Python : Reformat Pandas Dataframe ‘Wide to Long’

Ketika mengambil data dari berbagai sumber seringkali kita mendapatkannya dalam format wide, misalkan data panel dimana informasi untuk setiap periode waktu muncul dalam bentuk kolom per kolom. Contoh lain yaitu data hasil tabulasi dimana umumnya dalam format wide.
Sementara itu Pengolahan data menggunakan bahasa pemrograman atau software tertentu, cenderung lebih mudah dan lebih umum menggunakan data dengan format long. Oleh karena itu, terkadang perlu dilakukan reformat atau reshape data yang berasal dari format wide tmenjadi format long. Terdapat beberapa cara yang dapat digunakan untuk melakukan hal ini, pada tulisan ini kita akan menggunakan method melt dan wide_to_long.
Metode melt
Secara umum sintaks untuk menggunakan metode melt adalah sebagai berikut:
Python
df = pd.melt(df, id_vars='indeks', value_vars=['col1', 'col2', ...])
Parameter id_vars berisi kolom yang menjadi identifier atau indeks, sementara untuk parameters value_vars berisi kolom-kolom yang akan diubah dari kolom-kolom yang berdiri sendiri menjadi satu kolom gabungan.
Selain dua parameter tersebut, terdapat dua parameter opsional yang sangat berguna, yaitu var_name dan value_name. Parameter var_name berisi nama kolom baru dari kolom-kolom hasil reformat. Sementara itu paramameter value_name merupakan nama dari kolom baru yang berisi nilai-nilai dari data.
Python
df = pd.melt(df, id_vars='indeks',
value_vars=['col1', 'col2', ...],
var_name='nama_kol_var',
value_name='nama_kolom_nilai')Ilustrasi
Misalkan kita memiliki data dalam format wide. Data contoh yang kita gunakan terdiri dari kolom nama berisi nama siswa. Selain itu terdapat kolom-kolom mata pelajaran Matematika, B. Indonesia, B. Inggris, dan Seni yang berisi skor ujian dari mata pelajaran terkait. Selanjutnya kita ingin mereformat data tersebut menjadi 3 kolom saja, yaitu kolom Nama dan kolom Mata_Pelajaran dan Skor_Ujian. Proses ini merupakan contoh dari reformat data wide menjadi long. Ilustasi yang lebih jelas terlihat pada gambar berikut ini:

Sintaks untuk membuat dataframe dengan format wide pada gambar di atas adalah sebagai berikut:
Python
import pandas as pd
# Membuat contoh dataframe dalam format wide
df_wide = pd.DataFrame({'Nama' : ['Andi', 'Budi', 'Candra', 'Dina'],
'Matematika' : [90, 70, 85, 69],
'B_Indonesia' : [76, 78, 94, 86],
'B_Inggris' : [72, 84, 88, 97],
'Kesenian' : [82, 90, 83, 89]})
# Menampilkan df_wide
df_wideOutput
# Output
Nama Matematika B_Indonesia B_Inggris Kesenian
0 Andi 90 76 72 82
1 Budi 70 78 84 90
2 Candra 85 94 88 83
3 Dina 69 86 97 89Berikutnya, sintaks untuk reformat dataframe wide menjadi long:
Python
# Reformat wide menjadi long
df_long = pd.melt(df_wide, id_vars='Nama',
value_vars=['Matematika', 'B_Indonesia',
'B_Inggris', 'Kesenian'],
var_name='Mata_Pelajaran',
value_name='Skor_Ujian')
# Menampilkan df_long
df_long
Output
# Output
Nama Mata_Pelajaran Skor_Ujian
0 Andi Matematika 90
1 Budi Matematika 70
2 Candra Matematika 85
3 Dina Matematika 69
4 Andi B_Indonesia 76
5 Budi B_Indonesia 78
... ... ... ...
14 Candra Kesenian 83
15 Dina Kesenian 89Metode wide_to_long
Metode melt memungkinkan kita melakukan reformat beberapa kolom menjadi 1 kolom baru dalam bentuk wide. Berikutnya terdapat metode wide_to_long di mana kita dapat melakukan reformat beberapa kolom long menjadi beberapa kelompok kolom wide sekaligus. Secara umum metode wide_to_long memiliki sintaks sebagai berikut:
Python
df_long = pd.wide_to_long(df, stubnames, i, j, sep='', suffix='\\d+')
Metode ini memiliki 6 parameter yaitu:
- df : yaitu dataframe dalam format wide
- stubnames : String atau List nama kolom untuk hasil reformat. Dimana dataframe wide yang kita gunakan memiliki nama-nama kolom yang diawali dengan stubnames ini
- i : kolom yang akan menjadi indeks.
- j : kolom yang akan menyimpan nilai dari suffix dari kolom-kolom dalam format wide.
- sep (opsional, default = “”): separator antara stubnames dan sub-nama dari kolom-kolom dalam format wide.
- suffix (opsional, default = “\\d+”) : reguler expression yang menunjukkan bentuk dari sub-nama. Nilai default-nya adalah numerik, jadi method ini mengharapkan bentuk sub-nama yang diberikan berupa angka numerik. Contoh lain adalah “.+” yang dapat digunakan ketika sub-nama mengandung karakter alfanumerik.
Untuk menggunakan method wide_to_long dengan tepat, hal yang perlu menjadi perhatian adalah nama-nama kolom pada dataframe dengan format wide, harus memiliki pola tertentu yang sama antar kolomnya.
Contoh berikut ini memberikan ilustrasi untuk permasalahan yang sedikit lebih kompleks. Mirip seperti data sebelumnya, namun selain dibagi berdasarkan jenis mata pelajaran juga dibagi berdasarkan semester (misal 1 dan 2). Secara total terdapat 11 kolom yaitu nama, 1matematika.sm1, matematika.sm2 dan seterusnya sampai kolom terakhir B_Ing.sm2.
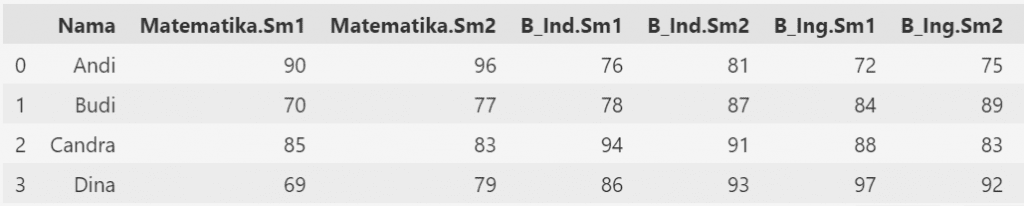
Dari format long tersebut akan dibuat menjadi wide dimana informasi mengenai semester akan muncul pada kolom sendiri. Sehingga dari jumlah kolom nilai yang sebelumnya ada 6 kolom ditransformasi menjadi 3 kolom nilai saja.
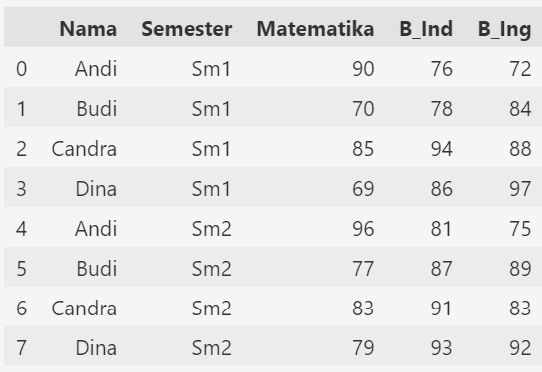
Berikut ini sintaks yang digunakan untuk melakukan reformat data menggunakan metode wide_to_long.
Python
# membuat contoh dataframe dalam format wide
df_wide = pd.DataFrame({'Nama' : ['Andi', 'Budi', 'Candra', 'Dina'],
'Matematika.Sm1' : [90, 70, 85, 69],
'Matematika.Sm2' : [96, 77, 83, 79],
'B_Ind.Sm1' : [76, 78, 94, 86],
'B_Ind.Sm2' : [81, 87, 91, 93],
'B_Ing.Sm1' : [72, 84, 88, 97],
'B_Ing.Sm2' : [75, 89, 83, 92]})
# Stubnames
m_pel = ['Matematika', 'B_Ind', 'B_Ing', 'Kesenian']
# Reformat df_wide menjadi long format
df_long = pd.wide_to_long(df_wide, m_pel,
i='Nama', j='Semester', sep='.', suffix='.+')
# Reset indeks untuk membuang indeks yang bertingkat
df_long.reset_index()Output
# Output
Nama Semester Matematika B_Ind B_Ing
0 Andi Sm1 90 76 72
1 Budi Sm1 70 78 84
2 Candra Sm1 85 94 88
3 Dina Sm1 69 86 97
4 Andi Sm2 96 81 75
5 Budi Sm2 77 87 89
6 Candra Sm2 83 91 83
7 Dina Sm2 79 93 92Pada contoh ini parameter stubnames kita buat menggunakan variabel m_pel. Dimana memiliki empat elemen yaitu Matematika, B_Ind, B_Ing, Kesenian. Keempat elemen tersebut sesuai dengan nama awal pada kolom-kolom dataframe dengan format wide.
Kolom Nama menjadi indeks dan diikuti kolom sub-nama yaitu Semester. Kolom Semester akan berisi nilai Sm1 atau Sm2.
Untuk parameter sep kita isi dengan “.”. Karena nama-nama kolom yang ada (contoh : Matematika.Sm1) mengikuti bentuk {stubnames}.{sub-nama} dan dipisahkan dengan simbol “.”.
Untuk parameter suffix kita gunakan ".+" karena sub-nama (Sm1 dan Sm2) berisi karakter alfanumerik.
Pada kondisi lain, misalkan bentuk dataframe yang diinginkan berbeda dari yang telah dihasilkan seperti contoh di atas. Dimana Sm1 dan Sm2 menjadi dua kolom terpisah, sedangkan untuk keempat mata pelajaran menjadi 1 kolom tersendiri misal Mata_pelajaran. Untuk membuat format seperti itu, maka hal pertama yang perlu dilakukan adalah merubah nama-nama kolom pada dataframe wide menjadi pola yang sesuai. Misalnya Sm1.Matematika, Sm2.Matematika dan seterusnya.
Catatan : Dokumentasi untuk metode melt dan wide_to_long dapat dilihat di sini dan sini.







