Random Forest untuk Model Regresi dengan Python

Random Forest
Random forest adalah salah satu algoritma machine learning yang populer berbasis pohon gabungan (ensemble trees) dan dapat digunakan baik untuk tugas klasifikasi maupun regresi. Setiap pohon keputusan dibangun secara acak dari dataset pelatihan dengan pengambilan sampel secara bootstrap (pengambilan sampel dengan pengembalian). Selain itu pemisahan node pada masing-masing pohon keputusan didasarkan pada beberapa fitur saja yang dipilih secara acak.
Ketika digunakan untuk model regresi, random forest memprediksi nilai peubah respon berupa nilai numerik kontinu. Setiap pohon keputusan yang dibangkitkan akan menghitung nilai prediksinya masing-masing, dan hasil akhirnya adalah rata-rata nilai prediksi dari semua pohon tersebut. Salah satu keunggulan random forest untuk model regresi adalah kemampuannya untuk menangani data yang kompleks dengan baik, serta mengurangi risiko overfitting yang sering terjadi pada pohon keputusan tunggal. Selain itu, random forest memungkinkan kita untuk mengukur tingkat kepentingan setiap fitur dalam membuat prediksi, serta dapat berguna untuk pemahaman yang lebih baik tentang masalah yang sedang dihadapi. Model ini juga cenderung lebih stabil dan memiliki kinerja yang baik bahkan tanpa tuning parameter yang rumit, menjadikannya pilihan yang tepat dalam berbagai kasus regresi.
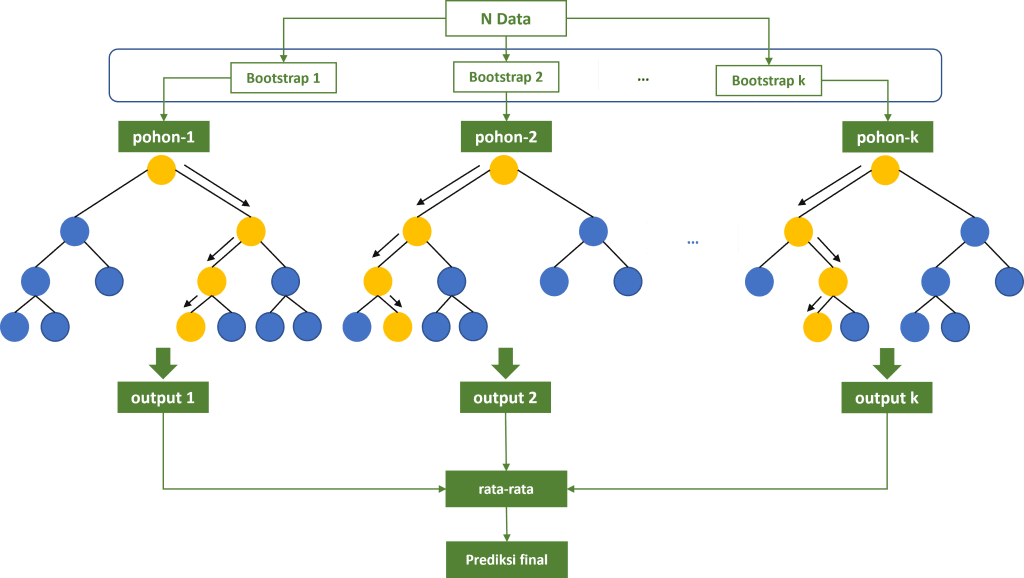
Ilustrasi di atas menunjukkan bagaimana cara kerja model random forest khususnya pada permasalahan regresi. Pertama, tentukan banyaknya pohon keputusan yang akan dibangkitkan. Berikutnya, untuk setiap pohon lakukan penarikan sampel melalui proses bootstrap. Dataset hasil bootstrap selanjutnya diproses sehingga menghasilkan pohon keputusan tunggal dengan output prediksi berupa nilai numerik. Prediksi final dari model random forest dihitung berdasarkan nilai rata-rata prediksi dari seluruh pohon keputusan yang dibangun.
Lihat juga: Random forest untuk model klasifikasi dengan scikit-learn
Setelah memahami bagaimana cara kerja model random forest, pada bagian selanjutnya kita akan menerapkan model random forest untuk model regresi menggunakan bahasa pemrograman python.
Penyiapan Data
Dataset yang akan kita gunakan pada tutorial ini adalah data AirBnB dari beberapa kota utama di Eropa. Dataset ini dapat diunduh dari kaggle pada tautan berikut : Airbnb Prices Euoropean Cities (Merged).
Jika sudah diunduh, sekarang saatnya kita memuat data tersebut agar siap digunakan dalam proses pemodalan. Kita akan menggunakan pustaka pandas untuk membaca serta melakukan beberapa eksplorasi agar memahami data yang dimiliki.
Membaca dataset
Python
import pandas as pd
# membaca dataset
data = pd.read_csv('airbnb_european-cities.csv')
# menampilkan struktur dataset
print("Struktur Data:\n")
print(data.info())
# menampilkan ringkasan data
print(("\nRingkasan data:\n"))
print(data.describe().transpose())Struktur Data:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 51707 entries, 0 to 51706
Data columns (total 15 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 realSum 51707 non-null float64
1 room_type 51707 non-null object
2 room_shared 51707 non-null bool
3 room_private 51707 non-null bool
4 person_capacity 51707 non-null int64
5 host_is_superhost 51707 non-null bool
6 multi 51707 non-null int64
7 biz 51707 non-null int64
8 cleanliness_rating 51707 non-null int64
9 guest_satisfaction_overall 51707 non-null int64
10 bedrooms 51707 non-null int64
11 dist 51707 non-null float64
12 metro_dist 51707 non-null float64
13 city 51707 non-null object
14 weekends 51707 non-null bool
dtypes: bool(4), float64(3), int64(6), object(2)
memory usage: 4.5+ MB
Ringkasan data:
count mean std min 25% 50% 75% max
realSum 51707.0 279.879591 327.948386 34.779339 148.752174 211.343089 319.694287 18545.450285
person_capacity 51707.0 3.161661 1.298545 2.000000 2.000000 3.000000 4.000000 6.000000
multi 51707.0 0.291353 0.454390 0.000000 0.000000 0.000000 1.000000 1.000000
biz 51707.0 0.350204 0.477038 0.000000 0.000000 0.000000 1.000000 1.000000
cleanliness_rating 51707.0 9.390624 0.954868 2.000000 9.000000 10.000000 10.000000 10.000000
guest_satisfaction_overall 51707.0 92.628232 8.945531 20.000000 90.000000 95.000000 99.000000 100.000000
bedrooms 51707.0 1.158760 0.627410 0.000000 1.000000 1.000000 1.000000 10.000000
dist 51707.0 3.191285 2.393803 0.015045 1.453142 2.613538 4.263077 25.284557
metro_dist 51707.0 0.681540 0.858023 0.002301 0.248480 0.413269 0.737840 14.273577 Dari output yang dihasilkan di atas, kita memperoleh beberapa informasi mengenai dataset tersebut. Dataset memiliki jumlah observasi sebanyak 51.707 dan 15 kolom. Masing-masing kolom memiliki tipe data yang bervariasi mulai dari float64, int64, bool serta object. Nantinya setiap kolom akan dilihat lebih detail dan akan kita lakukan proses features engineering jika diperlukan.
Berdasarkan informasi dari halaman dataset ini, kolom realSum merupakan kolom yang berisi harga sewa listing airbnb tersebut. Jika kita lihat dari ringkasan data maka secara rata-rata harga sewa berada pada kisaran 279,88 (katakan dalam euro). Sementara itu melihat sebarannya harga terendah berada pada kisaran 34,78 sedangkan harga tertinggi memiliki nilai yang sangat besar yaitu 18.545,45.
Kolom-kolom lainnya selain realSum merupakan fitur atau peubah penjelas yang akan digunakan unutk memprediksi kisaran harga sewa listing airbnb.
Duplikasi dan Missing Value
Berikutnya kita akan mengecek apakah ada data-data yang duplikat serta apakah ada missing value.
Python
duplikasi = data.duplicated().sum()
missing = data.isna().sum()
print(pd.DataFrame({'Duplikasi': duplikasi,
"Missing": missing}))Duplikasi Missing realSum 0 0 room_type 0 0 room_shared 0 0 room_private 0 0 person_capacity 0 0 host_is_superhost 0 0 multi 0 0 biz 0 0 cleanliness_rating 0 0 guest_satisfaction_overall 0 0 bedrooms 0 0 dist 0 0 metro_dist 0 0 city 0 0 weekends 0 0
Hasil pengecekan data menunjukkan tidak terdapat duplikasi maupun amatan dengan missing value. Oleh karena itu kita akan melanjutkan dengan beberapa pengecekan lainnya.
Eksplorasi Peubah Respon
Seperti yang sempat kita amati sebelumnya, sebaran data pada kolom realSum memiliki variasi yang sangat besar dengan nilai paling rendah pada kisaran 34,78 dan tertinggi mencapai 18.545,45. Adapun nilai rata-rata dan median hanya berada pada kisaran 279,88 dan 211,34. Nilai ini menunjukkan bahwa sebaran data sangat menjulur ke kanan dimana terdapat amatan-amatan ekstrim dengan nilai yang sangat jauh dari nilai lainnya. Untuk itu kita akan mengeksplorasi lebih jauh kolom ini dan jika diperlukan maka akan kita lakukan penanganan.
Python
sns.set(style="darkgrid") fig, axes = plt.subplots(2, 1, figsize=(6, 6), sharex=False) sns.kdeplot(data["realSum"], ax=axes[0], color="darkred") # density plot sns.boxplot(x=data["realSum"], ax=axes[1], linewidth=1, fliersize=1.5) # boxplot plt.show()
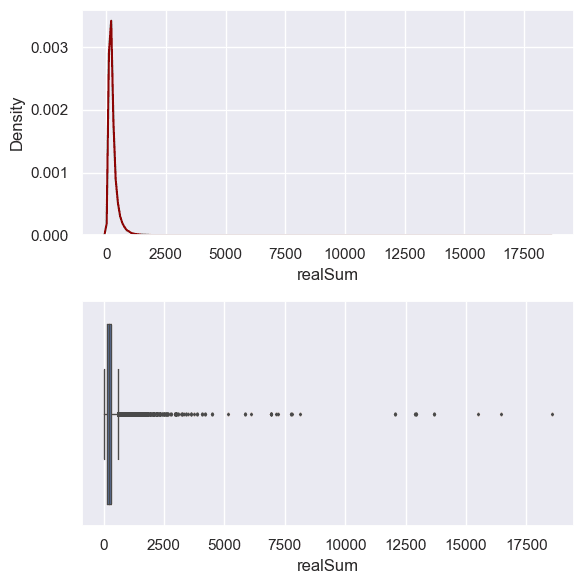
Melalui density plot maupun boxplot di atas, terlihat bahwa sebenarnya sebagian besar data memiliki kisaran harga sewa tidak lebih dari 5.000 atau bahkan tidak lebih dari 2.500. Agar lebih memastikan, maka kita akan mengecek nilai kuantil-kuantil pada data misalkan untuk kuantil 90; 95; 99 dan 99,9.
Python
# Mengecek nilai-nilai kuantil 90, 95, 99, 99.9
print("Kuantil-90 :", data["realSum"].quantile(0.90))
print("Kuantil-95 :", data["realSum"].quantile(0.95))
print("Kuantil-99 :", data["realSum"].quantile(0.99))
print("Kuantil-99.9:", data["realSum"].quantile(0.999))Kuantil-90 : 500.88004895552933 Kuantil-95 : 661.986406077282 Kuantil-99 : 1160.83633199276 Kuantil-99.9: 3000.5545756015094
Nilai-nilai kuantil di atas menunjukkan harga sewa tertinggi pada batas-batas kuantil tersebut. Dari hasil tersebut kita dapatkan informasi bahwa 90% dari seluruh dataset kita memiliki harga sewa tidak lebih dari 500,88. Lebih lanjut, 95% memiliki harga sewa tidak lebih dari 661,99. Bahkan 99% memiliki harga sewa tidak lebih dari 1.160,84 dan 99,9% ternyata memiliki harga sewa tidak lebih dari 3.000,55.
Melihat hasil ini maka harga sewa airbnb dengan nilai yang sangat tinggi mungkin tidak begitu banyak sehingga pada contoh ini akan kita lakukan pemangkasan data dan hanya mengambil 99% data saja (silahkan mencoba mengambil batasan lainnya yang dirasa tepat, misal gunakan 99,9% data). Artinya kita akan membuang 1% data dengan harga yang sangat tinggi, hal ini dilakukan agar model dapat bekerja lebih baik secara umum tanpa terganggu dengan nilai-nilai yang ekstrim namun sebenarnya merupakan kejadian yang sedikit.
Python
# Membuang 1% data dengan harga tertinggi q_99 = data["realSum"].quantile(0.99) data = data[data["realSum"] <= q_99] fig, axes = plt.subplots(2, 1, figsize=(6, 6), sharex=False) sns.kdeplot(data["realSum"], ax=axes[0], color="darkred") # density plot sns.boxplot(x=data["realSum"], ax=axes[1], linewidth=1, fliersize=1.5) # boxplot fig.tight_layout() plt.show()
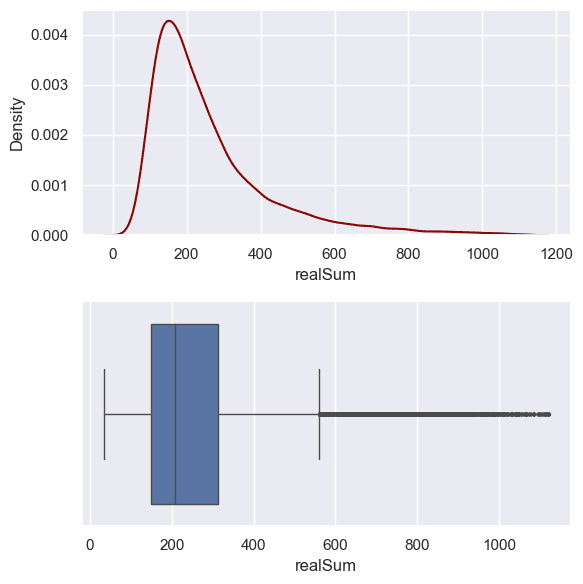
Setelah dilakukan pemangkasan 1% data, kini dataset yang kita miliki sudah lebih merata meskipun masih terdapat kecenderungan menjulur ke arah kanan. Namun kondisi ini bisa dikatakan jauh lebih baik dibandingkan sebelumnya.
Matriks Korelasi untuk Fitur Numerik
Python
import numpy as np
import seaborn as sns
# Menghitung matriks korelasi untuk peubah numerik
corr_matrix = data.select_dtypes(include=['number']).corr()
corr_matrix = round(corr_matrix, 3)
# visualisasi matriks korelasi dengan heatmap
mask = np.triu(np.ones_like(corr_matrix, dtype=bool))
cmap = sns.diverging_palette(230, 20, as_cmap=True)
sns.heatmap(corr_matrix, annot=True, mask=mask,
annot_kws={"fontsize": 8}, linewidths=0.5,
square=True, cmap=cmap)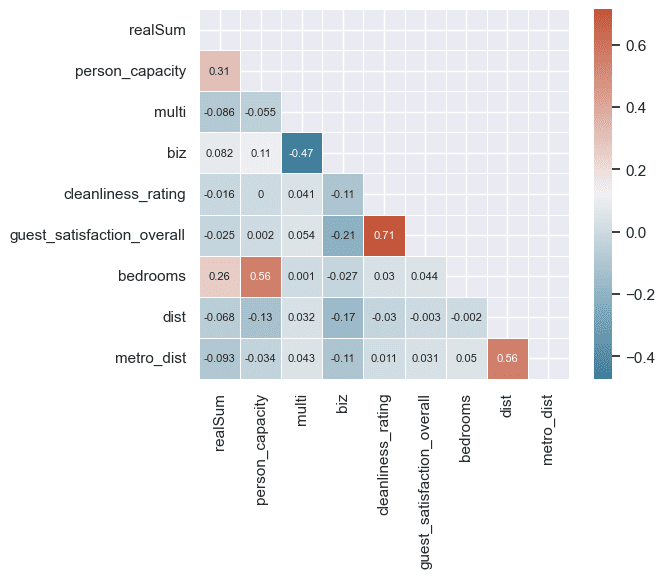
Melihat dari matriks korelasi di atas, tidak begitu terlihat fitur-fitur yang memiliki korelasi tinggi dengan realSum. Dua fitur dengan korelasi yang lumayan adalah person_capicity dan bedrooms. Kedua fitur tersebut cukup wajar memiliki nilai yang lebih tinggi dibandingkan lainnya, dimana memang pada umumnya semakin banyak kapasitas orang yang bisa menginap serta semakin banyak jumlah kamar tidur maka harga sewa cenderung lebih tinggi.
Eksplorasi Fitur kategorik
Jika diperhatikan kolom room_type (object), room_shared (bool), dan room_private (bool) menunjukkan informasi yang nampaknya mirip. Mari kita cek beberapa nilai dari ketiga kolom tersebut.
Python
# Mengecek nilai unik dari kombinasi 3 fitur room_type, room_shared, room_private
cols = ["room_type", "room_shared", "room_private"]
# menampilkan 10 data pertama pada 3 fitur
print(data[cols].head(10))
# menampilkan nilai unik kombinasi 3 fitur
print("\nNilai unik kolom room_type, room_shared, room_private:\n")
print(data[cols].drop_duplicates())
# Menghapus kolom room_shared dan room_private
data = data.drop(columns=["room_shared", "room_private"]) room_type room_shared room_private
0 Private room False True
1 Private room False True
2 Private room False True
3 Private room False True
4 Entire home/apt False False
5 Entire home/apt False False
6 Entire home/apt False False
7 Private room False True
8 Entire home/apt False False
9 Private room False True
Nilai unik kolom room_type, room_shared, room_private:
room_type room_shared room_private
0 Private room False True
4 Entire home/apt False False
63 Shared room True FalseOutput di atas mengindikasikan bahwa kolom room_type saja sudah dapat memberikan informasi yang sama. Dimana, jika room_type bernilai Private room maka kolom romm_shared akan bernilai False dan kolom room_private bernilai True. berikutnya, jika room_type bernilai Entire home/apt maka room_shared dan room_private keduanya bernilai False. Terakhir, ketika room_type bernilai Shared room maka kolom room_shared akan bernilai True dan kolom room_private bernilai False.
Artinya, untuk menyederhanakan kita dapat menghapus kolom room_shared dan room_private karena informasinya sudah terkandung pada kolom room_type. Setelah kedua kolom terssebut dihapus maka tersisa 13 kolom saja pada dataset.
Selanjutnya kita akan melihat secara visual menggunakan boxplot, bagaimana pola persebaran harga sewa airbnb berdasarkan fitur-fitur kategoriknya.
Python
fig, axes = plt.subplots(4, 1, figsize=(8, 8), sharex=False)
sns.boxplot(data=data, x="realSum", y="room_type", linewidth=1,
ax=axes[0], orient="horizontal", fliersize=1.5)
sns.boxplot(data=data, x="realSum", y="host_is_superhost", linewidth=1,
ax=axes[1], orient="horizontal", fliersize=1.5)
sns.boxplot(data=data, x="realSum", y="weekends", linewidth=1,
ax=axes[2], orient="horizontal", fliersize=1.5)
sns.boxplot(data=data, x="city", y="realSum", linewidth=1,
ax=axes[3], fliersize=1.5)
fig.tight_layout()
plt.show()
Jika melihat boxplot di atas, dapat diduga bahwa fitur room_type dan city memiliki sebaran yang berbeda untuk setiap kategorinya. Misalkan pada fitur room_type, kategori Entire home/apt cenderung memiliki harga yang lebih tinggi. Selanjutnya diikuti oleh kategori Private room dengan harga yang lebih rendah serta kategori Shared room cenderung memiliki harga yang paling rendah.
Adapun untuk fitur city, terlihat bahwa kota Amsterdam memiliki kecenderungan harga yang lebih tinggi, kemudian diikuti oleh Paris dan London. Untuk kota-kota lainnya harga sewa umumnya lebih rendah dari ketiga kota tersebut.
Sementara itu, fitur host_is_superhost maupun weekends tampaknya tidak begitu memiliki perbedaan pada setiap kategorinya.
Membuat Model Random Forest
Pembagian Data Latih dan Data Uji
Agar model dapat dievaluasi menggunakan data baru (data yang belum pernah dilihat selama pelatihan), maka dataset akan dibagi menjadi dua bagian. 70% akan digunakan sebagai data latih sementara 30% sebagai data uji. Model random forest nantinya akan dibangun berdasarkan data latih saja. Selanjutnya untuk mengukur performa model maka dilakukan evaluasi berdasarkan kemampuan memprediksi data uji.
Pembagian data dilakukan menggunakan fungsi train_test_split dari module sklearn.model_selection. Selain itu, akrena terdapat beberapa fitur kategorik, maka kita perlu melakukan encoding terlebih dahulu. Terdapat beberapa jenis encoding yang dapat digunakan, namun di sini kita akan menggunakan label encoding dimana setiap kategori akan dilabeli dengan nilai numerik. Untuk melaksanakan pekerjaan tersebut kita dapat menggunakan LabelEncoder dari modul sklearn.preprocessing.
catatan: model-model berbasis pohon termasuk random forest sebenarnya tidak memerlukan encoding fitur kategorik menjadi one-hot-encoding, namun karena scikit-learn hanya dapat menerima input data dalam tipe numerik, maka perlu kita lakukan proses ini.
Python
from sklearn.model_selection import train_test_split
# menentukan kolom fitur dan target
X = data.drop("realSum", axis=1)
y = data["realSum"]
# list kolom boolean
bool_features = X.select_dtypes(include=["boolean"]).columns
# merubah fitur boolean sebagai integer
data[bool_features] = data[bool_features].astype(int)
# list kolom kategorik
cat_features = X.select_dtypes(exclude=["number"]).columns
# merubah fitur kategorik menggunakan one-hot encoding
# (menggunkaan fungsi pandas get_dummies)
oh_room_type = pd.get_dummies(X[["room_type"]], drop_first=True).astype(int)
oh_city = pd.get_dummies(X[["city"]], drop_first=True).astype(int)
# menghapus fitur kategorik dari data
X = X.drop(cat_features, axis=1)
# menggabungkan fitur one-hot encoding ke dalam data
X = pd.concat([X, oh_room_type, oh_city], axis=1)
# membagi data train dan test
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)Pelatihan Model
Untuk membangun model Random Forest kita akan menggunakan fungsi RandomForestRegressor dari modul sklearn.ensemble. Beberapa parameter penting pada model yaitu:
n_estimators: jumlah pohon yang akan digunakan (default = 100)criterion:{“gini”, “entropy”, “log_loss”}, default=”gini”. Parameter ini digunakan untuk menentukan kriteria dalam memperoleh splitting terbaik pada setiap node.max_depth, default=None. Maksimal kedalaman pada setiap pohon.Nonemenunjukkan kedalaman pohon tidak dibatasi (dibatasi menurut kriteria paramater lainnya sepertimin_samples_splitdanmin_samples_leaf.min_samples_split, default=2. Minimal jumlah data pada suatu node agar node tersebut bisa di-split.min_samples_leaf, default=1. Minimal jumlah data pada masing-masingleafagar suatu node bisa di-split.max_features:{“sqrt”, “log2”, None}, default=”sqrt”. Maksimal jumlah features yang digunakan dalam proses penentuan split terbaik pada setiap node.- dll
Pada bagian ini kita gunakan nilai parameter defaultnya. Karena menggunakan nilai default, maka kita harus menentukan nilai-nilai parameter tersebut. Namun pada contoh dibawah ini, hanya unutk memperjelas maka nilai parameter n_estimator=100 akan dituliskan secara eksplisit.
Python
from sklearn.ensemble import RandomForestRegressor # membuat model random forest model_rf = RandomForestRegressor(n_estimators=100, random_state=42, n_jobs=-1) # fitting model model_rf.fit(X_train, y_train)
Evaluasi Model
Setelah memperoleh model, selanjutnya model perlu di-evaluasi menggunakan data baru. Dalam hal ini data uji dimana belum pernah dilihat model dalam proses pelatihan. Untuk melakukan evaluasi, pertama kita perlu melakukan prediksi harga sewa airbnb berdasarkan fitur-fitur pda data uji tersebut. Selanjutnya, hasil prediksi dibandingkan terhadap nilai sebenarnya.
Terdapat banyak metrik untuk mengukur performa model regresi. Beberapa diantaranya yaitu Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE) serta R-Squared. Umumnya kita tidak menggunakan keseluruhan metrik sekaligus, namun untuk alasan demonstrasi pada bagian berikut ini akan ditampilkan nilai-nilai untuk keempat metrik tersebut.
Python
from sklearn.metrics import (
mean_squared_error,
r2_score, mean_absolute_error,
mean_absolute_percentage_error,
)
# Memprediksi data uji
y_pred_rf = model_rf.predict(X_test)
# mengukur performa model pada data uji
print("Performa model:\n")
print("R-Squared:", r2_score(y_test, y_pred_rf))
print("MAE:", mean_absolute_error(y_test, y_pred_rf))
print("RMSE:", mean_squared_error(y_test, y_pred_rf)**0.5)
print("MAPE:", mean_absolute_percentage_error(y_test, y_pred_rf))Performa model: R-Squared: 0.7825872844500951 MAE: 48.1173612764476 RMSE: 78.79045124045312 MAPE: 0.19727643409924533
Tuning Hyperparameter
Grid Search CV
Grid Search adalah sebuah metode dalam machine learning yang digunakan untuk mencari kombinasi terbaik dari hyperparameter model dengan melakukan pencarian secara sistematis dari seluruh kemungkinan kombinasi nilai hyperparameter yang telah ditentukan sebelumnya. Tujuannya adalah untuk menemukan kombinasi hyperparameter yang menghasilkan model terbaik dalam hal kinerja yang diukur dengan metrik yang telah ditentukan tentukan.
Scikit-learn menyediakan fungsi untuk melakukan grid search yaitu melalui kelas GridSearchCV dari modul sklearn.model_selection. Untuk menggunakannya, pertama kita perlu menyiapkan daftar nilai-nilai hyperparameter yang akan dicobakan dalam proses pencarian model terbaik.
Selain model dan nilai-nilai hyperparameter, kita juga dapat menentukan scoring yang digunakan. parameter ini diperlukan untuk mengatur kriteria apa yang digunakan untuk menentukan model terbaik. Pada contoh berikut scoring yang akan kita gunakan adalah neg_mean_squared_error.
note: ukuran scoring pada GridSearchCV untuk model regresi umumnya diawali dengan kata-kata neg_xxx. Hal ini karena di dalam fungsi ini skor yang lebih tinggi akan dianggap yang lebih baik. Sementara, metrik-metrik seperti MSE, RMSE, MAE yang menunjukkan besaran nilai error dimana kita ketahui semakin kecil nilainya maka semakin baik modelnya.
Selain itu, dalam menentukan skor model, dapat dilakukan melalui k-fold CV, sehingga pengukuran tidak dihasilkan hanya berdasarkan 1 kali pelatihan saja (untuk 1 kombinasi parameter), melainkan dari nilai rata-rata skor hasil k-fold CV (jumlah fold yang sering digunakan adalah 5 atau 10).
Python
from sklearn.model_selection import GridSearchCV
# mengatur nilai-nilai hyperparameter yang akan digunakan
param_grid = {
'n_estimators': [100, 200, 500],
'max_depth' : [None, 20, 50],
'min_samples_split' : [2, 5, 10],
'max_features' : [5, 7, 10],
}
# tuning model dengan grid search
rf_cv = GridSearchCV(model_rf,
param_grid=param_grid,
scoring="neg_mean_squared_error",
cv=5,
refit=True,
n_jobs=-1)
# fitting model menggunakan hasil CV
rf_cv.fit(X_train, y_train)
# menampilkan nilai parameter terbaik
print(rf_cv.best_params_){'max_depth': None,
'max_features': 10,
'min_samples_split': 2,
'n_estimators': 500}Evaluasi Model
Seperti sebelumnya, model perlu di-evaluasi menggunakan data uji untuk mengukur performanya pada data baru. Hasil pengecekan menggunakan berbagai metrik tersaji pada output di bawah ini. Dari hasil tuning kita memperoleh performa (khususnya RMSE) yang sedikit lebih baik dibandingkan model sebelumnya. Hasil ini tentunya dapat bervariasi tergantung dari nilai-nilai hyperparameter yang digunakan. Meskipun begitu, perlu dicatat bahwa tidak menutup kemungkinan hasil yang diperoleh tetap tidak sebaik model awalnya.
Python
# Memprediksi data uji
y_pred_cv = rf_cv.predict(X_test)
# mengukur performa model pada data uji
print("Performa model (cv):\n")
print("R-Squared:", r2_score(y_test, y_pred_cv))
print("MAE:", mean_absolute_error(y_test, y_pred_cv))
print("RMSE:", mean_squared_error(y_test, y_pred_cv)**0.5)
print("MAPE:", mean_absolute_percentage_error(y_test, y_pred_cv))Performa model (cv): R-Squared: 0.7836743507901776 MAE: 49.199986566712454 RMSE: 78.59322777291982 MAPE: 0.20272430014793194
Menyimpan dan Memuat Model
Dalam dunia nyata kita mungkin akan melatih model dengan jumlah data yang sangat besar serta parameter yang sangat banyak sehingga memakan waktu yang lama. Tentunya tidak memungkinkan mengulangi langkah yang sama setiap akan menggunakan model. Oleh karena itu dengan menyimpan model yang sudah dilatih, kita dapat menggunakan model tersebut tanpa harus melakukan pelatihan ulang.
Terdapat beberapa cara untuk melakukan proses ini misalkan menggunakan pustaka pickle atau joblib. Di sini kita akan menggunakan fungsi dump dan load pada pustaka joblib. Untuk menyimpan model ke dalam file dilakukan menggunakan fungsi dump. Selanjutnya, jika kita perlu menggunakan model tersebut maka dapat dimuat dengan fungsi load.
Python
from joblib import dump, load
# Menyimpan model ke dalam file
dump(rf_cv, 'model_rf_cv.joblib')
# Membaca model dari file
model_from_file = load('model_rf_cv.joblib')
# Menggunakan model untuk memprediksi
# model_from_file.predict(...)Peubah Penting
Selain melakukan prediksi sering kali kita juga ingin mengetahui fitur-fitur apa saja yang mempunyai pengaruh besar terhadap prediksi model. Istilah ini biasa disebut dengan peubah penting (variabel importance). Terdapat beberapa metode yang dapat digunakan, mulai dari feature importance, permutation importance hingga SHAP. Pada bagian ini, kita akan fokus pada 2 metode pertama karena sudah tersedia secara langsung pada pustaka scikit-learn.
Feature Importance
Feature Importance mengukur seberapa besar kontribusi masing-masing fitur terhadap kualitas prediksi model dengan cara menghitung pentingnya setiap fitur berdasarkan perhitungan internal model. Pada konteks random forest, feature importance mengukur berapa sering dan seberapa dalam sebuah fitur digunakan dalam pembuatan keputusan di seluruh pohon dalam model. Semakin sering sebuah fitur digunakan dalam membuat keputusan, semakin penting fitur tersebut.
Untuk menghitung feature importance khususnya model random forest, kita dapat mengakses atribut feature_importances_ pada model.
Python
feature_importance = rf_cv.best_estimator_.feature_importances_
# mengurutkan indeks dari feature importance
sorted_idx = np.argsort(feature_importance)
pos = np.arange(sorted_idx.shape[0]) + 0.5
# visualisasi feature importance
fig = plt.figure(figsize=(12, 6))
plt.barh(pos, feature_importance[sorted_idx], align="center")
plt.yticks(pos, np.array(X.columns)[sorted_idx])
plt.title("Feature Importance (MDI)")
plt.show()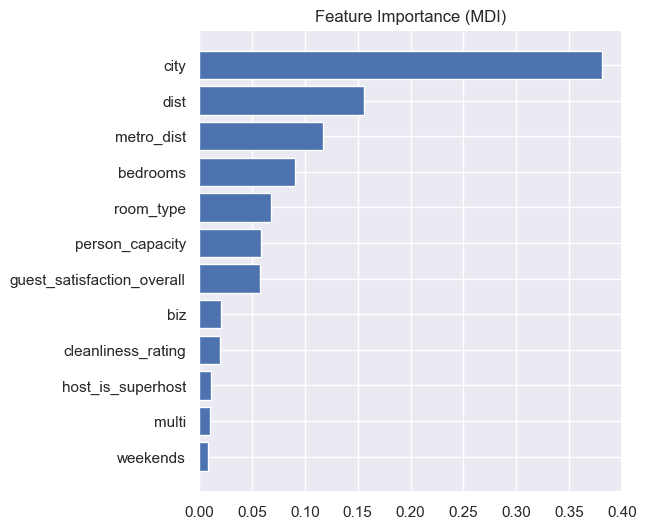
Tingkat kepentingan peubah dapat dilihat berdasarkan besarnya nilai mean Decrease in impurity (MDI). Semakin tinggi nilai MDI menunjukkan bahwa semakin besar tingkat kepentingan fitur tersebut di dalam model. Dari hasil di atas, dapt kita katakan bahwa fitur city memiliki tingkat kepentingan terbesar pada model yang dibangun. Fitur lainnya dengan tingkat kepentingan tinggi berturut-turut yaitu dist, metro_dist, bedrooms dan room_type.
Permutation Importance
Metode lainnya yang biasa digunakan untuk mengukur peubah penting adalah permutation importance. Metode ini mengukur tingkat kepentingan fitur dengan mengacak nilai-nilai suatu fitur dan mengukur dampaknya terhadap kinerja model. Pengacakan ini memberikan pandangan yang lebih objektif tentang bagaimana menghilangkan atau merubah fitur akan memengaruhi kinerja model. Pengacakan pada setiap fitur biasanya dilakukan dalam beberapa kali ulangan. Tingkat kepentingan setiap fitur diukur berdasarkan rata-rata penurunan performa model untuk setiap ulangan tersebut. Karena proses pengukuran dilakukan berulang kali, maka hasilnya dapat dibentuk dalam bentuk selang kepercayaan.
lihat: Permutation Importance dengan scikit-learn
Untuk menghitung permutation importance kita dapat menggunakan fungsi permutation_importance dari modul sklearn.inspection.
Pada kode di bawah ini, kita melakukan penghitungan permutation importance dengan melakukan iterasi sebanyak 50 kali. Artinya setiap fitur dilakukan pengacakan sebanyak 50 kali. Dalam setiap pengacakan akan dihitung seberapa besar penurunan performa model. Nilai akhir untuk masing-asming fitur yaitu rata-rata penurunan performa model berdasarkan 50 kali pengacakan tersebut. Selanjutnya nilai permutation importance dapat ditampilaknda lam bentuk boxplot yang berisi sebaran nilai penurunan performa untuk setiap pengacakan.
Python
from sklearn.inspection import permutation_importance
perm_importance = permutation_importance(
rf_cv.best_estimator_, X, y, n_repeats=50, random_state=42, n_jobs=2
)
sorted_idx = perm_importance.importances_mean.argsort()
# menampilkan hasil permutation pada setiap iterasi
# print(perm_importance.importances[sorted_idx].T)
# visualisasi permutation importance
plt.boxplot(
perm_importance.importances[sorted_idx].T,
vert=False,
labels=np.array(X.columns)[sorted_idx],
)
plt.title("Permutation Importance")
plt.show()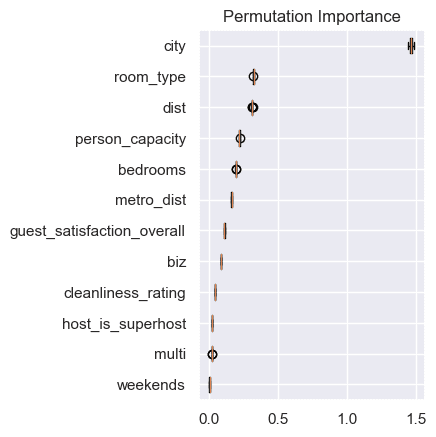
Hasil penghitungan permutation importance pada model menunjukkan bahwa fitur city merupakan fitur yang paling berpengaruh terhadap performa model. Hal ini karena ketika data pada fitur ini diacak maka menyebabkan penurunan paling besar pada performa model. Berdasarkan 50 kali pengacakan terihat bentuk boxplot yang relatif sempit dimana menunjukkan kisaran penuruan performa dalam setiap pengacakan juga relatif sama. Fitur lainnya dengan tingkat kepentingan paling besar berturut-turut adalah room_type, dist, person_capacity dan bedrooms.
Lihat Juga: Model Random Forest untuk Klasifikasi







