Random Forest untuk Model Klasifikasi Menggunakan Scikit-Learn

Sekilas Random Forest
Random Forest adalah model ensemble berbasis pohon yang populer pada machine learning. Model ini diperkenalkan oleh Leo Breiman pada Tahun 2001. Random Forest dapat diterapkan pada pemodelan regresi maupun klasifikasi. Pada model random forest untuk regresi prediksi dihitung berdasarkan nilai rata-rata (averaging) dari output setiap decision tree (pohon keputusan). Sedangkan untuk model klasifikasi, prediksi ditentukan menggunakan suara terbanyak (majority vote). Contohnya, model Random Forest dengan 100 pohon, 72 pohon memprediksi data tertentu sebagai kelas A dan 28 pohon memprediksi masuk kelas B, maka data tersebut akan dipredksi sebagai kelas A.
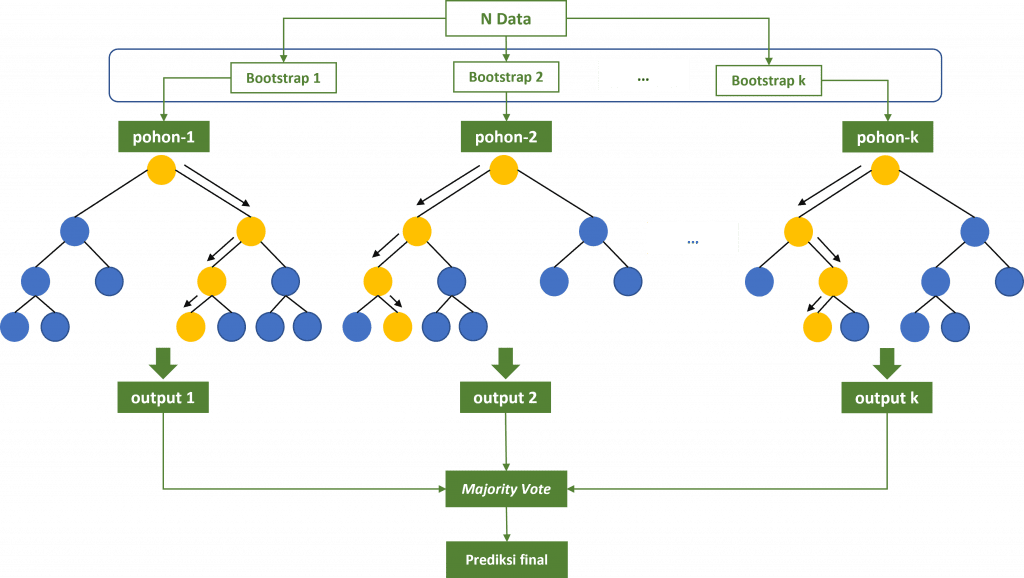
Model Random Forest menggunakan metode bootstrap dalam proses pembentukan setiap pohon. Artinya, dataset yang digunakan oleh setiap pohon bukanlah dataset yang sama, melainkan hasil bootstrap. Splitting node pada Random Forest hanya menggunakan sebagian features saja tidak seperti model bagging. Jumlah yang biasa dipakai yaitu $\sqrt{p}$ atau $log_2{~p}$, dimana p adalah banyaknya features pada dataset. Kedua hal ini, meningkatkan keacakan pada setiap pohon serta independensi antar pohon menjadi semakin tinggi. Breiman menunjukkan bahwa hasil Random Forest kompetitif dibandingkan boosting dan adaptive bagging serta mampu mereduksi bias khususnya pada pemodelan klasifikasi.
Lihat: Random Forest untuk Model Regresi
Random Forest untuk Klasifikasi
Dataset yang akan digunakan pada contoh ini adalah data wine quality dengan peubah target multikelas (3 kelas) yaitu HIGH, STANDARD dan LOW. Dataset ini sudah dalam kondisi ‘clean’ sehingga tulisan ini akan fokus bagaimana mencari model random forest terbaik.
Analisis Deskriptif
Python
import pandas as pd
import numpy as np
data = pd.read_csv('https://raw.githubusercontent.com/sainsdataid/dataset/main/wine-quality-multiclass.csv')
data.info()Output
# Output <class 'pandas.core.frame.DataFrame'> RangeIndex: 1143 entries, 0 to 1142 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fixed acidity 1143 non-null float64 1 volatile acidity 1143 non-null float64 2 citric acid 1143 non-null float64 3 residual sugar 1143 non-null float64 4 chlorides 1143 non-null float64 5 free sulfur dioxide 1143 non-null float64 6 total sulfur dioxide 1143 non-null float64 7 density 1143 non-null float64 8 pH 1143 non-null float64 9 sulphates 1143 non-null float64 10 alcohol 1143 non-null float64 11 quality 1143 non-null object dtypes: float64(11), object(1) memory usage: 107.3+ KB
Dataset ini terdiri dari 1143 observasi. Terdapat 10 peubah prediktor dan seluruhnya bertipe numerik. Kolom quality merupakan peubah respon dan berisi nilai HIGH, STANDARD atau LOW yang mengindikasikan kualitas wine tersebut.
Python
# menghitung jumlah data menurut kelas grup = data["quality"].value_counts() print(grup) # menghitung proporsi setiap kelas grup_prop = grup / len(data)*100 print(grup_prop)
Output
# Output quality HIGH 159 LOW 522 STANDARD 462 quality HIGH 13.910761 LOW 45.669291 STANDARD 40.419948
Dari total 1143 data, 522 data atau sekitar 45,7% memiliki label LOW , sementara untuk label STANDARD terdiri dari 462 data atau sekitar 45,7% sisanya 159 (13,9%) memiliki label HIGH. Dari hasil ini terlihat terdapat kondisi yang tidak begitu seimbang khususnya pada kelas HIGH. Hal ini kemungkinan akan mempengaruhi kinerja model khususnya dalam memprediksi data yang seharusnya masuk kelas HIGH tersebut.
Selanjutnya kita menampilkan beberapa statistik deskriptif dari dataset ini:
Python
summary = data.groupby('quality').mean().transpose()
print(summary)Output
quality HIGH LOW STANDARD fixed acidity 8.846541 8.142146 8.317749 volatile acidity 0.395314 0.596121 0.504957 citric acid 0.391195 0.235096 0.263680 residual sugar 2.748428 2.543582 2.444805 chlorides 0.074711 0.092117 0.085281 free sulfur dioxide 14.188679 16.404215 15.215368 total sulfur dioxide 36.672956 54.016284 39.941558 density 0.996019 0.997054 0.996610 pH 3.282453 3.308410 3.323788 sulphates 0.745849 0.614195 0.676537 alcohol 11.528407 9.922510 10.655339
Kita juga dapat melihat bagaimana karakteristik masing-masing kelas berdasarkan nilai fitur-fiturnya. Misalkan rata-rata kadar alcohol pada kelas HIGH terlihat lebih tinggi dibandingkan kelas STANDARD dan LOW. Sebaliknya rata-rata kadar total.sulfur.dioxide pada kelas HIGH jauh lebih rendah dibandingkan dua kelas lainnya. Contoh lainnya pada pH terlihat ketiga kelas hampir tidak memiliki perbedaan. Artinya kemungkinan fitur ini tidak memiliki kontribusi besar untuk membedakan ketiga kelas.
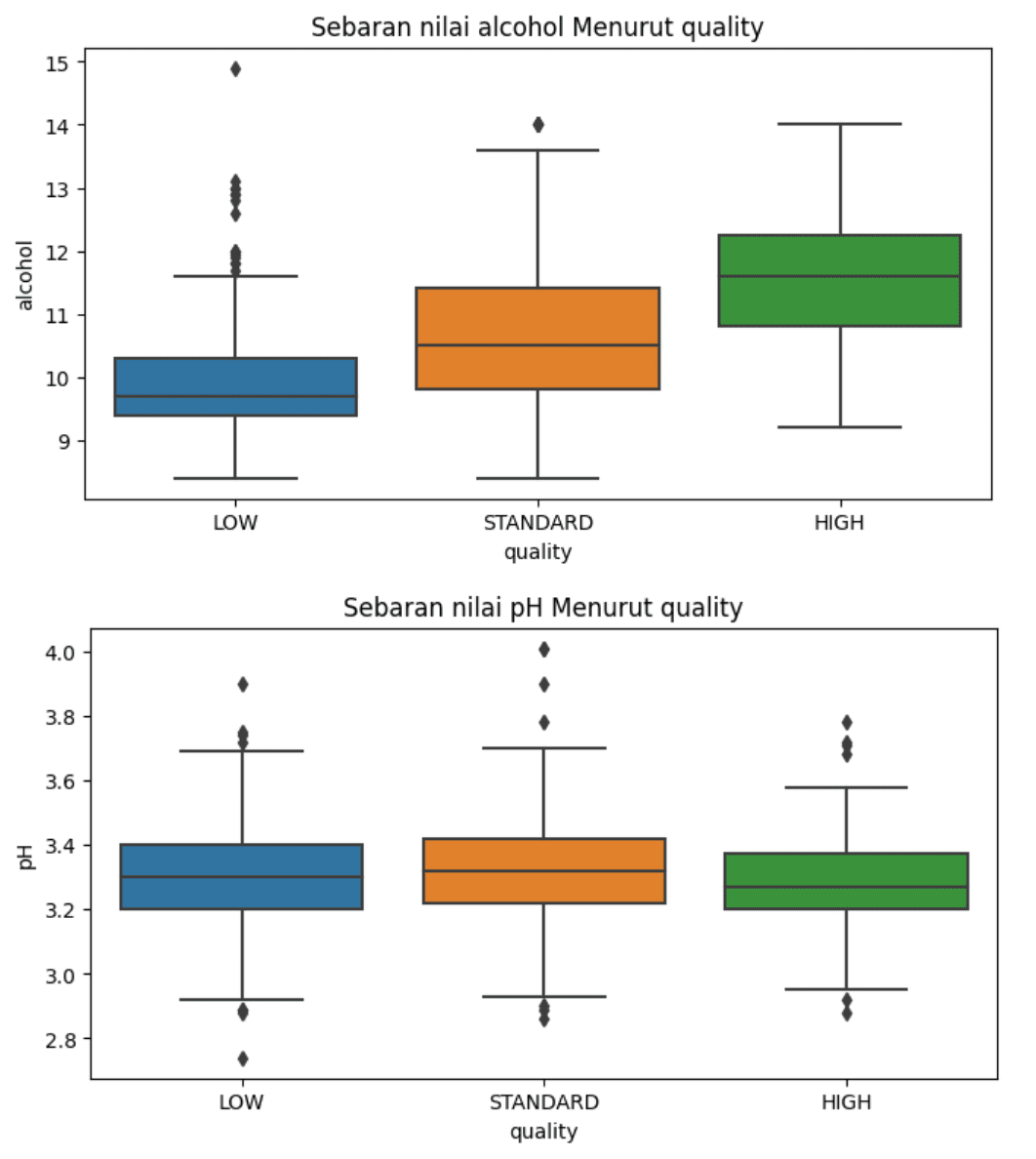
Jika diperlukan, dapat pula dibuat plot sebarannya untuk masing-masing kelas untuk melihat perbandingan secara visual. Misalkan pada contoh di bawah ini kita menyajikan boxplot untuk sebaran nilai alcohol dan pH menurut kelasnya. Dari visualisasi tersebut terlihat bahwa cenderung terdapat perbedaan nilai alcohol dimana nilai pada kelas HIGH relatif lebih tinggi dibandingkaan kelas STANDARD, begitu juga untuk kelas LOW dimana nilainya relatif lebih rendah dibandingkan kelas lainnya. Sementara itu, pada boxplot nilai pH sebaran nilainya terlihat tidak terlalu berbeda antar ketiga kelas, hal ini bisa menjadi indikasi kemungkinan fitur ini tidak memiliki pengaruh yang besar dalam menentukan kelas data.
Python
import matplotlib.pyplot as plt
import seaborn as sns
# Membuat plot boxplot untuk kolom alcohol
plt.figure(figsize=(8, 4))
sns.boxplot(x='quality', y='alcohol', hue='quality', data=data)
plt.title('Sebaran nilai alcohol Menurut quality')
plt.show()
# Membuat plot boxplot untuk kolom pH
plt.figure(figsize=(8, 4))
sns.boxplot(x='quality', y='pH', hue='quality', data=data)
plt.title('Sebaran nilai pH Menurut quality')
plt.show()Output
Pembagian Data Latih dan Data Uji
Pembagian data latih dan uji penting dalam pemodelan machine learning. Data latih digunakan untuk proses training sebagai dasar pembentukan model. Selanjutnya, data uji digunakan untuk mengevaluasi model. Penggunaan data uji diperlukan agar model dapat evaluasi pada data yang belum pernah dilihat sebelumnya.
Fungsi train_test_split pada modul sklearn.model_selection dapat digunakan untuk pembagian data. Pada contoh ini akan digunakan proporsi 70% data latih dan 30% data uji. Pembagian dilakukan secara acak dan proporsional (stratified random sampling), untuk menjaga keterwakilan kedua kelas quality pada data latih dan uji.
Python
from sklearn.model_selection import train_test_split
X = data.drop('quality', axis=1)
y = data['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3,
stratify=y, random_state=100)Dari ahsil pembagian data, proporsi masing-masing kelas pada data latih dan data uji relatif sama, yaitu pada kisaran 46%, 40% dan 14%. Hal ini cukup penting agar seluruh kelas memiliki representasi yang memadai baik pada data latih maupun data uji.
Python
# Data latih
grup_train = y_train.groupby(y_train).count() / len(y_train) * 100
grup_test = y_test.groupby(y_test).count() / len(y_test) * 100
print(f"\nProp Data latih:\n{grup_train}")
print(f"\nProp Data Uji:\n{grup_test}")Output
# Output Prop Data latih: quality HIGH 13.875 LOW 45.625 STANDARD 40.500 Name: quality, dtype: float64 Prop Data Uji: quality HIGH 13.994169 LOW 45.772595 STANDARD 40.233236 Name: quality, dtype: float64
Membuat Model
Untuk membuat model Random Forest kita akan menggunakan fungsi RandomForestClassifier dari modul sklearn.ensemble. Beberapa parameter penting pada model yaitu:
n_estimators: jumlah pohon yang akan digunakan (default = 100)criterion: {“gini”, “entropy”, “log_loss”}, default=”gini”. Parameter ini digunakan untuk menentukan kriteria untuk memperoleh splitting terbaik pada setiap node.max_depth, default=None. Maksimal kedalaman pada setiap pohon.Nonemenunjukkan kedalaman pohon tidak dibatasi (dibatasi menurut kriteria paramater lainnya sepertimin_samples_splitdanmin_samples_leaf.min_samples_split, default=2. Minimal jumlah data pada suatu node agar node tersebut bisa di-split.min_samples_leaf, default=1. Minimal jumlah data pada masing-masingleafagar suatu node bisa di-split.max_features: {“sqrt”, “log2”, None}, default=”sqrt”. Maksimal jumlah features yang digunakan dalam proses penentuan split terbaik pada setiap node.- dll
Pada bagian ini kita gunakan nilai parameter n_estimators=200, min_samples_split=5 dan class_weight="balanced". Nilai "balanced" pada parameter class_weight akan meningkatkan bobot kelas minoritas dan mengurangi bobot kelas mayoritas dalam menghitung prediksi. Penentuan class_weight bermanfaat pada kondisi kelas tidak seimbang sehingga hasil prediksi menjadi lebih baik khususnya bagi kelas minoritas.
Nilai random_state dapat ditentukan berapa saja. Parameter ini ditetapkan dengan nilai tertentu agar proses pelatihan model dapat di-reproduce dan memperoleh hasil yang sama walaupun dijalankan berulang kali atau dieksekusi pada perangkat yang berbeda.
Python
from sklearn.ensemble import RandomForestClassifier
model_rf = RandomForestClassifier(n_estimators=200,
min_samples_split=5,
class_weight="balanced",
random_state=100)
# fitting model
model_rf.fit(X_train, y_train)
# Memprediksi output dari data uji
y_pred = model_rf.predict(X_test)
print(y_pred)Output
# Output
array(['LOW', 'LOW', 'STANDARD', 'LOW', ..., 'LOW', 'LOW', 'HIGH'],
dtype=object)Setelah memperoleh model Random Forest, langkah selanjutnya adalah mengevaluasi model menggunakan data uji. Seperti yang sudah dijelaskan sebelumnya, penggunakan data uji atau data yang belum pernah dilihat model saat proses training akan memberikan evaluasi yang lebih fair dan menghindari overfitting.
Hasil prediksi pada data uji kemudian dibandingkan dengan nilai sebenarnya untuk mengukur seberapa baik model dalam memprediksi data tersebut.
Variabel y_pred berisi prediksi kelas untuk setiap amatan pada data uji secara berurutan. Untuk mengukur seberapa baik model dalam memprediksi kita perlu membandingkan hasil ini dengan label kelas sebenarnya yang tersimpan pada variabel y_test. Terdapat beberapa kriteria yang dapat digunakan dalam pemodelan klasifikasi seperti accuracy, balanced accuracy, f1 score, ROC AUC dan sebagainya.
Python
from sklearn.metrics import (
confusion_matrix,
accuracy_score,
balanced_accuracy_score,
classification_report,
)
print("\nconfusion_matrix:\n", confusion_matrix(y_test, y_pred))
print("\nAccuracy :", accuracy_score(y_test, y_pred))
print("\nbalanced Accuracy :", balanced_accuracy_score(y_test, y_pred))
print("\nClassification Report:\n",classification_report(y_test, y_pred))Output
# Output
confusion_matrix:
[[ 25 3 20]
[ 0 124 33]
[ 8 31 99]]
Accuracy : 0.7230320699708455
balanced Accuracy : 0.6760111849595373
Classification Report:
precision recall f1-score support
HIGH 0.76 0.52 0.62 48
LOW 0.78 0.79 0.79 157
STANDARD 0.65 0.72 0.68 138
accuracy 0.72 343
macro avg 0.73 0.68 0.70 343
weighted avg 0.73 0.72 0.72 343Dari informasi di atas diperoleh akurasi model sebesar 0,7230. Nilai ini bermakna berdasarkan data uji model berhasil memprediksi benar sebanyak 72,30 persen data. Pada contoh dari 343 data uji, 248 diantaranya diprediksi benar sementara sisanya sebanyak 95 salah prediksi. Nilai accuracy mengukur kinerja model secara total , pada kasus data yang tidak seimbang, terkadang nilai ini menjadi kurang tepat untuk digunakan. Ukuran lain yang dapat digunakan antara lain adalah balanced accuracy yang sudah mempertimbangkan kinerja setiap kelas. Nilai balance accuracy yang diperoleh sebesar 0,676 dan cukup jauh dibandingkan nilai accuracy mengindikasikan terdapat kelas dengan kinerja yang kurang baik.
Lebih rinci, berdasarkan confussion matrix dan classification report, kelas LOW memiliki nilai recall (sensitivitas) 0,79 di mana dari 157 data uji 124 diprediksi benar sementara 33 lainnya diprediksi salah. Sementara itu, nilai recall pada kelas STANDARD juga relatif sama yaitu sebesar 0,72 di mana dari 138 data uji 99 diprediksi benar dan sisanya salah (8 diprediksi sebagai kelas HIGH dan 31 sebagai kelas LOW). Adapun nilai recall kelas HIGH sangat rendah yaitu hanya 0,52 saja. Dari 48 data uji hanya 25 yang diprediksi benar sementara 23 lainnya salah, atau hanya sekitar setengahnya saja.
Meskipun secara umum model yang diperoleh memiliki kinerja yang cukup baik. Namun terdapat kemungkinan bahwa ada kombinasi hiperparmeter lain yang menghasilkan model lebih baik lagi. Oleh karena itu, pada bagian selanjutnya kita akan melakukan pencarian tersebut atau disebut juga tuning hiperparameter.
Tuning Hiperparameter (Random Search)
Terdapat beberapa teknik tuning hiperparameter yang tersedia pada scikit-learn. Salah satunya adalah random search cross validation yaitu mencari model terbaik berdasarkan kombinasi parameter yang diberikan secara random. Pada scikit-learn, proses ini dapat dilakukan menggunakan fungsi RandomizedSearchCV dari modul sklearn.model_selection. Fungsi randomizedSearchCV sendiri tidak hanya digunakan untuk model Random Forest saja, namun dapat digunakan pula pada model machine learning lainnya.
Pertama kita tentukan daftar nilai parameter yang diinginkan. Setiap parameter dapat memiliki lebih dari 1 nilai. Selanjutnya kita tentukan berapa banyak iterasi yang akan dilakukan. Misalkan 100, maka akan dilakukan iterasi sebanyak 100 kali dengan kombinasi nilai hiperaprameter yang dipilih secara random dari batasan yang diberikan. Pada setiap iterasi dilakukan proses pemodelan dan validasi untuk mengukur kinerja model berdasarkan metrik tertentu. Selanjutnya model dengan kinerja terbaik hasil validasi akan dijadikan sebagai model terbaik. Semakin banyak iterasi maka waktu eksekusi tentunya akan semakin lama, namun peluang memperoleh model yang lebih baik tentunya semakin besar.
Pada bagian ini, misalkan kita akan menggunakan balanced_accuracy sebagai metrik yang diukur. Kemudian, untuk hiperparameter yang akan kita tentukan yaitu n_estimators, max_depth, min_samples_split, max_features dan class_weight. Mengingat kondisi data yang tidak terlalu seimbang penentuan nilai class_weight yang berbeda mungkin dapat membantu meningkatkan performa model.
Python
from sklearn.model_selection import RandomizedSearchCV
param_dist = {
"n_estimators": np.arange(100, 401, 10), # 100, 110, 120, .., 400
"max_depth": [None] + np.arange(1, 20, 2).tolist(), # None, 1, 3, 5, ... 19
"min_samples_split": [2, 3, 5, 10, 15],
"max_features": [1, 2, 3, 4, 5],
"class_weight": ["balanced", "balanced_subsample"],
}
# tuning model dengan random search (50 iterasi)
rf_cv = RandomizedSearchCV(
model_rf,
param_distributions=param_dist,
n_iter=200, # pencarian sebanyak 200 kali
scoring="balanced_accuracy", # ukuran kinerja dengan balanced_accuracy
cv=5, # validasi silang dengan 5 fold
refit=True,
n_jobs=-1, # gunakan seluruh processor
random_state=100
)
# fitting model
rf_cv.fit(X_train, y_train)
# menampilkan pengaturan parameter da skor terbaik
print("Best Param:", rf_cv.best_params_)
print("best Score:", rf_cv.best_score_)Output
# Output
Best Param: {'n_estimators': 280, 'min_samples_split': 10, 'max_features': 4, 'max_depth': 19, 'class_weight': 'balanced_subsample'}
best Score: 0.6553456120512404Pada kode di atas, kita menentukan beberapa nilai berbeda untuk masing-masing parameter model. Selanjutnya gunakan suatu model Random Forest sebagai basis pencarian model terbaik berdasarkan parameter yang disediakan. Untuk menentukan model terbaik pada contoh ini kita akan menggunakan ukuran scoring="balanced_accuracy". Pemilihan model terbaik akan ditentukan berdasarkan nilai akurasi tertinggi hasil validasi silang pada data latih untuk setiap kombinasi parameter. Nilai lainnya pada fungsi RandomizedSearchCV yang kita tetapkan yaitu cv=5 (jumlah fold untuk proses cross validation), refit=True dan n_jobs=-1 (proses paralel menggunakan semua processor).
Setelah menjalankan kode di atas, kita akan memperoleh model terbaik berdasarkan parameter yang telah ditentukan. Model terbaik yang diperoleh memiliki nilai balanced_accuracy (berdasarkan validasi silang pada data latih) sebesar 0.655. Adapun parameter model hasil tuning berturut-turut yaitu 'n_estimators': 280, 'min_samples_split': 10, 'max_features': 4, 'max_depth': 19, 'class_weight': 'balanced_subsample'.
Seperti pada model sebelumnya, lakukan evaluasi menggunakan data uji.
Python
y_pred_cv = rf_cv.predict(X_test)
print("\nconfusion_matrix:\n", confusion_matrix(y_test, y_pred_cv))
print("\nAccuracy :", accuracy_score(y_test, y_pred_cv))
print("\nbalanced Accuracy :", balanced_accuracy_score(y_test, y_pred_cv))
print("\nClassification Report:\n",classification_report(y_test, y_pred_cv))Output
# Output
confusion_matrix:
[[ 29 0 19]
[ 1 126 30]
[ 12 32 94]]
Accuracy : 0.7259475218658892
balanced Accuracy : 0.6959579525523862
Classification Report:
precision recall f1-score support
HIGH 0.69 0.60 0.64 48
LOW 0.80 0.80 0.80 157
STANDARD 0.66 0.68 0.67 138
accuracy 0.73 343
macro avg 0.72 0.70 0.70 343
weighted avg 0.73 0.73 0.73 343Evaluasi model menunjukkan nilai balanced accuracy sebesar 0,696 dan terjadi peningkatan dibandingkan model sebelumnya. Selain itu terjadi peningkatan juga pada nilai accuracy menjadi 0,726. Hasil ini mungkin saja masih bisa ditingkatkan lagi dengan menambah jumlah iterasi pencarian, merubah daftar nilai hiperaprameter ataupun menggunakan teknik tuning hiperparameter lainnya. Namun untuk tulisan ini kita akan anggap hasil ini sebagai model akhir.
Menyimpan dan Memanggil Model
Model yang telah dibuat dapat disimpan dalam suatu file. Model dapat digunakan kembali atau bahkan didistribusikan tanpa perlu mengulang setiap proses training maupun tuning hiperparameter seperti yang sudah dilakukan.
Terdapat beberapa cara untuk melakukan proses ini misalkan menggunakan pustaka pickle atau joblib. Di sini kita akan menggunakan fungsi dump dan load pada pustaka joblib. Untuk menyimpan model ke dalam file dilakukan menggunakan fungsi dump sedangkan fungsi load untuk memuat model. Selanjutnya, model yang sudah dimuat dapat kita gunakan untuk melakukan prediksi data.
Pada contoh di bawah ini, misalkan terdapat dua sampel wine baru, kita dapat melakukan prediksi terhadap dua data tersebut. Hasil prediksi menunjukkan bahwa wine pertama diprediksi sebagai kelas HIGH dan wine kedua masuk ke dalam kelas STANDARD.
Python
from joblib import dump, load
# Menyimpan model ke dalam file
dump(rf_cv, 'model_rf_cv.joblib')
# Membaca model dari file
model_from_file = load('model_rf_cv.joblib')
# contoh data baru
new_data = pd.DataFrame({'fixed acidity' : [8.4, 7.94],
'volatile acidity' : [0.46, 0.48],
'citric acid' : [0.32, 0.28],
'residual sugar' : [2.6, 2.6],
'chlorides': [0.065, 0.081],
'free sulfur dioxide': [14.7, 14.7],
'total sulfur dioxide': [38.24, 38.85],
'density': [0.95, 0.98],
'pH': [3.4, 3.4],
'sulphates': [0.72, 0.70],
'alcohol': [11.8, 11.0]
})
print(new_data.transpose())
# Menggunakan model untuk memprediksi
model_from_file.predict(new_data)Output
# Output
0 1
fixed acidity 8.400 7.940
volatile acidity 0.460 0.480
citric acid 0.320 0.280
residual sugar 2.600 2.600
chlorides 0.065 0.081
free sulfur dioxide 14.700 14.700
total sulfur dioxide 38.240 38.850
density 0.950 0.980
pH 3.400 3.400
sulphates 0.720 0.700
alcohol 11.800 11.000
array(['HIGH', 'STANDARD'], dtype=object)Selamat mencoba!!!
Referensi
- Breiman, L. (2001) Random Forests. Machine Learning, 45, 5-35. https://doi.org/10.1023/A:1010933404324
- RandomForestClassifier — scikit-learn 1.5.0 documentation
- RandomizedSearchCV — scikit-learn 1.5.0 documentation
Tulisan Lainnya
- Tuning Hyperparameter Model Random Forest dengan Bayesian Optimization
- Tuning Hyperparameter Model random Forest dengan Particle Swarm Optimization
- Pemodelan Klasifikasi dengan Algoritma KNN (Prediksi Penderita Diabetes)
- Permutation Importance untuk Penentuan Peubah Penting dan Implementasinya dengan Python
- Tuning Model XGBoost dengan Python