Metrik Evaluasi untuk Model Klasifikasi

Evaluasi model klasifikasi adalah proses mengukur seberapa baik kinerja model dalam memprediksi kelas yang benar. Pengukuran kinerja ini dilakukan dengan membandingkan kelas hasil prediksi model terhadap kelas sebenarnya. Terdapat banyak sekali metrik yang dapat digunakan untuk menilai kinerja model klasifikasi seperti akurasi, presisi dan F1 Score. Pada tutorial ini akan dibahas metrik-metrik tersebut beserta contoh penggunaannya dengan paket yardstick R dan scikit-learn Python.
Confusion Matrix
Confusion matrix adalah matiks yang menyajikan tabulasi hasil prediksi dari suatu model klasifikasi. Matriks ini berisi informasi nilai-nilai yang merepresentasikan bagaimana model memprediksi kelas tertentu dibandingkan dengan kelas sebenarnya.
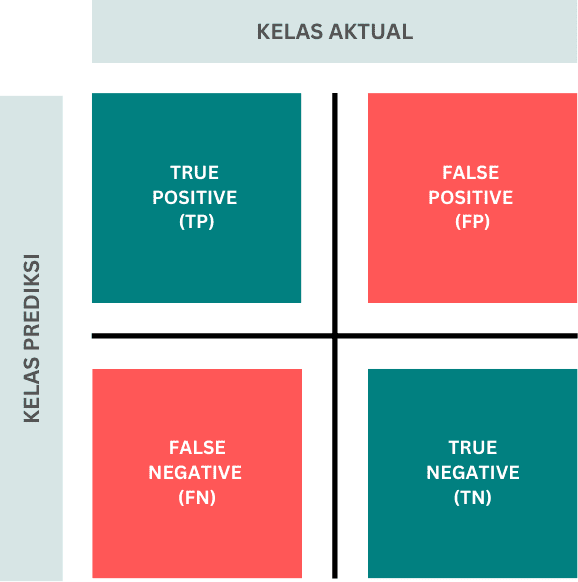
Gambar 1. Confusion Matrix klasifikasi biner (Gambar oleh penulis)
Gambar 1 di atas merupakan bentuk confusion matrix pada klasifikasi biner (2 kelas output). Pada klasifikasi biner, biasanya terdapat satu kelas yang disebut sebagai kelas positif dan kelas lainnya sebagai kelas negatif. Penentuan kelas positif ini tidak berkaitan dengan konotasi dari kelas tersebut, namun dapat dipilih yang mana saja sesuai keinginan atau kebutuhan peniliti. Terdapat 4 nilai yang disajikan pada Gambar 1 yaitu:
- True Positive (TP): jumlah data dari kelas positif yang diprediksi benar (masuk kelas positif)
- True Negative (TN): jumlah data dari kelas negatif yang diprediksi benar (masuk kelas negatif)
- False Positive (FP): jumlah data dari kelas negatif yang salah prediksi (seharusnya negatif namun diprediksi positif)
- False negative (FN): jumlah data dari kelas positif yang salah prediksi (seharusnya positif namun diprediksi negatif)
Lebih general, pada klasifikasi multi-kelas (lebih dari 2 kelas output) ukuran confusion matrix juga menjadi lebih banyak. Misalkan pada Gambar 2, untuk 3 kelas maka ukuran confusion matrix menjadi 3×3, atau berisi 9 nilai. Secara umum, nilai yang terdapat pada posisi diagonal menunjukkan jumlah prediksi benar dari masing-masing kelas. Adapun pada bagian lainnya menunjukkan prediksi salah. Sebagai contoh K1 (TRUE) menyatakan banyaknya prediksi benar dari data yang memang seharusnya masuk ke dalam kelas ke-1. Sedangkan K1 (FALSE) menyatakan banyaknya data yang seharusnya merupakan kelas K2 dan K3 namun salah diprediksi sebagai K1.
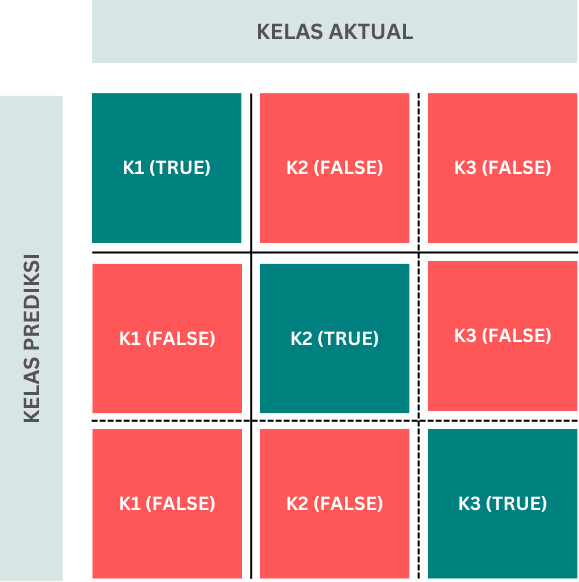
Gambar 2. Confusion Matrix klasifikasi 3 kelas (Gambar oleh penulis)
Meskipun terdapat perbedaan ukuran, namun metrik-metrik evaluasi yang digunakan tetap berlaku secara umum. Perhitungan pada setiap metrik evaluasi tersebut sangat tergantung dengan nilai-nilai pada confusion matrix.
Accuracy (Akurasi)
Akurasi adalah proporsi banyaknya data yang diprediksi dengan benar terhadap total data yang diprediksi. Nilai akurasi menunjukkan gambaran secara global seberapa baik prediksi yang dilakukan. Misal, nilai akurasi 0,85 bermakna dari total seluruh data yang diprediksi, model dengan tepat memprediksi 85% sedangkan 15% salah prediksi.
Pada klasifikasi biner, formula untuk menghitung akurasi adalah sebagai berikut:
$$\text{Akurasi}=\frac{\text{TP + TN}}{\text{TP + TN + FP + FN}}$$
Persamaan tersebut dapat dibuat lebih umum untuk menghitung akurasi data klasifikasi multikelas yaitu:
$$\text{Akurasi}=\frac{\sum_{i=1}^{n} \text{TP}_{\text{kelas}-i}}{\sum_{i=1}^{n} \text{TP}_{\text{kelas}-i} + \sum_{i=1}^{n} \text{FP}_{\text{kelas}-i}}$$
Berikut ini diberikan contoh penghitungan nilai akurasi berdasarkan suatu confusion matrix untuk klasifikasi biner maupun multikelas.
Contoh 1
KLASIFIKASI BINER
Misal dari hasil penghitungan model klasifikasi biner diperoleh confusion matrix sebagai berikut:
$$\begin{array}{c|cc}\text{ } & \text{Aktual} & \text{ } \\ \text{Prediksi} & A & B \\ A & 280 & 40\\ B & 20 & 60 \\ \end{array}$$
Maka, nilai akurasi diperoleh sebagai berikut:
$$\begin{aligned}\text{Akurasi}&=\frac{280+60}{280+40+20+60} =0,85\end{aligned}$$
Berdasarkan hasil tersebut, diperoleh nilai akurasi 0,85. Artinya, secara umum model memiliki kemampuan memprediksi dengan benar sebesar 85%.
Contoh 2
KLASIFIKASI MULTIKELAS
Misal dari hasil penghitungan model klasifikasi 3 kelas diperoleh confusion matrix sebagai berikut:
$$\begin{array}{c|ccc}
\text{ } & \text{} & \text{Aktual} & \text{ } \\ \text{Prediksi} & A & B & C \\ A & 80 & 0 & 10 \\ B & 10 & 70 & 20 \\ C & 5 & 15 & 90 \\ \end{array}$$
Maka, nilai akurasi diperoleh sebagai berikut:
$$\begin{aligned}\text{Akurasi}&=\frac{80+70+90}{80+0+10+…+5+15+90} =0,80\end{aligned}$$
Perhitungan pada contoh 2 di atas, menunjukkan nilai akurasi sebesar 0,80 atau 80%.
Recall (Sensitivity & Specificity)
Metrik Recall, juga dikenal sebagai sensitivity, adalah salah satu metrik penting dalam evaluasi model klasifikasi. Recall mengukur kemampuan model untuk mendeteksi semua sampel suatu kelas di antara semua sampel yang benar-benar masuk kelas tersebut. Dalam konteks deteksi penyakit, misalnya, recall mengukur seberapa baik model dapat mendeteksi pasien yang benar-benar sakit dari semua pasien yang sakit.
Istilah sensitivity biasanya digunakan untuk menyebutkan recall pada kelas positif atau True Positive Rate (TPR). Adapun untuk kelas negatif istilah yang digunakan adalah specificity. Namun sekali lagi, penentuan kelas positif akan sangat tergantung ketertarikan dan tujuan penelitian.
Nilai recall dihitung untuk masing-masing kelas dengan persamaan sebagai berikut:
$$\text{Recall}_i=\frac{\text{TP}_{\text{kelas}-i}}{\text{TP}_{\text{kelas}-i} +\text{FN}_{\text{kelas}-i}}$$
Sekarang, mari kita menghitung nilai recall berdasarkan confusion matrix pada Contoh 1 dan Contoh 2 sebelumnya.
Contoh 3
KLASIFIKASI BINER
Misal dari hasil penghitungan model klasifikasi biner diperoleh confusion matrix sebagai berikut:
$$\begin{array}{c|cc}\text{ } & \text{Aktual} & \text{ } \\ \text{Prediksi} & A & B \\ A & 60 & 20\\ B & 40 & 280 \\ \end{array}$$
Maka, nilai recall untuk kelas A dan B adalah sebagai berikut:
$$\begin{aligned} \text{Recall}_A &=\frac{60}{60+40} =0,60 \\\\ \text{Recall}_B &=\frac{280}{280+20} = 0,93 \end{aligned}$$
Berdasarkan hasil di atas, didapatkan nilai recall untuk kelas A sebesar 0,60 dan kelas B sebesar 0,93. Misal, kita anggap kelas A sebagai kelas positif maka bisa kita katakan bahwa nilai sensitivity model sebesar 0,60 dan nilai specificity adalah 0,93. Ada hal menarik di sini yaitu kinerja model yang relatif buruk dalam memprediksi kelas positif di mana informasi ini tidak diketahui hanya dari nilai accuracy saja.
Bayangkan hasil tersebut merupakan berasal model untuk mendeteksi apakah seorang terkena covid-19 atau tidak. Misal kelas A menyatakan orang yang terkena penyakit covid-19 dan kelas B yang tidak. Jika hanya melihat dari nilai akurasi sebesar 0,85 maka kita akan simpulkan bahwa model cukup baik. Namun melihat nilai sensitivity hanya sebesar 0,60, artinya model hanya mampu memprediksi benar 60% orang yang benar-benar terkena covid-19. jika terdapat 100 orang yang benar-benar terkena covid-19 model hanya mampu memprediksi positif sekitar 60 orang saja, sementara sisanya diprediksi negatif covid-19. Tentunya prediksi seperti sangat buruk karena dampaknya bisa membahayakan.
Kondisi anomali ini sering terjadi pada data yang tidak seimbang, dimana jumlah data pada satu kelas jauh lebih banyak atau lebih sedikit dibandingkan kelas lainnya. Pada kondisi kelas tidak seimbang, penggunaan nilai accuracy untuk mengukur kinerja model, seringkali tidak tepat dan mungkin menjadikan model tidak terlalu berguna. Oleh karena itu terkadang penggunaan metrik recall menjadi sangat penting untuk mengukur kinerja model terlebih seperti contoh pendeteksian penyakit ini.
Contoh 4
KLASIFIKASI MULTIKELAS
Misal dari hasil penghitungan model klasifikasi 3 kelas diperoleh confusion matrix sebagai berikut:
$$\begin{array}{c|ccc}
\text{ } & \text{} & \text{Aktual} & \text{ } \\ \text{Prediksi} & A & B & C \\ A & 80 & 0 & 10 \\ B & 10 & 70 & 20 \\ C & 5 & 15 & 90 \\ \end{array}$$
Maka, nilai recall untuk kelas A, B dan C adalah sebagai berikut:
$$\begin{aligned} \text{Recall}_A &=\frac{80}{80+10+5} =0,84 \\\\ \text{Recall}_B &=\frac{70}{0+70+15} = 0,82 \\\\ \text{Recall}_C &=\frac{90}{10+20+90} = 0,75 \end{aligned}$$
Hasil perhitungan di atas, menunjukkan nilai recall untuk kelas A yaitu 0,84. Dari seluruh data kelas A, model memprediksi benar 84% sementara 16% lainnya salah pediksi sebagai kelas lainnya (B atau C). Begitu pula nilai recall untuk kelas B dan C yaitu asing-masing 0,82 dan 0,75. Meskipun recall kelas C agak lebih rendah dibanding kelas A dan B, namun secara umum kemampuan model memprediksi masing-masing kelas dapat dikatakan relatif sama baiknya.
Precision (Presisi)
Precision adalah metrik evaluasi kinerja yang digunakan untuk mengukur akurasi pada kelas prediksi tertentu. Pada kasus klasifikasi biner, presisi mengukur seberapa banyak data yang prediksi ke suatu kelas yang memang benar masuk kelas tersebut. Presisi memberikan gambaran tentang kualitas prediksi positif yang dihasilkan oleh model.
Sama seperti recall, nilai presisi juga dihitung untuk masing-masing kelas dengan formula sebagai berikut:
$$\text{Precision}_i=\frac{\text{TP}_{\text{kelas}-i}}{\text{TP}_{\text{kelas}-i} +\text{FP}_{\text{kelas}-i}}$$
Contoh 5
KLASIFIKASI BINER
Misal dari hasil penghitungan model klasifikasi biner diperoleh confusion matrix sebagai berikut:
$$\begin{array}{c|cc}\text{ } & \text{Aktual} & \text{ } \\ \text{Prediksi} & A & B \\ A & 60 & 20\\ B & 40 & 280 \\ \end{array}$$
Maka, nilai precision untuk kelas A dan B adalah:
$$\begin{aligned} \text{Precision}_A &=\frac{60}{60+20} =0,75 \\\\ \text{Precision}_B &=\frac{280}{280+40} = 0,875 \end{aligned}$$
Precision kelas A bernilai 0,75 yang berarti dari semua yang diprediksi sebagai kelas A, sekitar 75% yang memang benar dari kelas A, sementara 25% lainnya seharusnya masuk kelas B. Begitu juga dengan precision kelas B sebesar 0,875 bermakna dari semua data yang diprediksi masuk kelas B, terdapat 87,5% yang memang benar kelas B, sementara 12,5% lainnya salah prediksi dan seharusnya masuk kelas A.
Contoh 6
KLASIFIKASI MULTIKELAS
Misal dari hasil penghitungan model klasifikasi 3 kelas diperoleh confusion matrix sebagai berikut:
$$\begin{array}{c|ccc}
\text{ } & \text{} & \text{Aktual} & \text{ } \\ \text{Prediksi} & A & B & C \\ A & 80 & 0 & 10 \\ B & 10 & 70 & 20 \\ C & 5 & 15 & 90 \\ \end{array}$$
Maka, nilai precision untuk kelas A, B dan C adalah sebagai berikut:
$$\begin{aligned} \text{Precision}_A &=\frac{80}{80+0+10} =0,889 \\\\ \text{Precision}_B &=\frac{70}{10+70+20} = 0,700 \\\\ \text{Precision}_C &=\frac{90}{15+5+90} = 0,818 \end{aligned}$$
Sama seperti sebelumnya, nilai precision pada kelas A sebesar 0,889 menunjukkan bahwa dari semua data yang diprediksi masuk kelas A, 88,9% memang benar merupakan kelas A. Namun sisanya sekitas 11,1% salah prediksi dan seharusnya masuk ke dalam kelas B atau C. begitu juga untuk nilai precision kelas B dan C, Penjelasan yang sama juga berlaku untuk kedua kelas tersebut.
F1 Score
F1 Score adalah metrik evaluasi kinerja model klasifikasi yang menggabungkan precision dan recall menjadi satu nilai tunggal. Metrik ini diukur dari rata-rata harmonis precision dan recall, sehingga memberikan gambaran yang lebih seimbang tentang kinerja model terutama ketika terdapat ketidakseimbangan antara jumlah kelas positif dan negatif.
Ketika berbicara klasifikasi biner, F1 Score umumnya diukur pada kelas positif saja. Sementara itu, pada klasifikasi multikelas, kita dapat mengukur F1 Score suatu kelas vs total kelas lainnya.
Perhitungan nilai F1 Score dilakukan menggunakan persamaan berikut ini:
$$\text{F1}_i=2 \times \frac{\text{Precision}_i\times \text{Recall}_i}{\text{Precision}_i + \text{Recall}_i}$$
Contoh 7
KLASIFIKASI BINER
Nilai recall (sensitivity) dan precision dari perhitungan sebelumnya:
$$\begin{aligned} \text{Recall}_A &=0,60 \quad \text{dan} \quad \text{Precision}_A = 0,75 \end{aligned}$$
Maka, nilai F1 Score model adalah:
$$\begin{aligned} \text{F1} &=2 \times \frac{0,60 \times 0,75}{0,60+0,75} = 0,667 \end{aligned}$$
Berdasarkan perhitungan tersebut diperoleh F1 score sebesar 0,667. Nilai ini jauh lebih rendah dibandingkan nilai accuracy yang mencapai 0,85. Namun mengingat kinerja model dalam memprediksi kelas positif sangat rendah, maka nilai ini tentunya lebih sesuai menggambarkan kemampuan model.
Contoh 8
KLASIFIKASI MULTIKELAS
Nilai recall dan precision untuk kelas A dari perhitungan sebelumnya:
$$\begin{aligned} \text{Recall}_A &=0,84 \quad \text{dan} \quad \text{Precision}_A = 0,889 \end{aligned}$$
Maka, nilai F1 Score model adalah:
$$\begin{aligned} \text{F1}_A &=2 \times \frac{0,84 \times 0,889}{0,84+0,889} = 0,864 \end{aligned}$$
F1 Score yang dihasilkan pada contoh ini bisa dikatakan cukup baik yaitu sebesar 0,864. Hal ini juga menunjukkan bahwa kinerja model secara umum cukup baik. Meskipun pada contoh di atas kita hanya mengukur nilai untuk kelas A, cara yang sama tentunya dapat diterapkan untuk keas A dan B.
Balanced Accuracy
Metrik lainnya yang cukup baik digunakan khususnya pada data tidak seimbang adalah balanced accuracy. Nilai balanced accuracy dihitung berdasarkan rata-rata nilai recall dari seluruh kelas. Pada kasus klasifikasi biner, nilai balanced accuracy yaitu rata-rata nilai sensitivity dan spesificity.
$$\text{Bal. Accuracy}=\frac{\sum_{i=1}^n\text{Recall}_i}{n}$$
Contoh 9
KLASIFIKASI BINER
Nilai recall dari perhitungan sebelumnya:
$$\begin{aligned} \text{Recall}_A &=0,60 \quad \text{dan} \quad \text{Recall}_B = 0,93 \end{aligned}$$
Maka, nilai balanced accuracy model adalah:
$$\begin{aligned} \text{Bal. Accuracy} &=\frac{0,93+0,60}{2} = 0,767 \end{aligned}$$
Berdasarkan perhitungan tersebut diperoleh balanced accuracy sebesar 0,767. Nilai ini jauh lebih rendah dibandingkan nilai accuracy yang mencapai 0,85. Namun mengingat kinerja model dalam memprediksi kelas positif sangat rendah, maka nilai balanced accuracy rasanya lebih sesuai menggambarkan kemampuan model.
Contoh 10
KLASIFIKASI MULTIKELAS
Nilai recall dari perhitungan sebelumnya:
$$\begin{aligned} \text{Recall}_A &=0,84 \ \text{,} \quad \text{Recall}_B=0,82 \quad \text{dan} \quad \text{Recall}_C = 0,75 \end{aligned}$$
Maka, nilai balanced accuracy adalah:
$$\begin{aligned} \text{Bal. Accuracy} &=\frac{0.84+0.82+0.75}{3} =0,803 \end{aligned}$$
Nilai balanced accuracy yang dihasilkan relatif sama dengan nilai accuracy yaitu sekitar 0,8. Hal ini juga menunjukkan bahwa kinerja model secara umum cukup baik dalam memprediksi masing-masing kelas.
ROC-AUC
ROC-AUC adalah metrik evaluasi kinerja model klasifikasi yang digunakan untuk menilai kemampuan model dalam membedakan antara kelas positif dan negatif. ROC adalah singkatan dari Receiver Operating Characteristic, dan AUC adalah singkatan dari Area Under the Curve. Metrik ROC-AUC memberikan gambaran tentang bagaimana model berperforma pada berbagai threshold klasifikasi.
Kurva ROC adalah grafik yang menunjukkan hubungan antara True Positive Rate (TPR) dan False Positive Rate (FPR) pada berbagai threshold klasifikasi. Pada kurva ROC, kedua sumbu menyatakan nilai TPR dan FPR, di mana
- True Positive Rate (TPR) adalah terminologi lain dari recall atau sensitivity
- False Positive Rate (FPR) ekuivalen dengan nilai $1-\text{specificity}$
AUC adalah luas area di bawah kurva ROC. Nilai AUC berkisar antara 0 dan 1:
- AUC = 1 menunjukkan model yang sempurna.
- AUC = 0.5 menunjukkan model yang tidak lebih baik dari tebakan acak.
- AUC < 0.5 menunjukkan model yang lebih buruk dari tebakan acak.
Semakin besar nilai AUC, semakin baik model tersebut dalam membedakan antara kelas positif dan negatif.
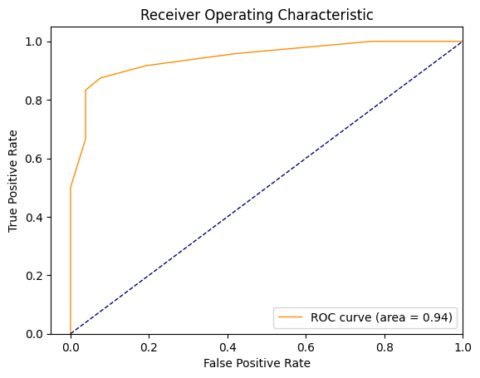
Gambar 3. Contoh Kurva ROC-AUC (Gambar oleh Penulis)
Gambar 3 di atas menampilkan ilustrasi kurva ROC-AUC di mana luas AUC sebesar 0,94 mengindikasikan model memiliki kinerja yang sangat baik.
Metrik Evaluasi dengan R
Paket tidymodels merupakan metapaket yang terdiri dari berbagai paket untuk pemrosesan model machine learning. Salah satu paket di dalamnya adalah yardstick yang dapat digunakan untuk menghitung berbagai metrik evaluasi.
Baca juga: Membangun Model Machine Learning dengan tidymodels R
R
library(tidymodels)
# Menggabungkan data ke dalam tibble
data <- read.csv(
"https://raw.githubusercontent.com/sainsdataid/dataset/main/aktual_vs_prediksi_binary.csv",
stringsAsFactors=T
)
# Confusion Matrix
conf_matrix <- conf_mat(data, aktual, prediksi)
cat("confusion matrix:\n")
print(conf_matrix)
# menghitung metrik evaluasi
accuracy <- accuracy_vec(truth = data['aktual'], estimate = data['prediksi'])
recall <- recall_vec(truth = data['aktual'], estimate = data['prediksi'])
precision <- precision_vec(truth = data['aktual'], estimate = data['prediksi'])
f1_score <- f_meas_vec(truth = data['aktual'], estimate = data['prediksi'])
bal_accuracy <- bal_accuracy_vec(truth = data['aktual'], estimate = data['prediksi'])
cat("\nAccuracy:", accuracy)
cat("\nRecall:", recall)
cat("\nPrecision:", precision)
cat("\nF1 Score:", f1_score)
cat("\nbal. Accuracy:", bal_accuracy, "\n")
# menghitung metrik evaluasi (tidyverse style)
list_metrics <- data %>%
summarise(
accuracy = accuracy_vec(truth = aktual, estimate = prediksi),
recall = recall_vec(truth = aktual, estimate = prediksi),
precision = precision_vec(truth = aktual, estimate = prediksi),
f1_score = f_meas_vec(truth = aktual, estimate = prediksi),
bal_accuracy = bal_accuracy_vec(truth = aktual, estimate = prediksi),
)
cat("\nMetrik Evaluasi:\n")
print(list_metrics)# OUTPUT
confusion matrix:
Truth
Prediction HIGH LOW
HIGH 139 30
LOW 47 127
Accuracy: 0.7755102
Recall: 0.7473118
Precision: 0.8224852
F1 Score: 0.7830986
bal. Accuracy: 0.7781145
Metrik Evaluasi:
accuracy recall precision f1_score bal_accuracy
1 0.7755102 0.7473118 0.8224852 0.7830986 0.7781145Untuk menyajikan kurva ROC-AUC kita bisa menggunakan fungsi roc_curve. Hasil dari fungsi ini selanjutnya bisa divisualisasikan menggunakan paket seperti ggplot,
R
library(ggplot2) data$prediksi <- as.numeric(data$prediksi) - 1 # 'LOW' menjadi 0, 'HIGH' menjadi 1 # Hitung AUC dan plot ROC curve roc_results <- data %>% roc_curve(aktual, prediksi) %>% ggplot(aes(x = sensitivity, y = 1 - specificity)) + geom_path(color = "orange") + geom_abline(lty = 10) print(roc_results)
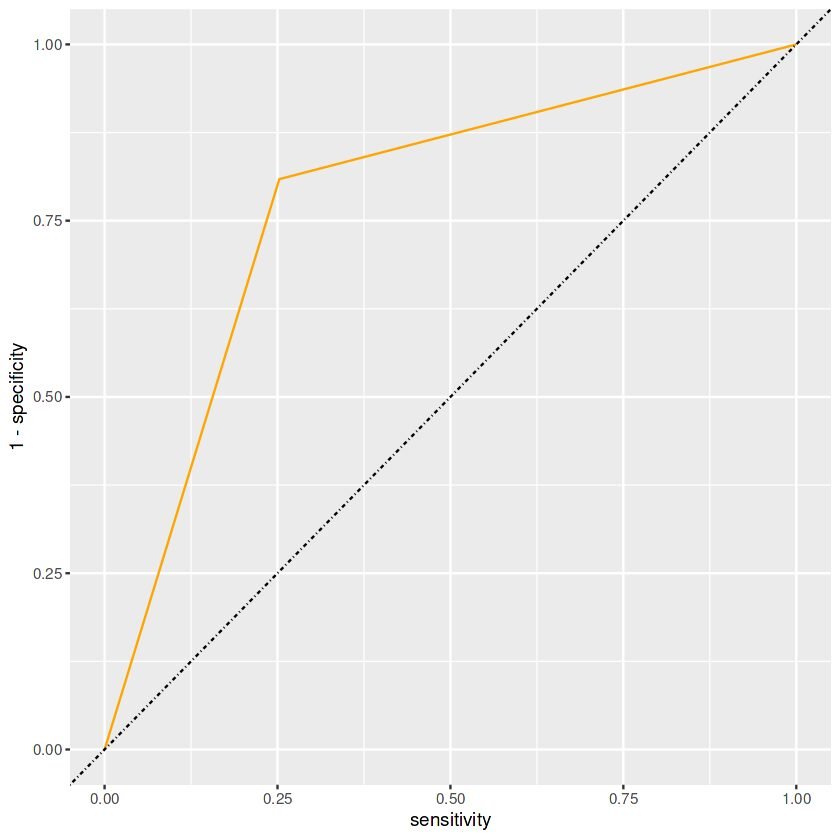
Gambar 3. Kurva ROC-AUC R (Gambar oleh Penulis)
Metrik Evaluasi dengan Python
Paket scikit-learn memiliki modul yang khusus yaitu metrics yang berisi fungsi-fungsi untuk mengukur berbagai metrik evaluasi. Contoh di bawah ini menyimulasikan penghitungan beberapa metrik berdasarkan hasil prediksi suatu model terhadap nilai sebenarnya. Pada kondisi real, nilai ini biasanya diperoleh saat membuat prediksi dengan model yang telah dilatih.
Fungsi recall_score, precision_score dan f1_score secara default mengembalikan nilai untuk setiap kelas. Namun kita juga dapat mengatur parameter average dengan beberapa pilihan untuk memperoleh nilai secara agregat.
Pada modul metrics juga terdapat fungsi confusion_matrix untuk menampilkan confusion matrix, serta fungsi classification_report untuk menampilkan tabulasi beberapa metrik sekaligus.
catatan: scikit-learn menyajikan confusion matrix dengan format yang berkebalikan dari Gambar 1 dan Gambar 2 ataupun output dari R. Nilai aktual direpresentasikan pada sisi baris dan nilai prediksi pada sisi kolom. Sehingga Posisi FALSE POSITIVE & FALSE NEGATIVE juga berkebalikan.
Python
from sklearn import metrics
import numpy as np
import pandas as pd
# contoh hasil prediksi dan nilai aktual
dummy_results = pd.read_csv(
"https://raw.githubusercontent.com/sainsdataid/dataset/main/aktual_vs_prediksi_binary.csv"
)
aktual = dummy_results["aktual"]
prediksi = dummy_results["prediksi"]
# Menghitung metrik evaluasi
accuracy = metrics.accuracy_score(aktual, prediksi)
recall = metrics.recall_score(aktual, prediksi, average=None)
precision = metrics.precision_score(aktual, prediksi, average=None)
f1 = metrics.f1_score(aktual, prediksi, average=None)
bal_acc = metrics.balanced_accuracy_score(aktual, prediksi)
# untuk recall, precision dan f1 kita juga dapat menyajikan nilai secara agregat
# recall = metrics.recall_score(actual, prediksi, average='weighted')
# precision = metrics.precision_score(actual, prediksi, average='weighted')
# f1 = metrics.f1_score(actual, prediksi, average='weighted')
cm = metrics.confusion_matrix(aktual, prediksi)
report = metrics.classification_report(aktual, prediksi)
print("\nAccuracy:", accuracy)
print("Recall:", recall)
print("Precision:", precision)
print("F1 Score:", f1)
print("Bal. Accuracy Score:", bal_acc)
print("\nConfusion Matrix:\n", cm)
print("\nReport:\n", report)# OUTPUT
Accuracy: 0.7755102040816326
Recall: [0.74731183 0.8089172 ]
Precision: [0.82248521 0.72988506]
F1 Score: [0.78309859 0.7673716 ]
Bal. Accuracy Score: 0.7781145127046093
Confusion Matrix:
[[139 47]
[ 30 127]]
Report:
precision recall f1-score support
HIGH 0.82 0.75 0.78 186
LOW 0.73 0.81 0.77 157
accuracy 0.78 343
macro avg 0.78 0.78 0.78 343
weighted avg 0.78 0.78 0.78 343Nilai ROC-AUC juga dapat diperoleh dengan fungsi roc_auc_score. Selanjutnya untuk memperoleh nilai-nilai TPR dan FPR dilakukan melalui fungsi roc_curve. Hasil dari fungsi ini selanjutnya dapat divisualisasikan dengan bantuan paket matplotlib
Python
from sklearn import metrics
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# Ubah label kelas menjadi numerik (0 dan 1)
aktual_numeric = np.where(aktual == 'HIGH', 1, 0)
prediksi_numerik = np.where(prediksi == 'HIGH', 1, 0)
# Hitung AUC
roc_auc = metrics.roc_auc_score(aktual_numeric, prediksi_numerik)
# Hitung ROC curve
fpr, tpr, _ = metrics.roc_curve(aktual_numeric, prediksi_numerik)
# Plot ROC curve
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=1.5, label=f'ROC curve (area = { roc_auc:.1%})')
plt.plot([0, 1], [0, 1], color='navy', lw=1.5, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver Operating Characteristic')
plt.legend(loc="lower right")
plt.show()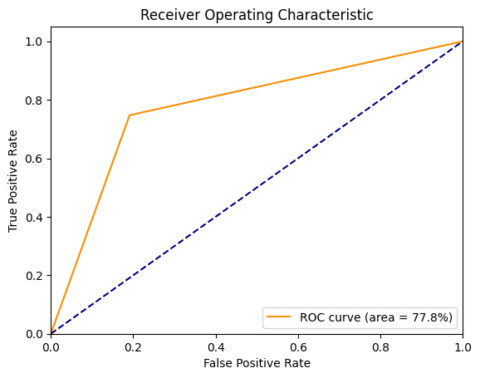
Gambar 4. Kurva ROC-AUC Python (Gambar oleh Penulis)
Baca juga: Model Klasifikasi Random Forest dengan scikit-learn
Referensi
- Dokumentasi modul
sklearn.metrics: sklearn.metrics — scikit-learn 1.5.0 - Dokumentasi paket
yardstick(tidymodels): Function reference • yardstick