Mengelola Dataframe (vanilla R vs Paket dplyr)

Mengelola dataframe pada R bukanlah suatu hal yang rumit untuk dilakukan, kita dapat menambah kolom, filter data, seleksi kolom, agregasi data dan lain sebagainya dengan relatif mudah. Proses tersebut menjadi semakin mudah dengan memanfaatkan fungsi-fungsi pada package dplyr. Selain memberikan kemudahan dalam pengelolaan dataframe, penggunaan package ini juga memberikan gaya penulisan kode yang elegan dan mudah dipahami. Terlebih dengan memanfaatkan pipe operator, proses manipulasi dataframe yang kompleks akan menjadi jauh lebih sederhana.
Dalam tulisan ini, data yang kita gunakan gunakan adalah data Auto yang terdapat pada package ISLR. Dataframe Auto terdiri dari 9 features/kolom dan 392 objek. Untuk menggunakannya silahkan instal terlebih dahulu package ISLR tersebut.
R
library(dplyr)
library(ISLR)
# Mengambil dataframe Auto dari package ISLR
data("Auto",package="ISLR")
# Melihat struktur data Auto
str(Auto)Output
'data.frame': 392 obs. of 9 variables:
$ mpg : num 18 15 18 16 17 15 14 14 14 ...
$ cylinders : num 8 8 8 8 8 8 8 8 8 8 ...
$ displacement: num 307 350 318 304 302 429 454 ...
$ horsepower : num 130 165 150 150 140 198 220 ...
$ weight : num 3504 3693 3436 3433 3449 ...
$ acceleration: num 12 11.5 11 12 10.5 10 9 8.5 10 8.5 ...
$ year : num 70 70 70 70 70 70 70 70 70 70 ...
$ origin : num 1 1 1 1 1 1 1 1 1 1 ...
$ name : Factor w/ 304 levels "amc ambassador brougham",..:
49 36 231 14 161 141 54 223 241 2 ...Filter Baris Dataframe
Fungsi pertama yang akan kita bahas adalah filtering data. Filtering data bertujuan untuk membatasi objek yang kita amati berdasarkan kriteria-kriteria tertentu. Filtering dataframe melalui package dplyr dilakukan menggunakan fungsi filter. Berikut ini ilustrasi melakukan filter dataframe dalam bahasa R.
Filter data yang memiliki mpg > 30:
R
# Tanpa package tambahan Auto[Auto['mpg'] > 30,] # dplyr filter(Auto, mpg > 30)
Output
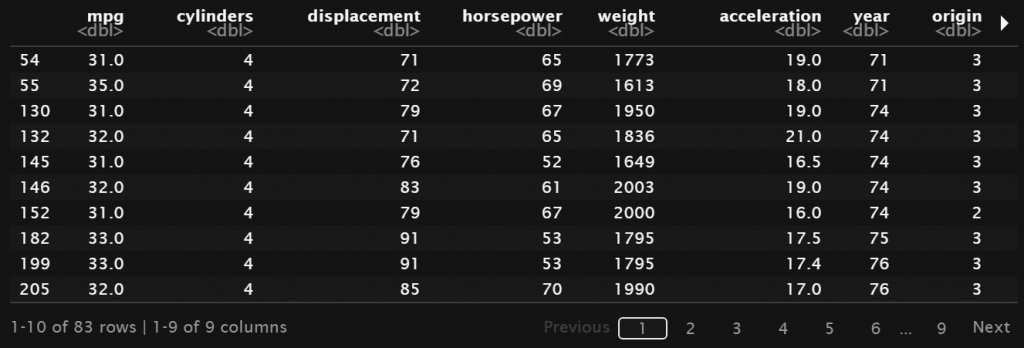
Filter data dengan mpg > 30 dan origin = 1 (America):
R
# Tanpa package tambahan Auto[Auto['mpg'] > 30 & Auto['origin'] == 1,] # dplyr filter(Auto, mpg > 30, origin == 1)
Jika filter yang diperlukan cukup banyak maka dapat dibuat variabel terlebih dahulu untuk mendefinisikan kriteria filter-nya. Pada contoh di bawah ini misalkan kita melakukan filtering menurut 3 kriteria, yaitu mpg > 30, origin = 1 (America) dan year antara tahun 70 – 80.
R
# Tanpa package tambahan
## membuat variabel filt yang menampung kriteria filter
filt <- Auto$mpg > 30 &
Auto$origin == 1 &
sapply(Auto$year, between, left=70, right=80)
## filter data Auto berdasarkan variabel filt
Auto[filt, ]
# dplyr
filter(Auto, mpg > 30, origin == 1, between(year, 70, 80))Tanpa menggunakan fungsi filter terlihat bahwa semakin banyak kriteria maka semakin kompleks sintaks yang diperlukan. Sementara itu dengan memanfaatkan fungsi filter sintaks yang ada lebih sederhana.
Seleksi Kolom Dataframe
Selain melakukan filtering pada objek, kita juga dapat melakukan seleksi pada features/kolom tertentu. Seleksi seperti ini merupakan bagian penyederhanaan data dengan mengambil kolom-kolom yang diperlukan saja.
Tanpa menggunakan package tambahan apapun, terdapat banyak cara untuk melakukan seleksi kolom pada dataframe. Yang paling sederhana adalah dengan mengakses indeks/nama kolom yang bersesuaian. Sementara itu, pada package dplyr terdapat fungsi select yang berguna untuk menyeleksi kolom dataframe.
Berikut contoh sintaks untuk melakukan seleksi terhadap kolom mpg, cylinders, horsepower dan origin.
R
# Tanpa package tambahan
Auto[, c(1, 2, 4, 8)]
# atau
Auto[, c('mpg', 'cylinders', 'horsepower', 'origin')]
# dplyr
select(Auto, mpg, cylinders, horsepower, origin)Output
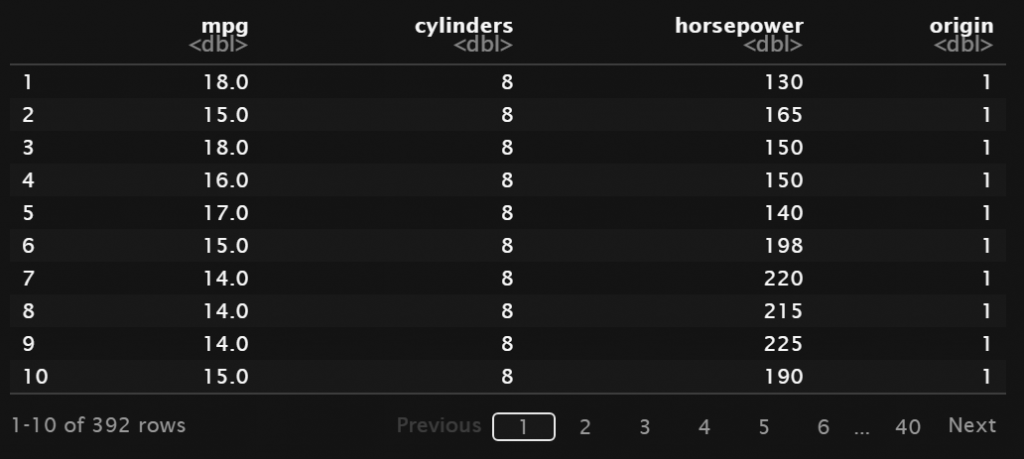
Pada sintaks di atas, urutan kolom yang diperoleh sama dengan urutan dari vektor kolom yang diberikan. Hal ini berarti pada saat yang sama, ketika melakukan seleksi kolom dapat menentukan urutan kolom sesuai yang diinginkan.
Sort/Mengurutkan Dataframe
Pekerjaan yang juga sering dilakukan terhadap dataframe adalah mengurutkan data. Data dapat diurutkan berdasarkan kolom-kolom tertentu baik secara menaik/ascending maupun menurun/descending. Selain itu, jika terdapat data hilang (null, NA dan sebagainya) juga dapat diatur apakah akan diletakkan di awal atau akhir.
Untuk ilustrasi kita akan menggunakan dataframe data dari contoh sebelumnya agar kolom yang ditampilkan tidak terlalu banyak.
Misalkan kita ingin mengurutkan data berdasarkan nilai mpg dari yang dari yang terkecil ke terbesar (ascending) serta nilai horsepower dari yang terbesar ke terkecil (descending).
Mengurutkan data tanpa package tambahan dapat menggunakan fungsi order. Secara default fungsi order akan mengurutkan secara ascending. Jika ingin pengurutan secara descending perlu ditambahkan tanda minus “-” sebelum nama kolom.
Sementara itu, pada package dplyr kita dapat mengurutkan data menggunakan fungsi arrange. Untuk mengurutkan secara descending, nama kolom perlu dimasukkan ke dalam fungsi desc terlebih dahulu.
Berikut ini contoh sintaks untuk mengurutkan dataframe:
R
data <- select(Auto, mpg, cylinders, horsepower, origin) # Sorting data ## tanpa package tambahan data[order(data$mpg, -data$horsepower),] ## dplyr arrange(data, mpg, desc(horsepower))
Output
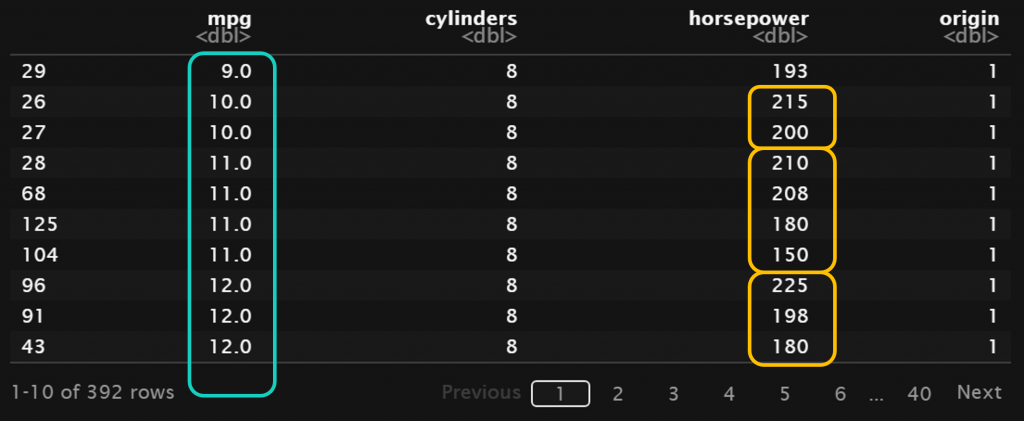
Sesuai dengan yang diharapkan, dataframe diurutkan berdasarkan mpg secara ascending dan selanjutnya diurutkan berdasarkan horsepower secara descending. Yang perlu diperhatikan, urutan dari kolom yang akan diurutkan akan memengaruhi hasil akhir. Sebagai contoh, pengurutan berdasarkan horsepower terlebih dahulu diikuti dengan nilai mpg akan memberikan output yang berbeda.
Mencari Nilai Unik pada Kolom
Salah satu hal yang juga seringkali diperlukan ketika mengolah dataframe adalah melihat variasi nilai dari suatu kolom. Khususnya pada kolom-kolom kategorik, maka kita tertarik untuk melihat kategori apa saja yang ada. Misalkan dari data Auto ini, kita mungkin saja tertarik untuk melihat berapa saja jumlah cylinders yang ada. Atau nilai berapa saja yang ada pada kolom origin, dan lain sebagainya.
Untuk mendapat nilai unik pada sebuah kolom dapat menggunakan fungsi unique. Output yang diberikan berupa vector yang berisi semua nilai unik dari kolom tersebut. Pada package dplyr, fungsi distinct dapat melakukan hal yang sama. Namun, tidak seperti fungsi unique fungsi distinct akan mengembalikan nilai dalam bentuk dataframe.
Mencari nilai unik dari kolom cylinders:
R
# Tanpa package tambahan unique(Auto$cylinders) # dplyr distinct(Auto, cylinders)
Output
# Output
[1] 8 4 6 3 5
# Output
cylinders
1 8
15 4
16 6
72 3
275 5Dari sintaks di atas kita mendapat informasi bahwa nilai pada kolom cylinders adalah antara 3-8. Lebih jauh, juga dapat melihat frekuensi untuk masing-masing jumlah cylinders dengan menggunakan fungsi table.
R
table(Auto$cylinders) # Output 3 4 5 6 8 4 199 3 83 103
Merubah Nama Kolom
Untuk merubah nama kolom pada suatu dataframe dapat dilakukan menggunakan sintaks berikut ini:
R
# Contoh dataframe
data <- select(Auto, mpg, cylinders, horsepower, origin)
## Merubah semua nama kolom
colnames(data) <- c("m_p_g", "silinder", 'hp', 'asal')
str(data)Output
'data.frame': 392 obs. of 4 variables: $ m_p_g : num 18 15 18 16 17 15 14 ... $ cylinders : num 8 8 8 8 8 8 8 8 8 8 ... $ horsepower: num 130 165 150 150 140 198 ... $ origin : num 1 1 1 1 1 1 1 1 1 1 ...
Merubah nama hanya pada beberapa kolom:
R
# Contoh dataframe
data <- select(Auto, mpg, cylinders, horsepower, origin)
# Merubah semua nama kolom
colnames(data)[c(2, 4)] <- c("silinder", 'asal')
str(data)Output
'data.frame': 392 obs. of 4 variables: $ mpg : num 18 15 18 16 17 15 14 14 14 ... $ silinder : num 8 8 8 8 8 8 8 8 8 8 ... $ horsepower: num 130 165 150 150 140 198 220 ... $ asal : num 1 1 1 1 1 1 1 1 1 1 ...
Menggunakan package dplyr:
R
# Contoh dataframe
data <- select(Auto, mpg, cylinders, horsepower, origin)
## Merubah nama semua kolom
data <- rename(data, m_p_g=mpg, silinder = cylinders,
hp = horsepower, asal = orig)
str(data)Output
'data.frame': 392 obs. of 4 variables: $ m_p_g : num 18 15 18 16 17 15 14 14 ... $ silinder: num 8 8 8 8 8 8 8 8 8 8 ... $ hp : num 130 165 150 150 140 198 ... $ asal : num 1 1 1 1 1 1 1 1 1 1 ...
Saat menggunakan fungsi rename, yang perlu diperhatikan adalah nama baru yang diinginkan diletakkan disebelah kiri tanda “=”, sementara nama lama di sebelah kanan tanda “=”. Selain itu, untuk menyimpan pergantian nama kolom tersebut kita perlu menyimpan hasil fungsi rename ke suatu variabel. Dalam contoh di atas kita simpan kembali pada variabel data.
Dengan cara yang sama kita dapat merubah nama untuk beberapa kolom saja.
R
# Contoh dataframe data <- select(Auto, mpg, cylinders, horsepower, origin) ## Merubah nama beberapa kolom data <- rename(data, silinder = cylinders, asal = original) str(data)
Output
'data.frame': 392 obs. of 4 variables: $ mpg : num 18 15 18 16 17 15 14 14 ... $ silinder : num 8 8 8 8 8 8 8 8 8 8 ... $ horsepower: num 130 165 150 150 140 198 ... $ asal : num 1 1 1 1 1 1 1 1 1 1 ...
Menambah Kolom Baru
Untuk menambah kolom baru pada dataframe juga dapat dilakukan dengan mudah . Cukup memberikan nilai secara langsung pada kolom tersebut.
Pada package dplyr terdapat fungsi mutate yang berguna untu membuat kolom baru.
Misalkan pada dataframe data akan ditambahkan kolom baru dengan nama kpg atau kilometer per galon. Kolom tersebut dihitung berdasarkan nilai pada lainnya. Sebagai contoh menggunakan nilai dari kolom mpg dan mengalikannya dengan 1,60934 untuk menghitung nilai pada kolom kpg.
Berikut sintaks dasarnya tanpa menggunakan package tambahan:
R
data <- select(Auto, mpg, cylinders, horsepower, origin) # Menambah kolom baru tanpa package tambahan data['kpg'] = 1.60934 * data['mpg'] # atau data$kpg = 1.60934 * data$mpg data
Sintaks menggunakan fungsi mutate pada package dplyr:
R
data <- select(Auto, mpg, cylinders, horsepower, origin) # Menambah kolom baru dengan dplyr data <- mutate(data, kpg = 1.60934 * mpg) data
Output
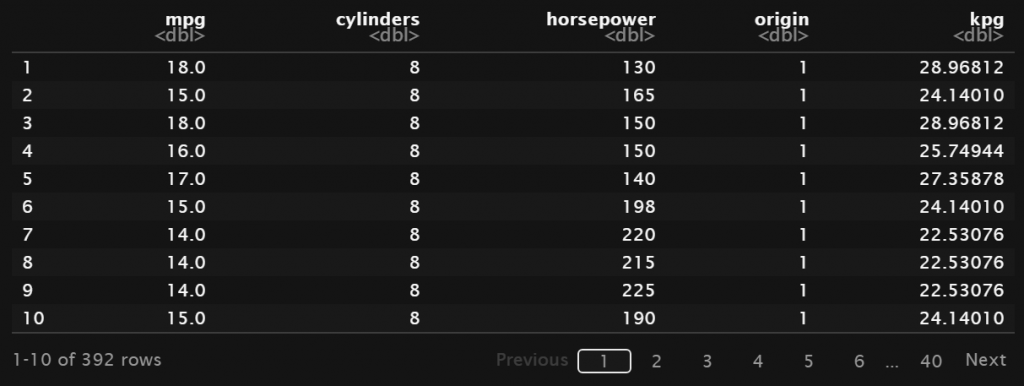
Pada fungsi mutate penambahan beberapa kolom sekaligus dapat dilakukan seperti contoh berikut:
R
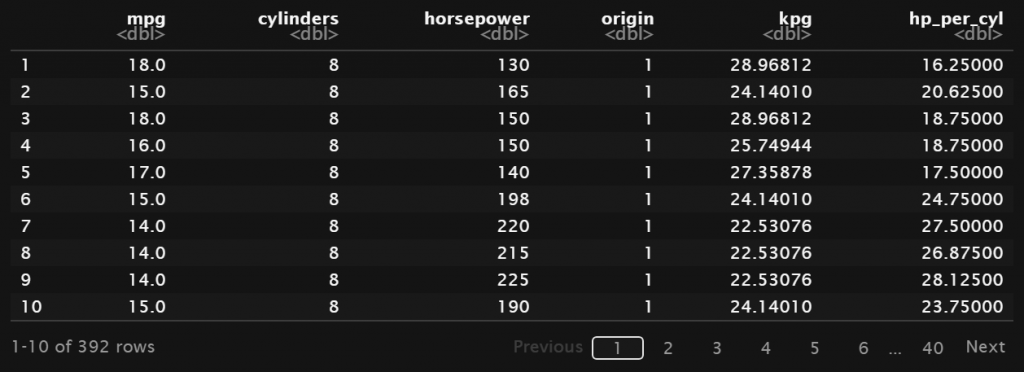
data <- select(Auto, mpg, cylinders, horsepower, origin) # Menambah kolom baru dengan dplyr : mutate # fungsi mutate disimpan kembali pada variabel data data <- mutate(data, kpg = 1.60934*mpg, hp_per_cyl = horsepower/cylinders) data
Output
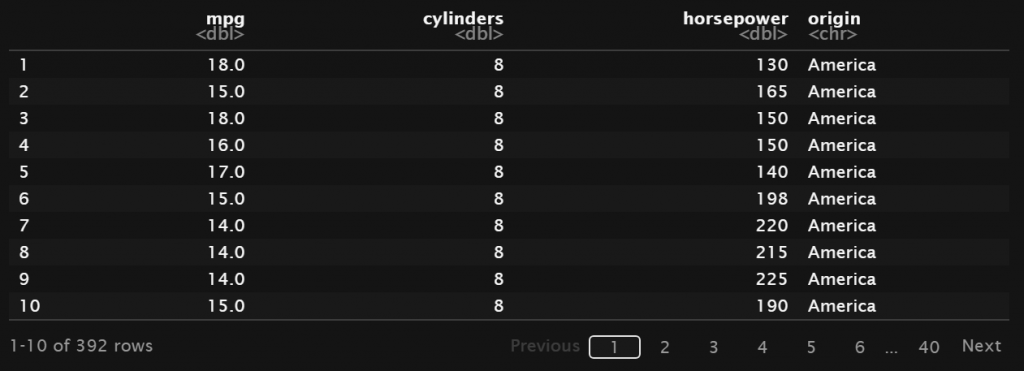
Selain untuk menambahkan kolom baru, dengan cara yang sama kita bisa mengganti isian dari kolom yang ada dengan nilai yang baru. Sebagai contoh untuk kolom origin, kita akan merubah isian dari nilai 1, 2 dan 3 menjadi America, Europe dan Japan.
R
data <- select(Auto, mpg, cylinders, horsepower, origin)
# Mengganti isian pada kolom origin
data$origin = ifelse(data$origin==1, "America",
ifelse(data$origin==2, "Eurpe", "Japan"))
dataAtau, jika menggunakan fungsi mutate:
R
data <- select(Auto, mpg, cylinders, horsepower, origin)
# Menambah kolom baru dengan dplyr : mutate
# fungsi mutate disimpan kembali pada variabel data
data <- mutate(data,
origin = ifelse(origin==1, "America",
ifelse(origin==2, "Eurpe", "Japan"))
dataOutput
Agregasi/Summary Data
Salah satu hal penting dalam mengolah data pada dataframe adalah melakukan agregasi data. Agregasi data dapat berupa nilai rata-rata, nilai maksimum dan minimum, total dan sebagainya berdasarkan kriteria tertentu. Misalnya kita ingin mengetahui rata-rata besaran mpg untuk masing-masing origin.
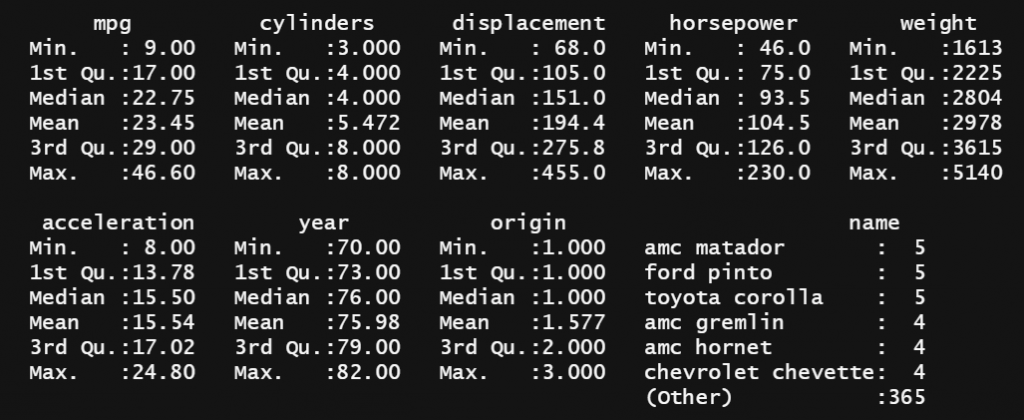
Tidak ada cara yang sederhana atau langsung untuk melakukan hal tersebut tanpa menggunakan package tambahan. Fungsi yang paling mendekati adalah describe. Fungsi ini memberikan nilai statistik 5 serangkai (minimum, maksimum, kuartil 1 dan 3, median serta mean) untuk setiap kolom numerik dan menampilkan frekuensi data pada kolom non-numerik.
R
# Summary untuk semua kolom numerik
summary(Auto)
# Summary kolom tertentu
summary(Auto[c('mpg', 'year')])Output
Proses pengelompokan dan aggregasi data dapat dilakukan menggunakan kombinasi fungsi group_by dan fungsi summarise. Fungsi group_by digunakan untuk mengelompokkan data berdasarkan kriteria tertentu dan summarise berperan untuk menentukan fungsi yang pengelompokan apa yang digunakan (misalkan rata-rata, total, median, dan sebagainya).
untuk menggunakan fungsi group_by dan summarise secara bersamaan perlu memahami terlebih dahulu tentang pipe operator (%>%). Pipe operator memungkinkan kita melakukan serangkaian operasi pada dataframe secara berurutan dan tetap terstruktur dengan baik.
Sintaks umumnya adalah sebagai berikut:
dataframe %>%
fungsi_1 %>%
fungsi_2 %>% ...Dengan menggunakan format pipe operator seperti di atas, kita dapat mengombinasikan berbagai fungsi yang sudah dibahas sebelumnya.
Berikut sintaks untuk mendapatkan nilai rata-rata kolom mpg berdasarkan origin menggunakan group_by dan summarise:
R
agg <- Auto %>%
group_by(origin) %>%
summarise(avg_mpg = mean(mpg))
aggOutput

Kita juga dapat menentukan beberapa kriteria sekaligus baik untuk group_by maupun summarise, seperti contoh berikut:
R
Auto %>%
group_by(origin, cylinders) %>%
summarise(avg_mpg = mean(mpg),
num_type = n(),
min_hp = min(horsepower),
max_hp = max(horsepower))Output
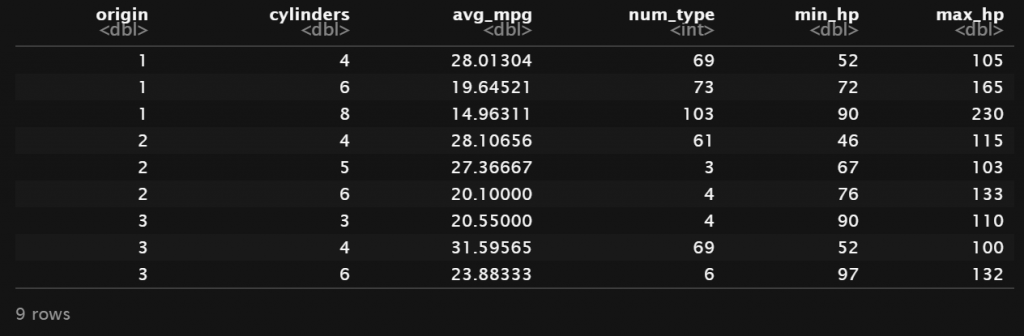
Pada contoh ini, kita mengelompokkan data berdasarkan kolom origin dan jumlah cylinder. Selanjutnya untuk setiap kelompok diperoleh informasi nilai rata-rata mpg (avg_mpg), jumlah objek dari masing-masing kelompok (num_type) serta minimum dan maksimum horsepower pada setiap kelompok. Tabel tersebut memberikan lebih banyak informasi mengenai karakteristik dari tiap kelompok yang menjadi perhatian.
Pipe Operator
Seperti yang telah sedikit di bahas pada bagian sebelumnya, penggunaan pipe operator akan memberi kemudahan saat melakukan serangkaian operasi pada dataframe yang saling berkaitan dan berurutan.
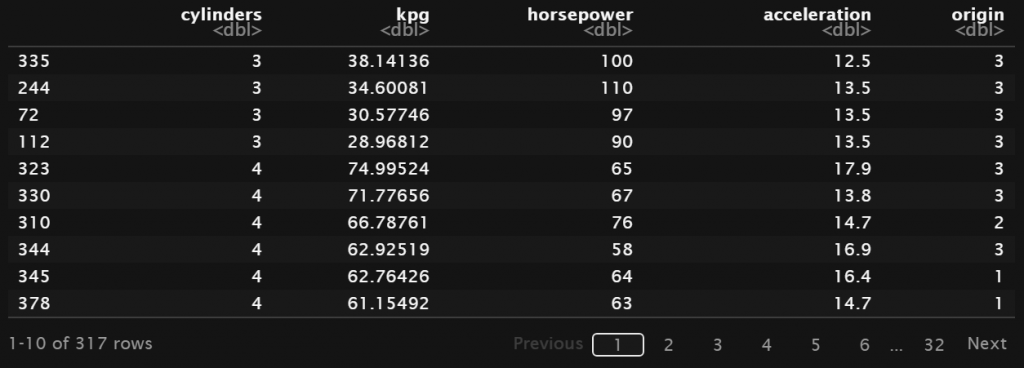
Misalkan dari dataframe Auto kita ingin melakukan operasi sebagai berikut:
- Seleksi data kendaraan yang memiliki akselerasi kurang dari 18
- Selanjutnya menambah kolom
kpgyang berisi informasi kilometer per gallon. - Hasilnya kemudian diurutkan secara ascending berdasarkan jumlah
cylinders, kemudian diurutkan secara descending berdasarkankpg - Selanjutnya mengambil kolom-kolom
cylinders,kpg,horsepower,accelerationdanorigin
Untuk melakukan serangkaian operasi tersebut, kita dapat menggunakan fungsi-fungsi yang telah dibahas sebelumnya satu per satu secara terpisah. Atau dengan menggunakan pipe operator dimana sintaks yang digunakan lebih elegan.
Saat menggunakan pipe operator, dataframe yang digunakan kita letakkan paling awal. Ketika memanggil fungsi-fungsi lainnya, tidak perlu lagi menambahkan parameter dataframe-nya. Seperti contoh di bawah ini, kita menggunakan sintaks filter(acceleration < 18) bukan filter(Auto, acceleration < 18).
R
my_data <- Auto %>%
filter(acceleration < 18) %>%
mutate(kpg = 1.60934*mpg) %>%
arrange(cylinders, desc(kpg)) %>%
select(cylinders, kpg, horsepower,
acceleration, origin)
my_dataOutput
Selain fungsi-fungsi yang sudah dibahas, terdapat beberapa fungsi lain pada package dplyr yang dapat dimanfaatkan untuk mengelola dataframe. Dokumentasi lengkap dapat dilihat pada tautan ini.







