Algoritma K-Nearest Neighbors (KNN) dengan R

Konsep K-Nearest Neighbors (KNN)
K-Nearest Neighbors (KNN) merupakan metode populer dalam bidang machine learning. Konsep dasar algoritma KNN adalah mencari k-nearest neighbors atau k tetangga terdekat dari suatu observasi berdasarkan jarak euclidean ataupun ukuran jarak lainnya. KNN umumnya digunakan untuk pemodelan klasifikasi namun dapat digunakan juga pada pemodelan regresi.
Dalam model klasifikasi, algoritma KNN menghitung jarak antara amatan yang akan diklasifikasikan dengan dataset yang sudah memiliki label kelas, dan memilih k tetangga terdekat dengan amatan tersebut berdasarkan jarak tersebut. Setelah itu, dari k tetangga tersebut, dilihat kelas apa yang paling banyak (mayoritas) menjadi tetangga terdekatnya. Hasil akhir yaitu mengklasifikasikan amatan tersebut masuk ke dalam kelas mayoritas yang diperoleh.
Prinsip Dasar dan Proses KNN
- Jarak: KNN mengukur kesamaan antara data dengan menghitung jarak antara titik data dalam ruang fitur. Jarak ini dapat diukur menggunakan berbagai metrik, seperti Euclidean, Manhattan, atau Minkowski distance.
- K-Neighbors: “K” dalam KNN menunjukkan jumlah tetangga terdekat yang akan digunakan untuk membuat prediksi. Algoritma ini memeriksa label k tetangga terdekat suatu titik data dan menentukan label mayoritas sebagai prediksi.
Langkah-Langkah KNN
- Menentukan Parameter k: Pemilihan nilai k adalah bagian kritis dari algoritma KNN. Nilai k yang terlalu kecil dapat menyebabkan model rentan terhadap noise, sedangkan nilai k yang besar dapat mengaburkan batas keputusan yang sebenarnya.
- Menghitung Jarak: Algoritma menghitung jarak antara titik data yang akan diprediksi dengan semua titik data dalam set pelatihan.
- Menentukan Tetangga Terdekat: Algoritma memilih k tetangga terdekat berdasarkan jarak yang dihitung sebelumnya.
- Menentukan Kelas Prediksi: kelas mayoritas dari tetangga terdekat digunakan sebagai prediksi untuk titik data yang dipertanyakan.
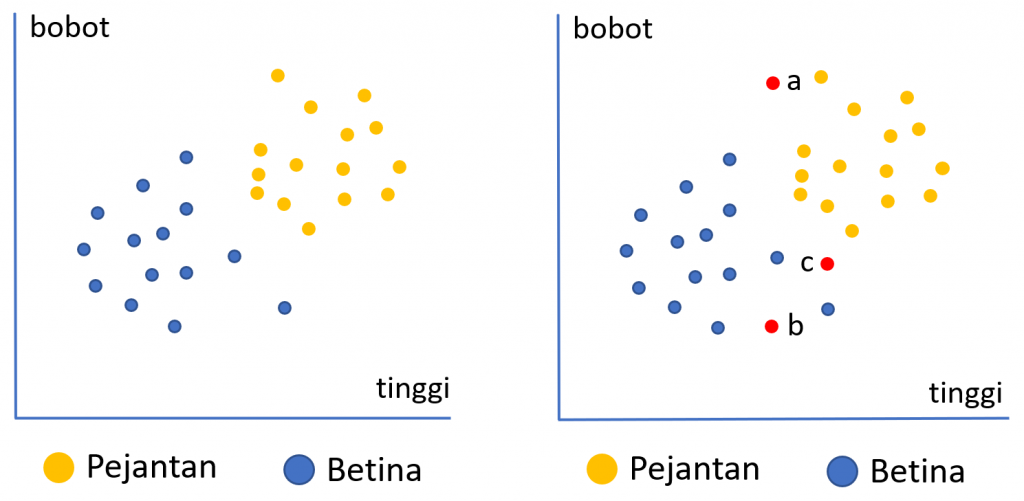
Ilustrasi di atas menunjukkan data historis mengenai karakteristik anak ayam yang baru menetas menurut dua kriteria yaitu tinggi dan bobot. Warna biru menunjukkan anak ayam betina dan orange anak ayam jantan. Secara visual dapat dilihat bahwa kecenderungan anak ayam jantan memiliki bobot dan tinggi yang lebih besar dibandingkan anak ayam betina. Pertanyaannya adalah jika kita memiliki 3 anak ayam yang baru menetas (misal amatan denganw arna merah), dan belum diketahui jenis kelaminnya bagaimana kita dapat memprediksi jenis kelamin dari ketiga anak ayam tersebut.
Penentuan kelas prediksi pada algoritma KNN diukur dari kedekatan jarak data baru tersebut dengan tetangga terdekatnya. Sebagai contoh, berdasarkan k=3 tetangga terdekat, anak ayam a kemungkinan akan diprediksi sebagai pejantan karena tiga tetangga terdekatnya adalah pejantan. Begitu pula anak ayam b akan diprediksi sebagai betina. Untuk anak ayam c, 2 dari 3 tetangga terdekatnya adalah pejantan maka akan diprediksi sebagai pejantan.
Untuk memperoleh model KNN yang baik, parameter penting yang perlu ditentukan adalah nilai k, atau jumlah tetangga terdekat yang akan digunakan. Nilai k tentu saja akan berbeda tergantung dari permasalahan dan data yang dihadapi. Penentuan nilai k optimal ini dapat dilakukan melalui proses tuning hyperparameter.
Penyiapan Data
Dataset yang digunakan memiliki format csv sehingga kita dapat membacanya menggunakan fungsi read.csv. Peubah respon atau kelas pada dataset tersimpan pada kolom quality dengan nilai LOW atau HIGH. Sementara kolom lainnya seluruhnya bertipe numerik.
R
data <- read.csv("wine-quality-binary.csv")
str(data)# OUTPUT 'data.frame': 1143 obs. of 13 variables: $ id : int 1 2 3 4 5 6 7 8 9 10 ... $ fixed.acidity : num 7.4 7.8 7.8 11.2 7.4 7.4 7.9 7.3 7.8 6.7 ... $ volatile.acidity : num 0.7 0.88 0.76 0.28 0.7 0.66 0.6 0.65 0.58 0.58 ... $ citric.acid : num 0 0 0.04 0.56 0 0 0.06 0 0.02 0.08 ... $ residual.sugar : num 1.9 2.6 2.3 1.9 1.9 1.8 1.6 1.2 2 1.8 ... $ chlorides : num 0.076 0.098 0.092 0.075 0.076 0.075 0.069 0.065 0.073 0.097 ... $ free.sulfur.dioxide : num 11 25 15 17 11 13 15 15 9 15 ... $ total.sulfur.dioxide: num 34 67 54 60 34 40 59 21 18 65 ... $ density : num 0.998 0.997 0.997 0.998 0.998 ... $ pH : num 3.51 3.2 3.26 3.16 3.51 3.51 3.3 3.39 3.36 3.28 ... $ sulphates : num 0.56 0.68 0.65 0.58 0.56 0.56 0.46 0.47 0.57 0.54 ... $ alcohol : num 9.4 9.8 9.8 9.8 9.4 9.4 9.4 10 9.5 9.2 ... $ quality : chr "LOW" "LOW" "LOW" "HIGH" ...
Dari struktur di atas dapat pula kita lihat terdapat kolom id. kolom ini hanya berisi urutan data dari 1, 2… sampai 1143 sesuai banyaknya data dan bukanlah peubah yang berkaitan dengan kelas data sehingga bisa kita hapus saja. Kita juga sebaiknya merubah tipe dari peubah respon menjadi factor. Hal ini nantinya dapat mempermudah pengukuran pada proses-proses selanjutnya.
Pada kode di bawah ini, kita juga menampilkan banyaknya data serta komposisinya menurut peubah quality. Dari total 1143 observasi, terdapat 621 yang masuk sebagai kelas "HIGH" dan 522 sebagai kelas "LOW". Berdasarkan proporsinya kedua kelas relatif seimbang yaitu dengan komposisi sekitar 54% data dengan kelas "HIGH" berbanding 46% data dengan kelas "LOW".
R
# menghapus kolom `id` data$id <- NULL # mengubah tipe kolom `quality` menjadi factor data$quality <- as.factor(data$quality) # melihat jumlah dan komposisi masing-masing kategori quality <- data.frame(table(data$quality)) quality$Prop <- round(quality$Freq/sum(quality$Freq), 3) print(quality)
# OUTPUT Var1 Freq Prop 1 HIGH 621 0.543 2 LOW 522 0.457
Pembagian Data Latih dan Data Uji
Membagi data menjadi data latih dan data uji merupakan tahapan penting dalam algoritma machine learning termasuk KNN. Pembagian ini diperlukan agar algoritma dapat diuji menggunakan data yang belum pernah dilihat selama proses pelatihan. Pada saat pelatihan, data yang digunakan hanya data latih saja. Adapun data uji nantinya digunakan untuk mengukur performa algoritma. Hal ini penting agar pengukuran performa lebih “fair” karena menggunakan data baru yang belum pernah digunakan untuk proses pelatihan.
Pembagian data pada bahasa R dapat dilakukan menggunakan fungsi createDataPartition dari pustaka caret. Proporsi banyaknya data untuk pelatihan dan pengujian dapat ditentukan dengan mengatur parameter p. Pada contoh ini, kita akan menggunakan 70% dataset sebagai data latih dan 30% sisanya menjadi data uji.
R
# Membagi data sebagai data Latih dan data uji
library(caret)
set.seed(100) # mengatur seed tertentu untuk hasil yang dapat direproduksi
# data latih = 70%, data uji = 30%
trainIndex <- createDataPartition(data$quality, p = 0.70, list = FALSE, times = 1)
# Buat data latih dan data uji berdasarkan indeks yang dihasilkan
data.train <- data[trainIndex, ]
data.test <- data[-trainIndex, ]
# melihat komposisi setiap kelas pada data train dan test
cbind("train" = table(data.train$quality), "test" = table(data.test$quality))# OUTPUT train test HIGH 435 186 LOW 366 156
Features Scaling
KNN merupakan model berbasis jarak sehingga ukuran jarak merupakan hal penting. Perbedaan skala data antar fitur akan mempengaruhi performa model yang dihasilkan. Untuk menghindari hal tersebut, disarankan untuk selalu melakukan scaling terhadap fitur, khususnya ketika perbedaan skala sangat besar. Metode scaling yang dapat digunakan salah satunya adalah normalisasi (MinMax Scaling), yaitu membuat setiap fitur memiliki nilai minimum 0 dan maksimum 1.
Proses scaling pada R dapat menggunakan fungsi preProcess dari pustaka caret. Parameter method="range" menunjukkan scaling dengan metode normalisasi. Dapat dilihat dari output di bawah ini, bahwa fitur hasil scaling seluruhnya memiliki nilai minimum 0 dan maksimum 1.
R
# Menerapkan scaling menggunakan preProcess untuk semua fitur numerik preproc.params <- preProcess(data.train[, -12], method = "range") scaled.data.train <- predict(preproc.params, data.train[, -12]) scaled.data.test <- predict(preproc.params, data.test[, -12]) summary(scaled.data.train)
# OUTPUT fixed.acidity volatile.acidity citric.acid ... alcohol Min. :0.0000 Min. :0.0000 Min. :0.000 ... Min. :0.0000 1st Qu.:0.2091 1st Qu.:0.1849 1st Qu.:0.090 ... 1st Qu.:0.1846 Median :0.2818 Median :0.2740 Median :0.260 ... Median :0.2769 Mean :0.3143 Mean :0.2838 Mean :0.271 ... Mean :0.3124 3rd Qu.:0.3818 3rd Qu.:0.3562 3rd Qu.:0.420 ... 3rd Qu.:0.4154 Max. :1.0000 Max. :1.0000 Max. :1.000 ... Max. :1.0000
KNN dengan paket ‘class’
Untuk membuat prediksi berdasarkan algoritma KNN kita dapat menggunakan fungsi knn dari pustaka class. Fungsi knn langsung menghasilkan output berupa prediksi dari kelas pada data uji yang diberikan. Pada contoh berikut, kita melakukan prediksi data uji berdasarkan data latih dengan mengambil nilai k=5.
R
library(class)
pred.knn <- knn(train=scaled.data.train, test=scaled.data.test,
cl=data.train$quality, k=5)
# Menampilkan hasil prediksi
print(pred.knn)
# Evaluasi hasil prediksi pada data uji
conf_matrix <- confusionMatrix(pred.knn, data.test$quality)
print(conf_matrix)# OUTPUT
[1] LOW LOW LOW LOW LOW LOW LOW LOW LOW LOW LOW LOW HIGH HIGH LOW
[16] LOW LOW LOW LOW HIGH LOW LOW LOW HIGH LOW LOW LOW HIGH LOW HIGH
[31] LOW LOW HIGH HIGH LOW LOW LOW LOW LOW LOW LOW HIGH LOW LOW HIGH
... ...
[301] LOW LOW HIGH LOW HIGH HIGH HIGH HIGH HIGH HIGH LOW HIGH HIGH HIGH HIGH
[316] HIGH LOW HIGH HIGH LOW HIGH HIGH LOW HIGH LOW LOW HIGH HIGH HIGH HIGH
[331] LOW HIGH LOW HIGH LOW HIGH LOW HIGH HIGH HIGH LOW HIGH
Levels: HIGH LOW
Confusion Matrix and Statistics
Reference
Prediction HIGH LOW
HIGH 136 48
LOW 50 108
Accuracy : 0.7135
95% CI : (0.6624, 0.7608)
No Information Rate : 0.5439
P-Value [Acc > NIR] : 9.525e-11
Kappa : 0.4231
Mcnemar's Test P-Value : 0.9195
Sensitivity : 0.7312
Specificity : 0.6923
Pos Pred Value : 0.7391
Neg Pred Value : 0.6835
Prevalence : 0.5439
Detection Rate : 0.3977
Detection Prevalence : 0.5380
Balanced Accuracy : 0.7117
'Positive' Class : HIGH Berdasarkan output di atas, disajikan prediksi kelas dari data uji. Misalkan pada data uji yang pertama diprediksi masuk kelas LOW, data uji kedua masuk kelas LOW sampai dengan data uji terakhir diprediksi masuk sebagai kelas HIGH. Hasil ini selanjutnya dapat dibandingkan dengan kelas sebenarnya pada data uji melalui confusion matrix.
Secara keseluruhan, nilai akurasi prediksi sebesar 0.7135 atau algoritma KNN berhasil memprediksi benar 71,35% dari data uji. Jika dilihat menurut masing-masing kelas, dari 186 data uji dengan kelas HIGH, 136 diprediksi benar, sementara 50 salah. Hasil ini memberikan nilai sensitivity (prediksi benar kelas positif) sebesar 0.7312. Selanjutnya, dari 156 data uji dengan kelas LOW, 108 diprediksi benar dan 48 salah atau memiliki nilai spesifisitas sebesar 0.6923.
KNN dengan paket ‘caret’
Pustaka caret memiliki fungsi train yang dapat dimanfaatkan untuk melakukan iterasi berbagai nilai k. Selain melakukan iterasi, fungsi train juga memungkinkan kita melakukan validasi silang sehingga hasil yang diperoleh bisa lebih dapat dipercaya dan dapat mengurangi kecenderungan overfitting.
Kode berikut ini menunjukkan bagaimana penggunaan fungsi train untuk mencari nilai k terbaik pada algoritma KNN.
R
set.seed(100) # mengatur seed tertentu untuk hasil yang dapat direproduksi
# proses pengukuran menggunakan k-fold cv dengan 5 fold
control = trainControl(method = "cv", number = 5)
# pencarian dilakukan untuk k=1,2,...30
grid = expand.grid(k = 1:30)
knn.grid <- train(x=scaled.data.train,
y=data.train$quality,
method = "knn",
trControl = control,
tuneGrid = grid)
# Menampilkan hasil model
print(knn.grid)# OUTPUT k-Nearest Neighbors 801 samples 11 predictor 2 classes: 'HIGH', 'LOW' No pre-processing Resampling: Cross-Validated (5 fold) Summary of sample sizes: 641, 641, 641, 641, 640 Resampling results across tuning parameters: k Accuracy Kappa 1 0.7116149 0.4161999 2 0.6629037 0.3182158 3 0.6891693 0.3700351 4 0.7054037 0.4034003 5 0.7278882 0.4459112 6 0.7191304 0.4296876 7 0.7315994 0.4553879 8 0.7340994 0.4596629 9 0.7366149 0.4665516 10 0.7291071 0.4512970 11 0.7353649 0.4633416 12 0.7316071 0.4548386 13 0.7341071 0.4596765 14 0.7428804 0.4784521 15 0.7378571 0.4695540 16 0.7341071 0.4616210 17 0.7315916 0.4561245 18 0.7390839 0.4724295 19 0.7378416 0.4698100 20 0.7366071 0.4671681 21 0.7291149 0.4515492 22 0.7303339 0.4536458 23 0.7340683 0.4610520 24 0.7353106 0.4632360 25 0.7240683 0.4405751 26 0.7365683 0.4657745 27 0.7290761 0.4510499 28 0.7278416 0.4488364 29 0.7290994 0.4518120 30 0.7378494 0.4699030 Accuracy was used to select the optimal model using the largest value. The final value used for the model was k = 14.
Hasil di atas menunjukkan bahwa nilai k yang menghasilkan akurasi tertinggi berdasarkan validasi silang adalah k=14 yaitu sebesar 0.74288. Namun, perlu diingat bahwa nilai tersebut adalah berdasarkan data latih. Kita perlu mengukur performa sebenarnya menggunakan data uji seperti sebelumnya. Evaluasi pada data uji menunjukkan nilai akurasi sebesar 0,7251 sementara nilai sensitivity sebesar 0,8280 dan specificity sebesar 0,6026.
R
# Membuat prediksi untuk data uji predictions <- predict(knn.grid, newdata = scaled.data.test) # Evaluasi model conf_matrix <- confusionMatrix(predictions, data.test$quality) print(conf_matrix)
# OUTPUT
Confusion Matrix and Statistics
Reference
Prediction HIGH LOW
HIGH 154 62
LOW 32 94
Accuracy : 0.7251
95% CI : (0.6746, 0.7718)
No Information Rate : 0.5439
P-Value [Acc > NIR] : 4.308e-12
Kappa : 0.4373
Mcnemar's Test P-Value : 0.00278
Sensitivity : 0.8280
Specificity : 0.6026
Pos Pred Value : 0.7130
Neg Pred Value : 0.7460
Prevalence : 0.5439
Detection Rate : 0.4503
Detection Prevalence : 0.6316
Balanced Accuracy : 0.7153
'Positive' Class : HIGH
Selamat mencoba!
API
- Fungsi
knn: knn function – RDocumentation (class) - Fungsi
train: train function – RDocumentation (caret)
Tulisan Lainnya







