Features Scaling dan Implementasinya dengan Python dan R

Features scaling adalah salah satu proses penting yang merupakan bagian dari pra-pemrosesan data dalam machine learning. Tahapan ini bertujuan untuk mengubah rentang atau skala nilai dari fitur-fitur (peubah) dalam dataset sehingga memiliki karakteristik yang serupa antar fitur. Kesamaan skala pada setiap fitur merupakan hal yang penting khususnya ketika kita akan menggunakan algoritma machine learning berbasis jarak, dimana perbedaan skala dapat memberikan hasil yang mungkin tidak diinginkan.
Features scaling membantu algoritma machine learning seperti K-Mean Clustering, K-Nearest Neighbors (KNN) dan Support Vector Machines (SVM) untuk beroperasi dengan lebih baik serta menghasilkan performa yang lebih baik. Selain itu, data yang sudah di-scaling juga dapat mempercepat konvergensi algoritma-algoritma yang berbasis iterasi seperti Gradient Descent pada model Gradient Boosting atau Neural Network.
Dalam pemrosesan data, penting untuk memilih metode scaling yang sesuai dengan karakteristik data yang dimiliki. Pemilihan yang tepat akan membantu meningkatkan kualitas model dan analisis yang dilakukan.
Terdapat dua metode umum yang digunakan dalam features scaling:
- Normalisasi (Min-Max Scaling): mengubah nilai-nilai fitur ke dalam rentang tertentu, biasanya antara (0 dan 1) atau (-1 dan 1).
- Standardisasi (Z-score Scaling): mengubah nilai-nilai fitur sehingga memiliki rataan 0 dan simpangan baku 1.
Sebagai catatan tambahan, perlu diingat bahwa features scaling khususnya menggunakan normalisasi dan standardisasi TIDAK MERUBAH bentuk sebaran data. Bentuk sebaran data asli dengan data hasil scaling akan tetap sama. Perubahan hanya terjadi pada skala data, dimana masing-masing fitur nantinya akan memiliki rentang nilai yang mirip satu sama lainnya.
Setelah memahami apa yang dimaksud dengan features scaling serta tujuannya, selanjutnya kita akan membahas 2 jenis features scaling yang umum digunakan seperti yang telah disebutkan sebelumnya yaitu normalisasi dan standardisasi. Pada dua bagian pertama, kita akan membahas bagaimana formula yang digunakan untuk melakukan normalisasi dan standardisasi pada data. Selanjutnya formula tersebut akan diimplementasikan dalam bahasa python dan R. Selain itu, baik pada python maupun R juga akan ditunjukkan penggunakan pustaka yang sudah tersedia, sehingga proses scaling dapat dilakukan tanpa harus membuat fungsi secara manual.
Normalisasi (Min-Max Scaling)
Normalisasi adalah proses merubah nilai-nilai fitur sedemikian rupa sehingga setiap fitur memiliki rentang skala yang seragam, seringkali dalam rentang (0 dan 1) atau (-1 dan 1). Secara umum features scaling melalui proses normalisasi menggunakan formula sebagai berikut:
$$x_{i.scaled}=\frac{x_i−min(x)}{max(x)−min(x)} [max(x)-min(x)] + min(x)$$
Jika normalisasi dilakukan ke dalam selang [0, 1] maka formula di atas menjadi lebih sederhana yaitu:
$$x_{i.scaled}=\frac{x_i−min(x)}{max(x)−min(x)}$$
Melalui formula di atas misalkan untuk normalisasi dengan selang [0, 1], maka setelah dilakukan normalisasi nilai dari setiap amatan akan berada pada selang nilai tersebut. Data terkecil akan bernilai 0 dan data terbesar akan bernilai 1 serta sisanya berada diantara keduanya.
Sebagai ilustrasi, misal terdapat dataset dengan 5 amatan yaitu $2, 5, 5, 7, 10$. Jika dilakukan normalisasi pada dataset tersebut dengan selang [0, 1], maka data yang baru hasil normalisasi adalah:
$$\frac{2-2}{10-2}, \frac{5-2}{10-2}, \frac{5-2}{10-2}, \frac{7-2}{10-2}, \frac{10-2}{10-2}$$
dan jika dihitung maka hasilnya menjadi $0, 0.375, 0.375, 0.5, 1$. Dari hasil ini, dapat dilihat bahwa nilai amatan terkecil di-scaling sehingga berubah menjadi 0 dan amatan terbesar menjadi 1.
Standardisasi (Z-Score Scaling)
Standardisasi adalah proses merubah nilai-nilai pada fitur sehingga data hasil scaling akan memiliki nilai rata-rata 0 dan simpangan baku (standard deviation) bernilai 1. Adapun formula untuk melakuan standardisasi adalah sebagai berikut:
$$x_{i.scaled}=\frac{x_i−\bar x}{s}$$
dimana $\bar x$ adalah:
$$\bar x=\frac{1}{n}\sum_{i=1}^n x_i$$
dan $s$ adalah:
$$s=\sqrt{\frac{1}{n-1}\sum_{i=1}^n (x_i-\bar x)^2}$$
Melalui formula di atas, maka setiap fitur hasil standardisasi akan memiliki nilai rata-rata 0 dan simpangan baku 1.
Sebagai ilustrasi, dengan menggunakan data yang sama seperti bagian sebelumnya maka langkah untuk melakukan standardisasi adalah sebagai berikut:
$$\bar x = \frac{1}{5}(2 + 5 + 5 + 7 + 10) = 5.8$$
$$s = \sqrt{\frac{1}{5-1}\left[(2-5.8)^2+(5-5.8)^2+ … + (10-5.8)^2\right]} = 2.95 $$
Dari hasil tersebut, maka standaridasasi untuk setiap amatan adalah:
$$\frac{2-5.8}{2.95}, \frac{5-5.8}{2.95}, \frac{5-5.8}{2.95}, \frac{7-5.8}{2.95}, \frac{10-5.8}{2.95}$$
dan diperoleh hasil akhir data yang sudah distandardisasi menjadi $-1.288, -0.271, -0.271, 0.407, 1.424$
Jika dihitung kembali data yang sudah distandardisasi tersebut, maka akan menghasilkan nilai rata-rata 0 serta simpangan baku adalah 1 (karena angka di atas dibulatkan, mungkin hasilnya tidak persis 0 dan 1).
Setelah memahami bagaimana cara kerja dari normalisasi dan standardisasi, kita akan melanjutkan dengan mengimplementasikan formula-formula di atas menggunakan bahasa Python dan R.
Implementasi dengan Python
Pada bagian ini, kita akan membangkitkan 1000 data simulasi secara acak mengikuti berbagai sebaran tertentu. Terdapat 3 peubah yang akan dibangkitkan yaitu X1, X2 dan X3. Peubah X1 akan dibangkitkan mengikuti sebaran Normal, peubah X2 mengikuti sebaran Poisson dan X3 mengikuti sebaran Weibull. Berikutnya akan ditampilkan 10 data pertama untuk masing-masing peubah serta informasi beberapa nilai statistik deskriptifnya, meliputi nilai minimum (min), maksimum (max) serta simpangan baku (std).
Membangkitkan Data Acak
Pembangkitan bilangan acak yang mengikuti sebaran tertentu dapat dilakukan menggunakan bantuan pustaka numpy. Agar hasil pembangkitan dapat di-reproduksi ulang maka kita dapat mengatur nilai random menggunakan fungsi default_rng pada objek np.random. Dengan nilai seed yang sama, maka bilangan acak yang dibangkitkan juga akan selalu sama.
lihat : Membangkitkan Bilangan Acak untuk Sebaran Tertentu dengan Python
Python
import numpy as np
import pandas as pd
# Membuat generator angka acak dengan seed 100
rng = np.random.default_rng(100)
n = 1000
# Membangkitkan 1000 data acak
X1 = rng.normal(50, 6, n) # Normal(mean=50, sd=6)
X2 = rng.poisson(7, n) # Poisson(lambda=7)
X3 = rng.weibull(20, n) # Weibull(alpha=20)
fake_data = pd.DataFrame({
'X1': np.round(X1, 2),
'X2': X2,
'X3': np.round(X3, 1)
})
# Menampilkan 10 data pertama
print(fake_data.head(10))
# Statistik 5 serangkai
print("\nStatistik 5 serangkai:")
print(fake_data.describe()) X1 X2 X3
0 43.05 6 1.1
1 51.74 11 0.9
2 54.69 7 1.0
3 53.26 5 1.0
4 44.23 9 1.1
5 56.43 8 1.0
6 54.21 5 1.0
7 54.23 8 1.1
8 54.47 4 1.0
9 56.63 10 0.9
Statistik 5 serangkai:
X1 X2 X3
count 1000.000000 1000.000000 1000.000000
mean 50.265150 6.932000 0.972300
std 6.056269 2.599641 0.067433
min 32.770000 0.000000 0.700000
25% 46.037500 5.000000 0.900000
50% 50.295000 7.000000 1.000000
75% 54.432500 9.000000 1.000000
max 70.560000 16.000000 1.100000Dapat dilihat dari output di atas, data acak yang kita bangkitkan memiliki skala yang berbeda-beda antara peubah X1, X2 dan X3. Misalkan pada X1 memiliki rentang nilai antara 32.77 hingga 70.56 dengan rata-rata 50.265. Adapun untuk X2 memiliki rentang nilai antara 0.0 hingga 16 dengan nilai rata-rata 6.93. begitu pula untuk X3 memiliki rentang nilai dari 0.70 sampai dengan 1.10 dengan rata-rata 0.07. Dari data yang sudah dibangkitkan tersebut, selanjutnya akan kita coba melakukan scaling menggunakan normalisasi dan standardisasi.
Fungsi Normalisasi (manual)
Berikut ini adalah fungsi minmax_scaling yang kita buat untuk melakukan normalisasi data. Selanjutnya fungsi ini diterapkan untuk setiap kolom pada dataframe fake_data menggunakan metode apply. Data hasil normalisasi selanjutnya disimpan pada variabel fake_data_nmz.
Dapat dilihat dari output sintaks di bawah ini, hasil normalisasi pada ketiga peubah membuat skala data ketiganya menjadi berubah. Pada data aslinya, seperti yang sudah disampaikan sebelumnya terdapat perbedaan skala untuk setiap peubahnya. Namun pada data hasil normalisasi nilai minimum untuk masing-masing peubah adalah sama yaitu 0, begitu pula untuk nilai maksimumnya yaitu 1.
Python
# membuat fungsi Normalisasi (Min-Max)
# (dengan nilai default min=0 dan max=1,
# namun dapat berlaku umum untuk min-max berapapun)
def minmax_scaling(data, min_val=0, max_val=1):
min_data = np.min(data)
max_data = np.max(data)
data_minmax = (data - min_data) / (max_data - min_data) * (max_val - min_val) + min_val
return data_minmax
# Contoh Normalisasi (0 dan 1)
fake_data_nmz = fake_data.apply(minmax_scaling)
# Statistik 5 serangkai
print(fake_data_nmz.describe())X1 X2 X3 count 1000.000000 1000.000000 1000.000000 mean 0.462957 0.433250 0.680750 std 0.160261 0.162478 0.168583 min 0.000000 0.000000 0.000000 25% 0.351085 0.312500 0.500000 50% 0.463747 0.437500 0.750000 75% 0.573234 0.562500 0.750000 max 1.000000 1.000000 1.000000
Fungsi Standardisasi (Manual)
Mirip dengan sebelumnya, di sini kita membuat fungsi std_scaling yang digunakan untuk melakukan standardisasi data. Dengan cara yang sama, fungsi ini diterapkan untuk setiap kolom pada dataframe fake_data menggunakan metode apply dan disimpan pada variabel baru yaitu fake_data_std. Dapat dilihat bahwa pada data yang sudah dilakukan standardisasi ketiga peubahnya memiliki nilai rata-rata yang sama yaitu 0 serta simpangan baku 1.
Python
# Fungsi Standardisasi
def std_scaling(data):
mean_data = np.mean(data) # Rata-rata data
std_data = np.std(data, ddof=1) # untuk sd sampel, set parameter ddof=1
data_std = (data - mean_data) / std_data # Standardisasi
return data_std
# Contoh standardisasi
fake_data_std = fake_data.apply(std_scaling)
# Statistik 5 serangkai
print(np.round(fake_data_std.describe(), 5))X1 X2 X3 count 1000.00000 1000.00000 1000.00000 mean 0.00000 -0.00000 -0.00000 std 1.00000 1.00000 1.00000 min -2.88877 -2.66652 -4.03806 25% -0.69806 -0.74318 -1.07217 50% 0.00493 0.02616 0.41078 75% 0.68811 0.79549 0.41078 max 3.35105 3.48817 1.89372
Fungsi MinMaxScaler dan StandarScaler
Pustaka sklearn menyediakan fungsi/objek MinMaxScaler yang dapat digunakan untuk proses normalisasi serta StandarScaler untuk proses standardisasi data. Output yang dihasilkan menggunakan kedua fungsi tersebut juga tentunya akan sama dengan apa yang sudah kita lakukan secara manual pada bagian sebelumnya. (Sebagai catatan, pada fungsi StandarScaler nilai simpangan baku yang digunakan adalah formula untuk data populasi, sehingga nilai simpangan baku yang ditampilkan dengan metode describe mungkin tidak akan persis bernilai 1)
Python
from sklearn.preprocessing import MinMaxScaler, StandardScaler
# Normalisasi (0-1)
scaler = MinMaxScaler()
normalized = scaler.fit_transform(fake_data)
print("Normalisasi (0-1):\n")
print(pd.DataFrame(normalized, columns=fake_data.columns).describe())
# Standardisasi
scaler = StandardScaler()
standardized = scaler.fit_transform(fake_data)
print("\nStandardisasi:\n")
print(pd.DataFrame(standardized, columns=fake_data.columns).describe())Normalisasi (0-1):
X1 X2 X3
count 1000.000000 1000.000000 1000.000000
mean 0.462957 0.433250 0.680750
std 0.160261 0.162478 0.168583
min 0.000000 0.000000 0.000000
25% 0.351085 0.312500 0.500000
50% 0.463747 0.437500 0.750000
75% 0.573234 0.562500 0.750000
max 1.000000 1.000000 1.000000
Standardisasi:
X1 X2 X3
count 1.000000e+03 1.000000e+03 1.000000e+03
mean 1.428191e-15 -1.101341e-16 -5.897505e-16
std 1.000500e+00 1.000500e+00 1.000500e+00
min -2.890212e+00 -2.667856e+00 -4.040082e+00
25% -6.984111e-01 -7.435514e-01 -1.072706e+00
50% 4.931243e-03 2.617054e-02 4.109815e-01
75% 6.884495e-01 7.958925e-01 4.109815e-01
max 3.352725e+00 3.489919e+00 1.894669e+00Implementasi pada R
Sama seperti yang sudah dilakukan menggunakan python, pada bagian ini kita akan mencoba membangkitkan 3 peubah dengan nama X1, X2, dan X3 secara acak. peubah X1 akan mengikuti sebaran Normal, X2 mengikuti sebaran Poisson dan X3 mengikuti sebaran Weibull. banyaknya amatan yang akan dibangkitkan pada masing-masing sebaran adalah sebanyak 1000 amatan.
Dari data tersebut, selanjutnya akan dilakukan normalisasi dan standardisasi pada ketiga peubahnya. Proses ini akan dilakukan secara manual, namun akan ditampilkan pula alternatif menggunakan fungsi preProcess yang sudah tersedia pada package caret.
Membangkitkan Data Acak
Di dalam bahasa R, kita dapat membangkitkan daa mengikuti sebaran tertentu menggunakan fungsi r.... Pada contoh ini yaitu rnom untuk membangkitkan data yang menyebar normal, rpois untuk membangkitkan data yang mengikuti sebaran Poisson dan rweibull untuk data yang mengikuti sebaran Weibull. Kita juga dapat mengatur seed menggunakan fungsi set.seed agar bilangan acak yang dihasilkan dapat di-reproduksi kembali.
lihat : Pembangkitan Bilangan Acak pada Bahasa R
R
# mengatur seed agar dapat di-reproduksi
set.seed(111)
n = 1000
# Membangkitan 1000 data acak
X1 <- rnorm(n, mean=50, sd=6) # Normal(mean=50, sd=6)
X2 <- rpois(n, lambda=7) # Poisson(lambda=7)
X3 <- rweibull(n, shape=20) # Weibull(alpha=7)
# Menggabungkan vektor-vektor menjadi data frame
fake.data <- data.frame(
X1=round(X1, 2), # pembulatan agar tidak banyak angka desimal
X2=X2,
X3=round(X3, 1)) # pembulatan agar tidak banyak angka desimal
# 10 data pertama
head(fake.data, 10)
# statistik 5 serangkai
summary(fake.data)
# simpangan baku
cat("\nSimpangan Baku :\n")
lapply(fake.data, sd)# 10 data pertama
X1 X2 X3
1 51.41 5 0.9
2 48.02 4 1.0
3 48.13 9 0.9
4 36.19 5 1.0
5 48.97 6 1.0
6 50.84 10 1.0
7 41.02 1 1.0
8 43.94 17 1.0
9 44.31 8 0.9
10 47.04 11 1.1
X1 X2 X3
Min. :30.06 Min. : 1.000 Min. :0.7000
1st Qu.:46.08 1st Qu.: 5.000 1st Qu.:0.9000
Median :50.12 Median : 7.000 Median :1.0000
Mean :50.06 Mean : 6.884 Mean :0.9735
3rd Qu.:54.05 3rd Qu.: 8.000 3rd Qu.:1.0000
Max. :67.56 Max. :20.000 Max. :1.1000
Simpangan Baku :
$X1 5.92765272741722
$X2 2.56263753018469
$X3 0.0661220244859617Berdasaran informasi nilai minimun, maksimum, rata-rata serta simpangan baku pada setiap peubah X1, X2 dan X3, terlihat bahwa masing-masing memiliki perbedaan skala. Informasi ini nantinya akan kita bandingkan dengan data hasil normalisasi dan standardisasi.
Fungsi Normalisasi (manual)
Dapat dilihat dari output sintaks di bawah ini data hasil normalisasi memiliki skala data yang seragam. Masing-masing peubah memiliki nilai minimum yang sama yaitu 0 serta nilai minimum yang juga sama yaitu 1.
R
# membuat fungsi Normalisasi (Min-Max)
# (dengan nilai default min=0 dan max=1,
# namun dapat berlaku umum untuk min-max berapapun)
minmax.scaling <- function(data, min=0, max=1) {
min.data <- min(data)
max.data <- max(data)
data.minmax <- (data - min.data)/(max.data-min.data) * (max - min) + min
data.minmax
}
# contoh Min-Max scaling (0 dan 1)
fake.data.nmz = data.frame(sapply(fake.data, minmax.scaling))
# statistik 5 serangkai
summary(fake.data.nmz)X1 X2 X3 Min. :0.0000 Min. :0.0000 Min. :0.0000 1st Qu.:0.4271 1st Qu.:0.2105 1st Qu.:0.5000 Median :0.5349 Median :0.3158 Median :0.7500 Mean :0.5335 Mean :0.3097 Mean :0.6837 3rd Qu.:0.6399 3rd Qu.:0.3684 3rd Qu.:0.7500 Max. :1.0000 Max. :1.0000 Max. :1.0000
Fungsi Standardisasi (Manual)
Serupa dengan proses normalisasi, berdasarkan output sintaks di bawah ini dapat dilihat bahwa setiap peubah pada data hasil normalisasi memiliki nilai rata-rata yang sama yaitu 0 serta simpangan baku yang sama pula yaitu 1.
R
# membuat fungsi Standardisasi
std.scaling <- function(data) {
mean.data <- mean(data) # rata-rata data
sd.data <- sd(data) # simpangan baku data
data.std <- (data - mean.data)/sd.data # standardisasi
data.std
}
# contoh
fake.data.std = data.frame(sapply(fake.data, std.scaling))
summary(fake.data.std)
cat("\nSimpangan Baku :\n")
lapply(fake.data.std, sd)X1 X2 X3 Min. :-3.374843 Min. :-2.29607 Min. :-4.1363 1st Qu.:-0.672678 1st Qu.:-0.73518 1st Qu.:-1.1116 Median : 0.009295 Median : 0.04527 Median : 0.4008 Mean : 0.000000 Mean : 0.00000 Mean : 0.0000 3rd Qu.: 0.673133 3rd Qu.: 0.43549 3rd Qu.: 0.4008 Max. : 2.951438 Max. : 5.11816 Max. : 1.9131 Simpangan Baku : $X1 1 $X2 1 $X3 1
Fungsi preProcess
Package caret menyediakan fungsi preProcess yang dapat digunakan untuk transformasi data termasuk didalamnya features scaling dengan normalisasi dan standardisasi. Output yang dihasilkan menggunakan fungsi preProcess juga sama dengan apa yang sudah kita lakukan secara manual pada bagian sebelumnya.
R
library(caret)
# Normalisasi (0 dan 1) dengan mengatur parameter method="range"
preprocessParams <- preProcess(fake.data, method="range")
normalized <- predict(preprocessParams, fake.data)
cat("Normalisasi (0-1):\n\n")
summary(normalized)
# Standardisasi dengan mengatur parameter method=c("center", "scale")
preprocessParams <- preProcess(fake.data, method=c("center", "scale"))
standardized <- predict(preprocessParams, fake.data)
cat("\nStandardisasi:\n\n")
summary(standardized)
cat("\nSimpangan baku :\n")
lapply(standardized, sd)Normalisasi (0-1):
X1 X2 X3
Min. :0.0000 Min. :0.0000 Min. :0.0000
1st Qu.:0.4271 1st Qu.:0.2105 1st Qu.:0.5000
Median :0.5349 Median :0.3158 Median :0.7500
Mean :0.5335 Mean :0.3097 Mean :0.6837
3rd Qu.:0.6399 3rd Qu.:0.3684 3rd Qu.:0.7500
Max. :1.0000 Max. :1.0000 Max. :1.0000
Standardisasi:
X1 X2 X3
Min. :-3.374843 Min. :-2.29607 Min. :-4.1363
1st Qu.:-0.672678 1st Qu.:-0.73518 1st Qu.:-1.1116
Median : 0.009295 Median : 0.04527 Median : 0.4008
Mean : 0.000000 Mean : 0.00000 Mean : 0.0000
3rd Qu.: 0.673133 3rd Qu.: 0.43549 3rd Qu.: 0.4008
Max. : 2.951438 Max. : 5.11816 Max. : 1.9131
Simpangan baku :
$X1 1
$X2 1
$X3 1Sebaran Data Asli vs Scaled Data
Banyak pandangan keliru mengenai efek dari features scaling khususnya standardisasi. Sebagian berpendapat bahwa proses ini akan merubah bentuk sebaran data menjadi sebaran normal baku. Namun hal tersebut sangatlah keliru, proses scaling menggunakan normalisasi maupun standardisasi tidak akan merubah bentuk sebaran data. Data yang menyebar normal akan tetap normal, begitu pula data yang menjulur (skewed) akan tetap menjulur persis sama seperti bentuk sebaran data aslinya.
Untuk menunjukkan hal tersebut, pada bagian ini, akan diperlihatkan baik secara visual maupun melalui uji kenormalan (Shapiro-Wilk), bahwa proses normalisasi dan standardisasi sedikitpun tidak merubah bentuk sebaran data. (Pada bagian ini kita akan menggunakan data yang diperoleh menggunakan R)
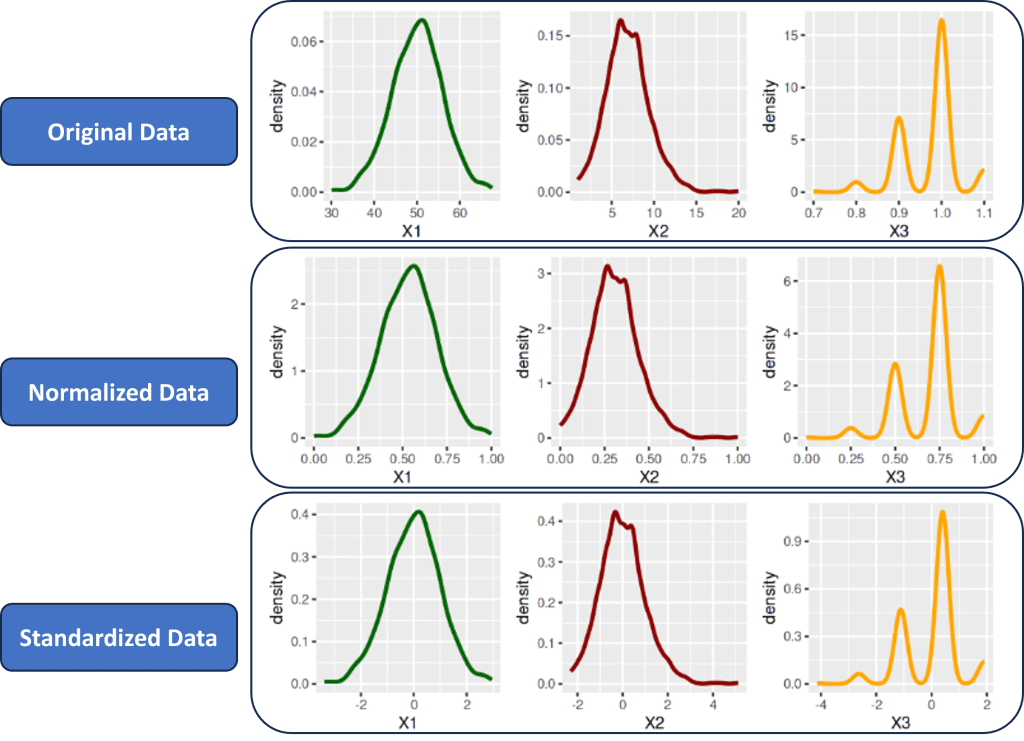
Density Plot
Density plot merupakan salah satu alat eksplorasi dimana kita dapat melihat bentuk sebaran dari sekumpulan data. Pada sintaks berikut ini kita menyandingkan density plot dari ketiga peubah (X1, X2 dan X3) untuk data asli, data yang dinormalisasi serta data yang distandardisasi.
Berdasarkan visualisasi density plot untuk masing-masing data tersebut, dapat dengan jelas dilihat bahwa distribusi setiap peubah memiliki bentuk yang sama persis dan hanya skala data saja yang berubah pada data yang sudah dinormalisasi dan distandardisasi.
R
library(ggplot2)
library(gridExtra)
# Density Plot for original data
plot1 <- ggplot(fake.data, aes(x = X1)) +
geom_density(lwd=1, color="darkgreen")
plot2 <- ggplot(fake.data, aes(x = X2)) +
geom_density(lwd=1, color="darkred")
plot3 <- ggplot(fake.data, aes(x = X3)) +
geom_density(lwd=1, color="orange")
# Density Plot for normalized data
plot4 <- ggplot(fake.data.nmz, aes(x = X1)) +
geom_density(lwd=1, color="darkgreen")
plot5 <- ggplot(fake.data.nmz, aes(x = X2)) +
geom_density(lwd=1, color="darkred")
plot6 <- ggplot(fake.data.nmz, aes(x = X3)) +
geom_density(lwd=1, color="orange")
# Density Plot for standardized data
plot7 <- ggplot(fake.data.std, aes(x = X1)) +
geom_density(lwd=1, color="darkgreen")
plot8 <- ggplot(fake.data.std, aes(x = X2)) +
geom_density(lwd=1, color="darkred")
plot9 <- ggplot(fake.data.std, aes(x = X3)) +
geom_density(lwd=1, color="orange")
# grid 3 * 3
grid.arrange(
plot1, plot2, plot3, # (original data)
plot4, plot5, plot6, # (normalized data)
plot7, plot8, plot9, # (standardized data)
ncol = 3
)
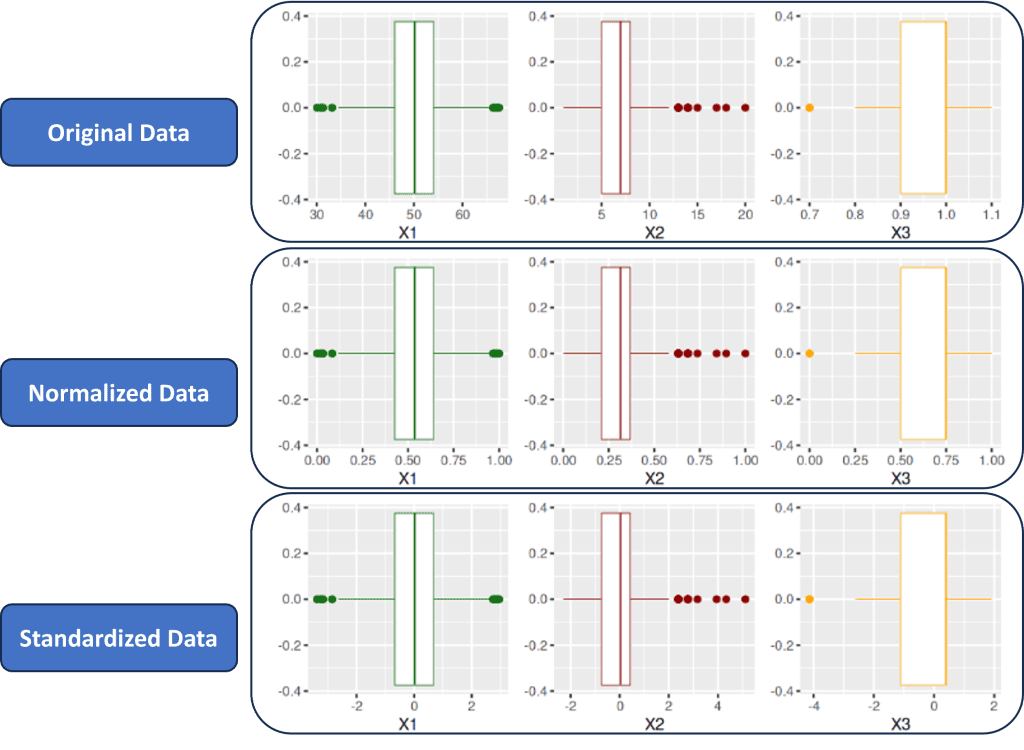
Boxplot
Selain menggunakan density plot, kita juga dapat melihat secara visual sebaran data menggunakan boxplot. Untuk itu pada bagian ini kita akan melakukan hal yang serupa seperti sebelumnya, yaitu menyandingkan boxplot untuk masing-masing data.
Melalui hasil boxplot kita juga dapat menunjukkan bahwa sebaran data hasil scaling baik menggunakan normalisasi maupun standardisasi tetap sama persis seperti data aslinya. Hal ini terlihat dari bentuk kotak dan garis, lokasi nilai kuartil hingga posisi data-data outlier secara visual menunjukkan hasil yang sama.
R
# Box Plot Data Asli
plot1 <- ggplot(fake.data, aes(x = X1)) +
geom_boxplot(lwd=0.2, color="darkgreen")
plot2 <- ggplot(fake.data, aes(x = X2)) +
geom_boxplot(lwd=0.2, color="darkred")
plot3 <- ggplot(fake.data, aes(x = X3)) +
geom_boxplot(lwd=0.2, color="orange")
# Box Plot Scaled Data (Normalized 0-1)
plot4 <- ggplot(fake.data.nmz, aes(x = X1)) +
geom_boxplot(lwd=0.2, color="darkgreen")
plot5 <- ggplot(fake.data.nmz, aes(x = X2)) +
geom_boxplot(lwd=0.2, color="darkred")
plot6 <- ggplot(fake.data.nmz, aes(x = X3)) +
geom_boxplot(lwd=0.2, color="orange")
# Box Plot Scaled Data (Standardized)
plot7 <- ggplot(fake.data.std, aes(x = X1)) +
geom_boxplot(lwd=0.2, color="darkgreen")
plot8 <- ggplot(fake.data.std, aes(x = X2)) +
geom_boxplot(lwd=0.2, color="darkred")
plot9 <- ggplot(fake.data.std, aes(x = X3)) +
geom_boxplot(lwd=0.2, color="orange")
# grid 3 * 3
grid.arrange(
plot1, plot2, plot3, # (original data)
plot4, plot5, plot6, # (normalized data)
plot7, plot8, plot9, # (standardized data)
ncol = 3
)
Uji Saphiro-Wilk
“Mata dapat menipu”, mungkin sebagian akan mengatakan tampilan secara visual mungkin hanya mirip namun bisa jadi tidak sama persis. Oleh karena itu, untuk menunjukkan kesamaan sebaran data antara data asli dan data hasil scaling kita dapat menggunakan uji-uji kenormalan misalkan uji Saphiro-Wik.
Pada bagian ini, dilakukan uji Saphiro-Wilk terhadap ketiga peubah X1, X2, X3 untuk data original, data yang sudah dinormalisasi serta data yang sudah distandardisasi. Dari hasil diperoleh untuk X1 yang mana memang dibangkitkan menggunakan sebaran normal, maka uji Shapiro-Wilk menghasilkan nilai p-value yang besar sehingga kite menerima H0, sehingga dapat dikatakan bahwa X1 menyebar normal. Hasil ini sama persis antara data original, data normalisasi dan juga data standardisasi, sehingga jelas sekali walaupun dilakukan scaling sebaran data tetap sama.
Beralih pada X2, dimana data ini dibangkitkan mengikuti sebaran Poisson. Sebaran ini secara umum menjulur ke kanan. Hasil uji Shapiro-Wilk untuk data original, data normalisasi dan standardisasi juga menghasilkan nilai statistik uji yang sama yaitu 0.97045 serta nilai p-value yang sama yaitu < 2.226e-12 dengan keputusan tolak H0 atau data tidak menyebar Normal.
Hasil yang sama juga terjadi pada X3 yang dibangkitkan mengikuti sebaran Weibull. Uji Shapiro-Wilk memberikan nilai statistik uji yang sama yaitu 0.78632 dan nilai p-value yang sama yaitu < 2.2e-16 sehingga keputusan juga tolak H0 yang artinya data tidak menyebar normal.
R
# X1 (norm)
cat("SHAPIRO-WILK TEST FOR X1:\n")
shapiro.test(fake.data$X1)
shapiro.test(fake.data.nmz$X1)
shapiro.test(fake.data.std$X1)
cat("\n=================================\n\n")
# X2 (Chi-Square)
cat("SHAPIRO-WILK TEST FOR X2:\n")
shapiro.test(fake.data$X2)
shapiro.test(fake.data.nmz$X2)
shapiro.test(fake.data.std$X2)
cat("\n==================================\n\n")
# X3 (Weibull)
cat("SHAPIRO-WILK TEST FOR X3:\n")
shapiro.test(fake.data$X3)
shapiro.test(fake.data.nmz$X3)
shapiro.test(fake.data.std$X3)
cat("\n==================================\n\n")SHAPIRO-WIL TEST FOR X1: data: fake.data$X1 W = 0.99843, p-value = 0.5077 data: fake.data.nmz$X1 W = 0.99843, p-value = 0.5077 data: fake.data.std$X1 W = 0.99843, p-value = 0.5077 ================================= SHAPIRO-WIL TEST FOR X2: data: fake.data$X2 W = 0.97405, p-value = 2.226e-12 data: fake.data.nmz$X2 W = 0.97405, p-value = 2.226e-12 data: fake.data.std$X2 W = 0.97405, p-value = 2.226e-12 ================================== SHAPIRO-WIL TEST FOR X3: data: fake.data$X3 W = 0.78632, p-value < 2.2e-16 data: fake.data.nmz$X3 W = 0.78632, p-value < 2.2e-16 data: fake.data.std$X3 W = 0.78632, p-value < 2.2e-16 ==================================
Ringkasan
Features Scaling merupakan tahapan penting dalam banyak model machine learning dimana kita merubah skala nilai data sehingga mengikuti kriteria tertentu. Dua contoh features scaling yang sering digunakan adalah normalisasi dan standardisasi. Normalisasi mengubah skala data sehingga berada pada selang nilai tertentu, misalkan [0, 1] atau [-1, 1]. Adapun standardisasi merubah skala data sehingga memiliki nilai rata-rata 0 dan simpangan baku 1.
Salah satu konsep penting yang seringkali keliru yaitu anggapan bahwa proses scaling (khususnya standardisasi) akan mengubah sebaran data menjadi normal baku. Berdasarkan bukti visual maupun uji formal yang sudah dilakukan, dapat dipastikan konsep ini adalah keliru. Sehingga dapat kita katakan bahwa proses normalisasi dan standardisasi TIDAK MERUBAH bentuk sebaran data. Sebaran data akan tetap sama persis seperti aslinya. Perbedaannya hanya pada skala dari data tersebut.







