Web Scraping Klasemen Liga Inggris dengan BeautifulSoup

Web Scraping adalah suatu metode pengambilan informasi yang tersedia di halaman web. Web scraping dilakukan menggunakan program tertentu sehingga proses pengumpulan innformasi tersebut menjadi lebih efisien dibandingkan secara manual. Beberapa contoh web scraping yang dapat dilakukan yaitu mengumpulkan informasi harga produk pada situs e-commerce, mengekstrak berita dari media online untuk analisis sentimen atau melakukan automasi untuk memperoleh informasi harga saham tertentu secara realtime.
Pada tutorial ini kita akan mencoba melakukan web scraping sederhana menggunakan Python. Di dalam lingkungan python sendiri terdapat banyak pustaka untuk melakukan web scraping, salah satu yang populer yaitu BeautifulSoup. Pustaka BeautifulSoup dapat diinstal menggunakan pip atau conda seperti kode berikut ini:
Python
# menggunakan pip !pip install bs4 # menggunakan conda !conda install -c conda-forge bs4
Contoh Web Scrapping dengan BeautifulSoup
Skenario yang akan kita lakukan adalah mencari informasi mengenai klasemen liga inggris melalui situs resminya di www.premierleague.com.
Informasi yang akan diambil adalah klasemen terupdate seperti yang ditunjukkan pada gambar berikut:
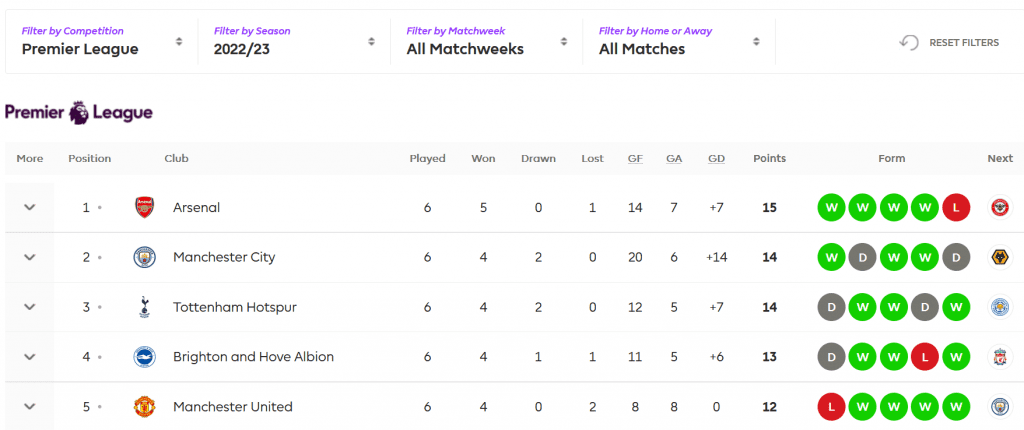
Adapun pustaka yang diperlukan adalah BeautifulSoup, urllib.request dan pandas. Untuk membaca halaman web kita gunakan fungsi url_open dan selanjutnya memanggil method read. Halaman tersebut kemudian kita gunakan untuk membuat objek soup menggunakan fungsi bs atau BeautifulSoup.
Python
from bs4 import BeautifulSoup as bs # scraping elemen html import urllib.request as ur # request halaman web import pandas as pd # halaman yang akan di-scrapping pl_tables_url = "https://www.premierleague.com/tables" # membaca halaman web page = ur.urlopen(pl_tables_url).read() # menyimpan objek html ke dalam BeautifulSoup soup = bs(page) print(soup)
Output
<html> ... <body> ... <table> <summary class="visuallyHidden">This table charts the Premier League teams</summary> <thead> <tr> <th class="revealMoreHeader text-centre" scope="col" style="display:none;">More</th> <th class="text-centre" scope="col"> <div class="thFull">Position</div> <div class="thShort">Pos</div> </th> ... </body> </html>
Menyeleksi Elemen yang Sesuai
Dari hasil sebelumnya, variabel soup menyimpan seluruh text html dari halaman yang dimuat. Karena tujuan kita adalah mengambil data klasemen, maka perlu melakukan seleksi tag yang berkaitan saja. Mengingat kompleksnya halaman yang ada maka inspeksi akan kita lakukan secara perlahan dan bertahap. Untuk menelusuri elemen dari halaman web dapat menggunakan menu inspect yang tersedia pada browser yang digunakan.
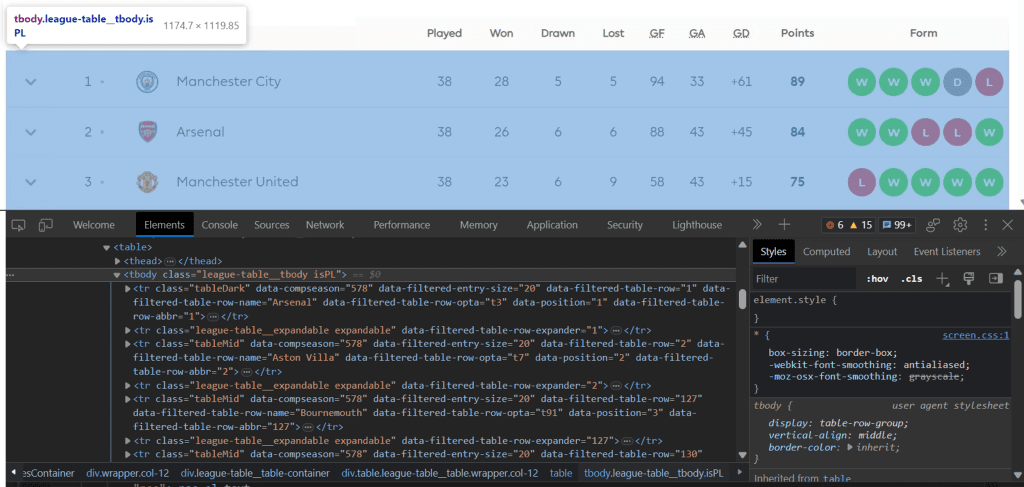
Dari hasil inspeksi, kita peroleh bahwa data klasemen tersimpan pada tbody dengan class league-table__tbody. Untuk mengekstrak elemen tersebut kita menggunakan method find pada objek soup, dengan menentukan elemen tbody dan class league-table__tbody.
Python
# mengambil elemen tbody dengan class league-table__tbody
tbody = soup.find("tbody", {"class": "league-table__tbody"})
Di dalam <tbody> tersebut terdapat daftar tag <tr> dengan beberapa tipe class yaitu tableDark, expandable, tableMid, tableLight dan juga <tr> tanpa atribut class. Jika kita ditelusuri maka informasi posisi setiap klub. Informasi klub yang berisi statistik klasemen berada pada <tr> dengan class selain expandable. Artinya berada pada elemen <tr> dengan class tableDark, tableMid, tableLight dan juga tanpa class. Oleh karena itu cara yang paling sesuai adalah dengan mencari elemen <tr> di dalam <tbody> yang memiliki class selain expandable. Terdapat beberapa cara yang bisa digunakan untuk menyeleksi, pada kode berikut yaitu memanggil method findChildren yang akan mengembalikan list elemen tr yang memiliki atribut class ["tableDark", "tableMid", "tableLight", ""].
Python
# Mengambil semua <tr> yang dengan class "expandable" pada tbody
tr_list = tbody.findChildren("tr", {"class": lambda c: c in ["tableDark", "tableMid", "tableLight", ""]})
print(tr_list)
# mencetak panjang list (jika benar maka harus 20)
print(len(tr_list))Output
[<tr class="tableDark" data-compseason="578" data-filtered-entry-size="20" data-filtered-table-row="1" data-filtered-table-row-abbr="1" data-filtered-table-row-name="Arsenal" data-filtered-table-row-opta="t3" data-position="1">
<td class="league-table__pos pos" tabindex="0">
<span class="league-table__value">1</span>
</td>
<td class="league-table__team team" scope="row">
<a href="/clubs/1/Arsenal/overview">
<span "="" class="badge badge-image-container u-hide-tablet" data-size="50" data-widget="club-badge-image">
<img class="badge-image badge-image--32" src="https://resources.premierleague.com/premierleague/badges/rb/t3.svg" srcset="https://resources.premierleague.com/premierleague/badges/rb/t3.svg 2x">
</img></span>
<span class="badge badge-image-container u-show-tablet" data-size="25" data-widget="club-badge-image">
<img class="badge-image badge-image--25" src="https://resources.premierleague.com/premierleague/badges/rb/t3.svg" srcset="https://resources.premierleague.com/premierleague/badges/rb/t3.svg 2x"/>
</span>
<span class="league-table__team-name league-table__team-name--long long">Arsenal</span>
<span class="league-table__team-name league-table__team-name--short short">ARS</span>
</a>
</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td class="hideSmall">0</td>
<td class="hideSmall">0</td>
<td>
0
...
</svg>
</td>
</tr>]
20
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...Mengambil Nilai pada Setiap Elemen
Sejauh ini, kita sudah menyimpan 20 elemen pada variabel tr_list. Namun perlu diingat, data yang tersimpan masih berupa elemen <tr> dengan berbagai tag didalamnya dan belum berupa nilai posisi klub, nama klub, point dan lain sebagainya. Oleh karena itu, kita masih harus melakukan inspeksi pada setiap elemen. Harapannya setiap elemen memiliki struktur yang sama, sehingga preoses ekstraksi dapat dibuat dalam bentuk fungsi.
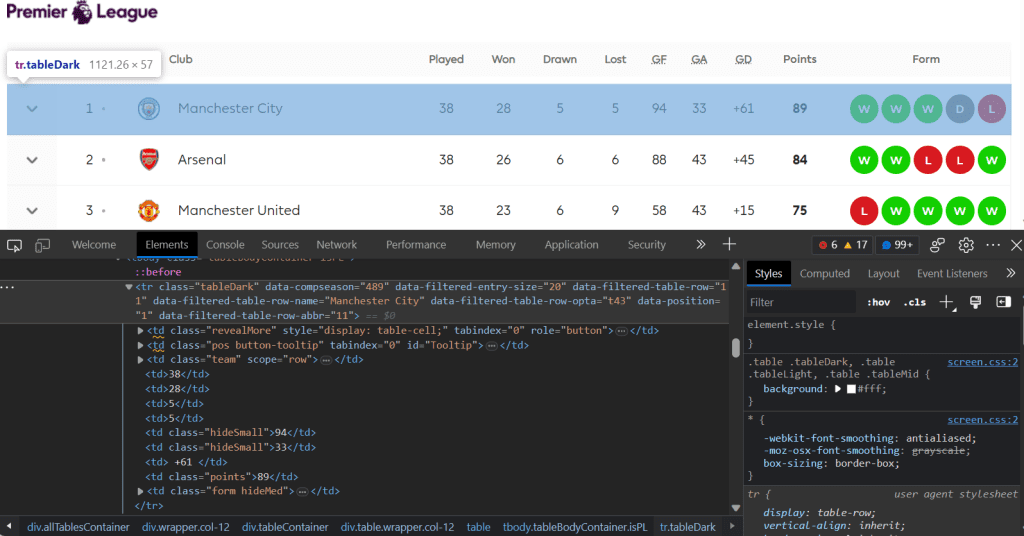
Potongan di atas adalah elemen <tr> yang pertama, dalam hal ini berisi informasi tentang Manchester City yang saat ini berada pada posisi pertama klasemen. Dari sini dapat terlihat beberapa informasi seperti 38 menunjukkan jumlah bermain, 28 jumlah menang, 5 jumlah seri dan 5 jumlah kalah, dan seterusnya yaitu jumlah gol 94, jumlah kebobolan 33, selisih gol +61 dan point 89. Beberapa informasi lain seperti peringkat dan nama klub masih tersembunyi pada tag yang lebih dalam. Terdapat sedikit masalah saat ini, karena setiap elemen tidak memiliki atribut class. Pada elemen <td> tanpa atribut class, kita akan menavigasi ke elemen <td> berikutnya menggunakan method find_next_sibling. Agar kode dapat digunakan berulang untuk setiap klub maka akan dibuat dalam bentuk fungsi.
Python
# Fungsi untuk ekstraksi data 1 klub
def extract_data(row):
pos_el = row.findChild("td", {"class": "pos"}).find(
"span", {"class": "league-table__value"}
) # posisi
team_el = row.findChild("td", {"class": "team"}).find(
"span", {"class": "league-table__team-name"}
) # nama klub
played_el = row.find("td", {"class": "team"}).find_next_sibling("td") # played
win_el = played_el.find_next_sibling("td") # win
draw_el = win_el.find_next_sibling("td") # draw
lost_el = draw_el.find_next_sibling("td") # lost
gf_el = lost_el.find_next_sibling("td") # gf
ga_el = gf_el.find_next_sibling("td") # ga
gd_el = ga_el.find_next_sibling("td") # gd
point_el = gd_el.find_next_sibling("td") # point
return {
"pos": pos_el.text,
"team": team_el.text,
"played": played_el.text,
"win": win_el.text,
"draw": draw_el.text,
"lost": lost_el.text,
"gf": gf_el.text,
"ga": ga_el.text,
"gd": gd_el.text,
"point": point_el.text,
}Pada fungsi di atas, kita mengambil data posisi klub pada klasemen, nama klub, jumlah bermain, jumlah menang hingga point saat ini. Selanjutnya setiap teks pada elemen terkait disimpan pada sebuah dictionary dan menjadi nilai balik dari fungsi.
Untuk mendapatkan data lengkap pada semua elemen dapat dilakukan secara iterasi pada variabel tr_list, dan pada setiap iterasi dilakukan ekstraksi data dan selanjutnya ditambahkan ke dalam dataframe klasemen yang sudah dibuat.
Python
# memanggil fungsi extract_data untuk setiap elemen pada tr_list klasemen_list = [extract_data(i) for i in tr_list] # membuat objek dataframe dari klasemen_list klasemen = pd.json_normalize(klasemen_list) klasemen
Output
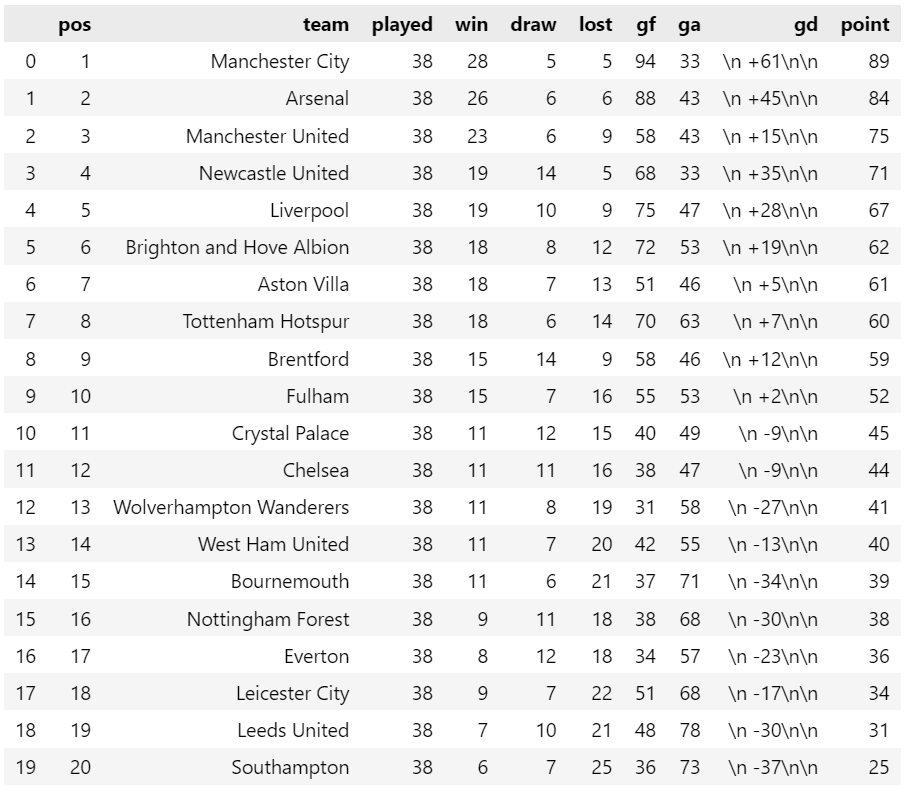
Jika kode tersebut dijalankan maka hasil yang diperoleh seperti gambar di bawah ini. Pada hasil tersebut, entah bagaimana isian pada kolom gd terdapat keanehan meskipun pada halaman htmlnya tidak ada yang aneh. Muncul tambahan karakter '\n' sebanyak 3 kali pada setiap isian kolom gd. Dapat pula merubah tipe data pada kolom yang berisi angka menjadi tipe numerik.
Untuk menanganinya dapat menggunakan sintaks berikut:
Python
klasemen['gd'] = klasemen['gd'].str.replace('\n', '')
klasemen['gd'] = klasemen['gd'].astype('int')
klasemenOutput
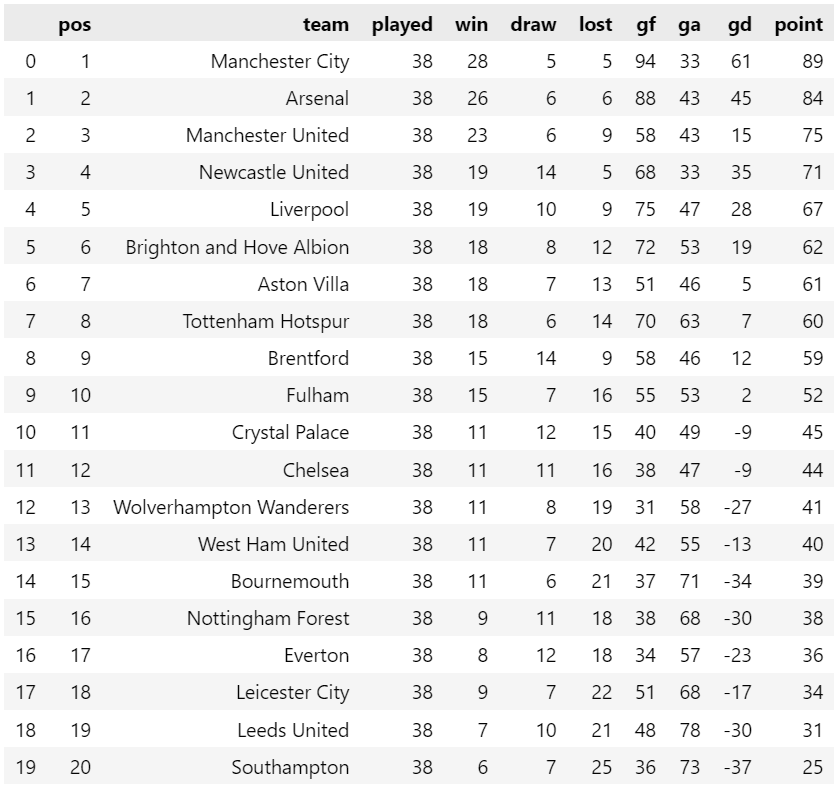
Selanjutnya gunakan kode berikut untuk menyimpan data dalam format csv.
Python
klasemen.to_csv('klasemen.csv', index=False)Pada tutorial ini , sudah dibahas bagaimana melakukan web scraping untuk mengambil data klasemen liga inggris dari situs www.premierleague.com. Silahkan mengkeksplorasi lebih jauh dengan menambahkan data lainnya (misal : status kemenangan pada 5 pertandingan terakhir dan lawan selanjutnya). Silahkan dicoba pula menerapkannya pada halaman web lainnya.
Selamat mencoba!
Dokumentasi: Beautiful Soup 4.4.0 documentation







