil dan interpretasinya.
Referensi
- Agresti, A., Franklin, C., Klingenberg, B. 2018. Statistics – The Art and Science of Learning from Data. 4th Edition. Essex: Pearson Education Limited
- Caitlin C. Mothes, PhD and Katie Willi. 2023. Introduction to Data Analysis in. [Introduction to Data Analysis in R (rossyndicate.github.io)]
- Weisberg, S. 2005. Applied Linier Regression, 3𝑡ℎ Edition. New Jersey : John Wiley & Sons







