Neural Network untuk Klasifikasi Multikelas dengan Keras

Neural network adalah model matematika yang terinspirasi oleh struktur dan fungsi otak manusia. Proses pembelajaran neural network melibatkan pelatihan model dari dataset yang diberikan, di mana bobot koneksi antar neuron disesuaikan dan diperbarui untuk menghasilkan prediksi yang lebih akurat. Dalam beberapa tahun terakhir, neural network telah menghasilkan kemajuan signifikan di berbagai bidang, termasuk pengenalan gambar, pemrosesan bahasa alami, dan prediksi data.
Terdapat berbagai pustaka yang dapat digunakan untuk membangun model neural network, salah satunya adalah Keras (dan TensorFlow). Pertama kali diluncurkan, Keras dibuat sebagai backend Theano, namun sejak versi 2.0, Keras juga mendukung backend TensorFlow. Pada versi 2.3.0, Keras telah terintegrasi dengan TensorFlow dan menjadi bagian dari paket TensorFlow. Keras menyediakan antarmuka yang lebih sederhana dan mudah digunakan daripada TensorFlow atau Theano yang lebih low-level, sehingga memungkinkan pengguna lebih mudah dan cepat dalam membangun model deep learning.
Instalasi Keras dan Tensorflow
Seperti yang sudah disampaikan sebelumnya, Keras saat ini sudah terintegrasi dengan TensorFlow sehingga dengan menginstal Tensorflow maka Keras akan otomatis ikut terinstal. Jika anda menggunakan pip maka untuk menginstal tensorflow dapat dilakukan dengan sintaks seperti berikut:
# jika mengunakan jupyter notebook (tambahkan simbol % sebelum pip) # instalasi tensorflow # pip install tensorflow # instalasi paket pendukung lainnya # pip install pandas numpy scikit-learn
Jika perangkat mendukung GPU maka anda dapat menginstall tensorflow dengan dukungan GPU. Panduan lengkap instalasi dapat dilihat pada tautan berikut https://www.tensorflow.org/install/pip.
Pustaka lainnya yang diperlukan dalam tutorial ini adalah pandas, numpy dan scikit-learn. Ketiganya dapat diinstal menggunakan pip seperti contoh di atas.
Penyiapan Data
Data yang digunakan pada tutorial ini dapat diunduh di sini yang merupakan versi modifikasi dari data obesity level. Pada data asli kelas target memiliki 7 kategori, sedangkan yang digunakan di sini, sudah dikelompokkan menjadi 4 kategori saja.
Data set ini terdiri dari 2.111 amatan dengan 16 fitur. Terdapat 9 fitur bertipe kategorik dan 8 fitur numerik. Peubah Nobeyesdad merupakan peubah target bertipe kategorik dengan 4 kelas yaitu Insufficient, Normal, Overweight, Obesity. Sementara untuk fitur-fitur kategorik memiliki kategori dari 2 hingga 5 kategori. Tidak terdapat missing value sehingga proses dapat dilanjutkan ke tahap berikutnya.
Python
import pandas as pd
# memuat data CSV
data = pd.read_csv("obesitas.csv")
# menampilkan info data
print(data.info())
# menampilkan label dari kelas target
print(data["NObeyesdad"].unique())Output
<class 'pandas.core.frame.DataFrame'> RangeIndex: 2111 entries, 0 to 2110 Data columns (total 17 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Gender 2111 non-null object 1 Age 2111 non-null float64 2 Height 2111 non-null float64 3 Weight 2111 non-null float64 4 family_history_with_overweight 2111 non-null object 5 FAVC 2111 non-null object 6 FCVC 2111 non-null float64 7 NCP 2111 non-null float64 8 CAEC 2111 non-null object 9 SMOKE 2111 non-null object 10 CH2O 2111 non-null float64 11 SCC 2111 non-null object 12 FAF 2111 non-null float64 13 TUE 2111 non-null float64 14 CALC 2111 non-null object 15 MTRANS 2111 non-null object 16 NObeyesdad 2111 non-null object dtypes: float64(8), object(9) memory usage: 280.5+ KB None ['Normal' 'Overweight' 'Obesity' 'Insufficient']
Praproses Data
Ada beberapa proses yang harus dilakukan agar data dapat digunakan dalam pemodelan neural network dengan keras yaitu:
- Menentukan Kolom-kolom fitur dan kolom target
- Merubah fitur bertipe kategorik menjadi numerik. Hal ini penting karena proses pemodelan hanya bekerja pada data numerik sehingga data kategorik harus diubah terlebih dahulu. Salah satu cara yang paling mudah yaitu merubah fitur menjadi One Hot Encoding (OHE) menggunakan fungsi
get_dummiesdaripandas. - Menggabungkan kembali fitur numerik dengan fitur kategorik yang sudah di-encoding.
- Membagi data latih dan data uji. Data latih akan menjadi dasar untuk pelatihan model dan menentukan model yang optimal. Data uji digunakan untuk mengevaluasi kinerja model pada data yang belum pernah dilihat. Di sini kita membagi data 75% sebagai data latih dan 25% sebagai data uji. Proses ini dapat dilakukan menggunakan fungsi
train_test_splitdari modulsklearn.model_selection. - Merubah peubah target menjadi numerik. Kita akan menggunakan fungsi
LabelEncoderdari modulsklearn.preprocessing, dimana dari 4 kelas respon dirubah menjadi numerik dengan nilai 0, 1, 2, dan 3. - Features scaling, langkah ini untuk membuat semua fitur yang ada memiliki skala nilai yang sama. Beberapa teknik yang dapat digunakan yaitu Standardize (merubah skala sehingga memiliki rata-rata 0 dan standar deviasi 1) dan Normalize (Min Max Scaling, merubah skala sehingga berada pada rentang nilai tertentu, misal (0 sampai 1) atau (-1 sampai 1). Kita akan menggunakan fungsi
StandardScalerdari modulsklearn.preprocessinguntuk proses standardize.
Python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler, LabelEncoder
# menentukan kolom fitur dan target
X = data.drop(["NObeyesdad"], axis=1)
y = data["NObeyesdad"]
# list kolom kategorik
cat_features = [
"Gender",
"family_history_with_overweight",
"FAVC",
"CAEC",
"SMOKE",
"SCC",
"CALC",
"MTRANS",
]
# list kolom numerik
num_features = X.columns[~X.columns.isin(cat_features)]
# merubah fitur kategorik menjadi One Hot Encoding
X_cat = pd.get_dummies(X[cat_features], drop_first=True)
# mengabungkan kembali fitur numerik dan OHE
X_final = pd.concat([X[num_features], X_cat], axis=1)
# membagi data train dan test
X_train, X_test, y_train, y_test = train_test_split(
X_final, y, test_size=0.25, random_state=123
)
# merubah kelas label menjadi numerik
lenc = LabelEncoder()
lenc.fit(y_train)
y_train = lenc.transform(y_train)
y_test = lenc.transform(y_test)
# merubah skala fitur (menggunakan standardisasi)
scaler = StandardScaler()
scaler.fit(X_train)
X_train = scaler.transform(X_train)
X_test = scaler.transform(X_test)Langkah-langkah pembuatan model neural network dengan 1 hidden layer:
- Menginisiasi model menggunakan fungsi
Sequentialdari modulkeras.models. - Menambah sebuah hidden layer pada model dengan fungsi
Densedari modulkeras.layers. Beberapa parameter yang dapat diatur:-
units: banyaknya neuron pada layer tersebut -
activation: fungsi aktivasi yang digunakan misalkan"relu". input_dim: Jika kita tidak menentukan input layer secara eksplisit, maka pada hidden layer yang pertama, kita dapat menentukan dimensi dari input layer tersebut melalui parameter ini yang menunjukkan jumlah fitur yang digunakan. Contoh data yang kita gunakan terdapat 16 fitur (sebanyak jumlah kolom pada variabelX_train).
-
- Menambah output layer menggunakan fungsi
Dense.units: jumlah neuron pada output layer harus sesuai dengan banyaknya kelas dari peubah target, dalam hal ini adalah 4 kelas.activation: fungsi aktivasi yang dapat digunakn untuk klasifikasi multikelas adalahsoftmax.
- Mengompilasi model dengan memanggil method
compilepada model. Beberapa parameter yang dapat diatur :optimizer: algoritma yang digunakan untuk mencari solusi optimum. Optimizer yang sering digunakan karena memiliki performa efisien, stabil serta adaptif yaitu"adam". Contoh lainya SGD, Adamax dan sebagainya.loss: Loss function yang sesuai untuk data multikelas yaitucategorical_crossentropyatausparse_categorical_crossentropy. Jika label data dalam bentuk integer biasa gunakansparse_categorical_crossentropynamun jika label tersimpan dalam bentuk OHE gunakancategorical_cross_entropy.metrics: Ukuran untuk menghitung performa model. Pada model klasifikasi, metrik yang umum digunakan adalahaccuracy. Kita dapat menggunakan beberapa metrik sekaligus dengan menambahkan metrik lainnya ke dalam list.
- Melatih model dengan memanggil method
fit.Selain menentukan data fitur dan target, kita dapat mengatur beberapa parameter lainnya antara lain:epochs: Parameter ini mengatur banyaknya proses iterasi pembaruan bobot pada neural network. Satu epoch merujuk pada satu kali proses pelatihan yang melibatkan penyebaran seluruh data latih pada neural network untuk menghitung gradien dan memperbarui bobot jaringan.validation_split: jika parameter ini ditentukan (maka pada setiap epoch data latih akan dibagi, dimana sebagiannya digunakan sebagai validasi. Misal :0.2)
- Evaluasi model pada data uji
Python
from keras.models import Sequential
from keras.layers import Dense
# Membangun model neural network
model_1 = Sequential()
# hidden layer
model_1.add(Dense(units=64, input_dim=X_train.shape[1], activation="relu"))
# output layar : unit=4 (sebanyak kelas output)
model_1.add(Dense(units=4, activation="softmax"))
# Mengompilasi model
model_1.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
# Melatih model
model_1.fit(
X_train,
y_train,
epochs=10,
validation_split=0.2,
)
print(model_1.summary())
# Evaluasi model pada data test
loss, accuracy = model_1.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)Output
Epoch 1/10
40/40 [==============================] - 1s 6ms/step - loss: 1.2502 - accuracy: 0.4621 - val_loss: 1.0602 - val_accuracy: 0.5615
Epoch 2/10
40/40 [==============================] - 0s 2ms/step - loss: 0.9558 - accuracy: 0.5940 - val_loss: 0.8803 - val_accuracy: 0.6215
Epoch 3/10
40/40 [==============================] - 0s 2ms/step - loss: 0.8065 - accuracy: 0.6485 - val_loss: 0.7714 - val_accuracy: 0.6593
Epoch 4/10
40/40 [==============================] - 0s 2ms/step - loss: 0.7110 - accuracy: 0.6967 - val_loss: 0.6930 - val_accuracy: 0.6877
Epoch 5/10
40/40 [==============================] - 0s 2ms/step - loss: 0.6420 - accuracy: 0.7275 - val_loss: 0.6345 - val_accuracy: 0.7161
...
Epoch 9/10
40/40 [==============================] - 0s 2ms/step - loss: 0.4710 - accuracy: 0.8357 - val_loss: 0.4921 - val_accuracy: 0.8265
Epoch 10/10
40/40 [==============================] - 0s 2ms/step - loss: 0.4408 - accuracy: 0.8483 - val_loss: 0.4679 - val_accuracy: 0.8517
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 64) 1536
dense_1 (Dense) (None, 4) 260
=================================================================
Total params: 1,796
Trainable params: 1,796
Non-trainable params: 0
_________________________________________________________________
None
17/17 [==============================] - 0s 1ms/step - loss: 0.4855 - accuracy: 0.8258
Loss: 0.4855416715145111
Accuracy: 0.8257575631141663Hasil pelatihan pada model_1 setelah 10 epoch dapat dilihat pada output di atas. Terdapat 4 nilai yang ditampilkan yaitu loss, accuracy, val_loss, dan val_accuracy. Dua nilai terakhir tersedia karena kita mengatur parameter validation_split saat memanggil method fit. Nilai akurasi model saat pelatihan pada epoch ke-10 sebesar 0.8483 dengan nilai akurasi pada porsi data validasi sebesar 0.8517.
Selanjutnya model_1 kita evaluasi menggunakan data uji dimana diperoleh nilai akurasi sebesar 0.8257. Nilai ini relatif tinggi, namun kita akan coba barangkali performa model lebih meningkat lagi.
Beberapa cara yang dapat kita lakukan untuk memperbaiki performa model yaitu dengan mengatur jumlah hidden layer serta jumlah units pada setiap hidden layer. Tidak ada aturan tegas mengenai banyaknya hidden layer maupun units yang tepat. Semua sangat tergantung dengan kondisi data. Hal terpenting adalah memastikan model tidak terlalu rumit sehingga dapat mengakibatkan overfitting.
Kode di bawah ini pada dasarnya mirip dengan kode untuk model_1. Perbedaannya adalah pada model ini (model_2) kita menambahkan 1 hidden layer lagi. Adapun struktur neural network yang kita bangun yaitu pada hidden layer pertama terdiri dari 64 neuron (units) dan pada hidden layer ke-2 memiliki 32 neuron. Pada hidden layer ke-2, kita tidak perlu menentukan parameter input_dim karena input yang masuk adalah sebanyak units pada layer sebelumnya.
Satu hal lain yang juga kita ubah adalah jumlah epoch. Jika sebelumnya kita set sebanyak 10, pada model_2 dibuat menjadi 50. Silahkan untuk mencoba jumlah lainnya misal 100, 200 ataupun yang lainnya.
Python
from keras.models import Sequential
from keras.layers import Dense
# Membangun model neural network
model_2 = Sequential()
# hidden layer ke-1
model_2.add(Dense(units=64, input_dim=X_train.shape[1], activation="relu"))
# hidden layer ke-2
model_2.add(Dense(units=32, activation="relu"))
# output layar : unit=4 (sebanyak kelas output)
model_2.add(Dense(units=4, activation="softmax"))
# Mengompilasi model
model_2.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
# Melatih model
model_2.fit(
X_train,
y_train,
epochs=50,
validation_split=0.2,
)
print(model_2.summary())
# Evaluasi model pada data test
loss, accuracy = model_2.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)Output
Epoch 1/50
40/40 [==============================] - 1s 5ms/step - loss: 1.2077 - accuracy: 0.4463 - val_loss: 0.9441 - val_accuracy: 0.5868
Epoch 2/50
40/40 [==============================] - 0s 2ms/step - loss: 0.8241 - accuracy: 0.6517 - val_loss: 0.7424 - val_accuracy: 0.6498
Epoch 3/50
40/40 [==============================] - 0s 3ms/step - loss: 0.6641 - accuracy: 0.7291 - val_loss: 0.6245 - val_accuracy: 0.7129
Epoch 4/50
40/40 [==============================] - 0s 4ms/step - loss: 0.5578 - accuracy: 0.7915 - val_loss: 0.5448 - val_accuracy: 0.7823
Epoch 5/50
40/40 [==============================] - 0s 3ms/step - loss: 0.4728 - accuracy: 0.8357 - val_loss: 0.4767 - val_accuracy: 0.8328
...
Epoch 48/50
40/40 [==============================] - 0s 3ms/step - loss: 0.0115 - accuracy: 0.9976 - val_loss: 0.1255 - val_accuracy: 0.9495
Epoch 49/50
40/40 [==============================] - 0s 3ms/step - loss: 0.0092 - accuracy: 1.0000 - val_loss: 0.1320 - val_accuracy: 0.9527
Epoch 50/50
40/40 [==============================] - 0s 3ms/step - loss: 0.0085 - accuracy: 0.9992 - val_loss: 0.1256 - val_accuracy: 0.9527
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_14 (Dense) (None, 64) 1536
dense_15 (Dense) (None, 32) 2080
dense_16 (Dense) (None, 4) 132
=================================================================
Total params: 3,748
Trainable params: 3,748
Non-trainable params: 0
_________________________________________________________________
None
17/17 [==============================] - 0s 1ms/step - loss: 0.1217 - accuracy: 0.9602
Loss: 0.1217188686132431
Accuracy: 0.9602272510528564Hasil pelatihan pada model_2 menunjukkan nilai yang jauh lebih tinggi dari model_1. pada proses sampai epoch ke-2\50, terlihat nilai akurasi data validasi val_accuracy adalah sebesar 0.9527. Demikian pula ketika dievaluasi menggunakan data uji, akurasi model_2 adalah sebesar 0,9602. Nilai ini bermakna model_2 mampu mengklasifikasikan dengan benar sebanyak 96,02 persen dari data uji.
Menambah Layer Dropout
Layer Dropout adalah salah satu teknik regularisasi yang digunakan dalam neural network untuk mencegah overfitting. Dropout bekerja dengan cara secara acak menonaktifkan (menghapus) sejumlah neuron pada layer di dalam proses pelatihan.
Berikut adalah cara kerja layer Dropout:
- Selama pelatihan, dalam setiap iterasi atau batch data, layer Dropout secara acak memilih sejumlah neuron untuk dihapus dengan probabilitas p. Probabilitas ini dapat diatur sebagai parameter. Nilai
p=0.1menunjukkan bahwa setiap neuron memiliki peluang sebesar 0.1 untuk dinonaktifkan pada iterasi tersebut. - Setelah pemilihan acak, unit-unit yang dihapus ditandai sebagai tidak aktif atau tidak berkontribusi dalam perhitungan selama iterasi tersebut. Dalam arti, output dari unit-unit ini tidak dikirim ke layer berikutnya dan gradien tidak dihitung untuk unit-unit ini.
- Proses penghapusan unit secara acak ini memiliki efek samping yaitu membuat setiap unit harus menjadi lebih tangguh dan independen dari unit-unit lain dalam jaringan. Ini dapat mendorong jaringan untuk mengembangkan fitur-fitur yang lebih robust dan tidak tergantung pada unit-unit tertentu.
- Ketika fase prediksi atau pengujian, semua unit dalam layer Dropout diaktifkan kembali. Namun, bobot dari unit-unit yang dihapus selama pelatihan akan dikurangi dengan faktor (1 – p) untuk menjaga konsistensi antara fase pelatihan dan fase prediksi.
Dengan menggunakan Dropout, neural network cenderung menjadi lebih tahan terhadap overfitting karena unit-unit yang dihapus secara acak memaksa jaringan untuk tidak bergantung terlalu banyak pada unit-unit tertentu. Ini membantu meningkatkan generalisasi pada data yang belum pernah dilihat sebelumnya.
Perlu dicatat bahwa layer Dropout harus digunakan secara bijak dengan pertimbangan yang tepat tergantung pada kompleksitas model serta data yang digunakan.
Python
from keras.models import Sequential
from keras.layers import Dense, Dropout
# Membangun model neural network
model_3 = Sequential()
# hidden layer ke-1
model_3.add(Dense(units=64, input_dim=X_train.shape[1], activation="relu"))
# dropout layer
model_3.add(Dropout(0.1))
# hidden layer ke-2
model_3.add(Dense(units=32, activation="relu"))
# dropout layer
model_3.add(Dropout(0.1))
# output layar : unit=4 (sebanyak kelas output)
model_3.add(Dense(units=4, activation="softmax"))
# Mengompilasi model
model_3.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
# Melatih model
model_3.fit(
X_train,
y_train,
epochs=50,
validation_split=0.2,
)
print(model_3.summary())
# Evaluasi model pada data test
loss, accuracy = model_3.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)Output
Epoch 1/50
40/40 [==============================] - 1s 6ms/step - loss: 1.2839 - accuracy: 0.4439 - val_loss: 1.0820 - val_accuracy: 0.5584
Epoch 2/50
40/40 [==============================] - 0s 3ms/step - loss: 0.9724 - accuracy: 0.5995 - val_loss: 0.8513 - val_accuracy: 0.5931
Epoch 3/50
40/40 [==============================] - 0s 3ms/step - loss: 0.7985 - accuracy: 0.6572 - val_loss: 0.7075 - val_accuracy: 0.6688
Epoch 4/50
40/40 [==============================] - 0s 3ms/step - loss: 0.6664 - accuracy: 0.7188 - val_loss: 0.6010 - val_accuracy: 0.7476
Epoch 5/50
40/40 [==============================] - 0s 3ms/step - loss: 0.5720 - accuracy: 0.7709 - val_loss: 0.5269 - val_accuracy: 0.7950
...
Epoch 48/50
40/40 [==============================] - 0s 3ms/step - loss: 0.0503 - accuracy: 0.9842 - val_loss: 0.1017 - val_accuracy: 0.9621
Epoch 49/50
40/40 [==============================] - 0s 3ms/step - loss: 0.0433 - accuracy: 0.9874 - val_loss: 0.0991 - val_accuracy: 0.9590
Epoch 50/50
40/40 [==============================] - 0s 3ms/step - loss: 0.0426 - accuracy: 0.9850 - val_loss: 0.0829 - val_accuracy: 0.9653
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_17 (Dense) (None, 64) 1536
dropout_6 (Dropout) (None, 64) 0
dense_18 (Dense) (None, 32) 2080
dropout_7 (Dropout) (None, 32) 0
dense_19 (Dense) (None, 4) 132
=================================================================
Total params: 3,748
Trainable params: 3,748
Non-trainable params: 0
_________________________________________________________________
None
17/17 [==============================] - 0s 3ms/step - loss: 0.1163 - accuracy: 0.9489
Loss: 0.11632095277309418
Accuracy: 0.9488636255264282Dari output di atas, nilai akurasi model_3 pada saat epoch ke-50 untuk data validasi mencapai 0.9563. Evaluasi dengan data uji juga memberikan nilai akurasi yang tinggi yaitu mencapai 0.9489.
Checkpoint dan Early Stopping
Checkpoint adalah fitur untuk menyimpan model ke dalam file selama proses pelatihan berlangsung. Kita dapat menentukan kriteria bagaimana checpoint dilakukan. beberapa parameter pada ModelCheckpoint adalah sebagai berikut:
filepath: path dan nama file untuk menyimpan modelmonitor: menunjukkan nilai apa yang digunakan untuk membuat checkpointmode: menunjukkan nilai mana yang menjadi indikator untuk dimonitor. Misal, jikamonitormenggunakanval_accuracymaka tentu saja nilai yang lebih tinggi adalah yang lebih baik sehingga kita menggunakanmax. Sebaliknya jika monitor mengunakanlosstentu nilai yang lebih kecil lebih baik dan kita dapat mengaturmode="min". Nilai defaultmodeadalah"auto"dimanakerasakan menentukan nilai yang tetap sesuaimonitor.save_best_only: ketika parameter ini disetTruemaka setiap epoch, akan dicek nilai yang dimonitor, jika nilai pada epoch sekarang lebih baik dari sebelumnya, maka file sebelumnya akan ditimpa dengan model berdasarkan epoch yang sekarang.
Early Stoping dilakukan menggunakan fungsi EarlyStopping. Terdapat dua parameter utama yaitu monitor dan patience. Pada dasarnya, fungsi ini memonitor hasil setiap epoch berdasarkan parameter monitor. Misal diset monitor=val_accuracy dan patience=10, maka fungsi akan mengecek nilai val_accuracy pada setiap epoch dan seandainya hingga 10 epoch berikutnya nilai ini tidak meningkat maka proses pelatihan akan dihentikan tanpa menunggu seluruh epoch selesai.
Untuk menerapkan kedua fungsi ini ke dalam model yang akan dilatih, kita harus mengatur parameter callbacks pada method fit.
Python
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras.callbacks import ModelCheckpoint, EarlyStopping
from keras.optimizers import Adam
# menentukan nama dan path file untuk penyimpanan model
filepath = "model_check.h5"
# mengatur kriteria checkpoint
checkpoint = ModelCheckpoint(
filepath=filepath,
monitor="val_accuracy",
save_best_only=True,
mode="max",
verbose=1,
)
# mengatur kondisi untuk early stopping
early_stopping = EarlyStopping(
monitor="val_accuracy",
patience=10,
verbose=1,
)
# Membangun model neural network
model_4 = Sequential()
# hidden layer ke-1
model_4.add(Dense(units=64, input_dim=X_train.shape[1], activation="relu"))
# dropout layer
model_4.add(Dropout(0.1))
# hidden layer ke-2
model_4.add(Dense(units=32, activation="relu"))
# dropout layer
model_4.add(Dropout(0.1))
# output layar : unit=4 (sebanyak kelas output)
model_4.add(Dense(units=4, activation="softmax"))
# Mengompilasi model
model_4.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"],
)
# Melatih model
model_4.fit(
X_train,
y_train,
epochs=50,
validation_split=0.2,
callbacks=[checkpoint, early_stopping], # mengatur checkpoint dan early stopping
)Output
Epoch 1/50 33/40 [=======================>......] - ETA: 0s - loss: 1.2333 - accuracy: 0.4640 Epoch 1: val_accuracy improved from -inf to 0.58360, saving model to model_check.h5 40/40 [==============================] - 1s 8ms/step - loss: 1.2094 - accuracy: 0.4810 - val_loss: 0.9926 - val_accuracy: 0.5836 Epoch 2/50 36/40 [==========================>...] - ETA: 0s - loss: 0.9047 - accuracy: 0.6207 Epoch 2: val_accuracy improved from 0.58360 to 0.65300, saving model to model_check.h5 40/40 [==============================] - 0s 5ms/step - loss: 0.8899 - accuracy: 0.6256 - val_loss: 0.7686 - val_accuracy: 0.6530 Epoch 3/50 21/40 [==============>...............] - ETA: 0s - loss: 0.7519 - accuracy: 0.6711 Epoch 3: val_accuracy improved from 0.65300 to 0.70978, saving model to model_check.h5 40/40 [==============================] - 0s 5ms/step - loss: 0.7259 - accuracy: 0.6809 - val_loss: 0.6274 - val_accuracy: 0.7098 Epoch 4/50 22/40 [===============>..............] - ETA: 0s - loss: 0.6607 - accuracy: 0.7287 Epoch 4: val_accuracy improved from 0.70978 to 0.76656, saving model to model_check.h5 40/40 [==============================] - 0s 5ms/step - loss: 0.6125 - accuracy: 0.7551 - val_loss: 0.5441 - val_accuracy: 0.7666 Epoch 5/50 21/40 [==============>...............] - ETA: 0s - loss: 0.5415 - accuracy: 0.7917 Epoch 5: val_accuracy improved from 0.76656 to 0.79495, saving model to model_check.h5 40/40 [==============================] - 0s 5ms/step - loss: 0.5395 - accuracy: 0.7907 - val_loss: 0.4789 - val_accuracy: 0.7950 ... Epoch 44/50 32/40 [=======================>......] - ETA: 0s - loss: 0.0563 - accuracy: 0.9844 Epoch 44: val_accuracy did not improve from 0.96845 40/40 [==============================] - 0s 3ms/step - loss: 0.0566 - accuracy: 0.9842 - val_loss: 0.1029 - val_accuracy: 0.9621 Epoch 45/50 33/40 [=======================>......] - ETA: 0s - loss: 0.0687 - accuracy: 0.9811 Epoch 45: val_accuracy did not improve from 0.96845 40/40 [==============================] - 0s 3ms/step - loss: 0.0661 - accuracy: 0.9818 - val_loss: 0.1076 - val_accuracy: 0.9621 Epoch 45: early stopping
Pada output di atas, dapat kita lihat saat nilai val_accuracy meningkat maka model akan disimpan dalam file "model_check.h5". Selanjutnya dapat dilihat juga, pada epoch ke-45, tampak nilai val_accuracy tidak meningkat dibandingkan 10 epoch sebelumnya. Oleh karena itu, proses pelatihan otomatis berhenti tanpa menunggu sampai epoch ke-50.
Masih dari kode di atas, kita dapat menggunakan model_4 untuk melakukan evaluasi atau prediksi. Namun kita dapat juga memuat model yang sudah tersimpan. Model dapat kita akses menggunakan fungsi load_model dari modul keras.models. Setelah model dimuat, kita dapat melakukan prediksi, evaluasi ataupun melakukan pelatihan kembali (penambahan epoch).
Python
from keras.models import load_model
# Memuat model yang disimpan dalam file
model_from_file = load_model("model_check.keras")
# model dapat digunakan kembali untuk prediksi, evaluasi atau pelatihan
loss, accuracy = model_from_file.evaluate(X_test, y_test)
print("Loss:", loss)
print("Accuracy:", accuracy)Output
17/17 [==============================] - 0s 1ms/step - loss: 0.1190 - accuracy: 0.9527 Loss: 0.11901430785655975 Accuracy: 0.9526515007019043
Prediksi Data
Sebelumnya kita sudah menggunakan data uji sebagai dasar evaluasi model, namun kita belum pernah benar-benar melihat hasil prediksi model pada data uji. Memprediksi data uji dapat dilakukan memanggil method predict. Output dari method predict berupa nilai probabilitas setiap amatan untuk masuk ke kelas.
Setiap amatan akan masuk ke dalam kelas yang mana peluangnya masuk kelas tersebut adalah tertinggi dibandingkan masuk kelas lainnya. Agar daapt menentukan kelas prediksinya, kita dapat menggunakan bantuan funsgi argmax dari pustaka numpy . Dengan mengatur parameter axis=1, fungsi argmax akan mengembalikan indeks kolom yang memilki nilai tertinggi.
Hasil prediksi juga dapat ditampilkan dalam bentuk confusion matrix. Kita dapat menampilkan confusion matrix menggunakan fungsi confusion_matrix dari modul sklearn.metrics. Jika ingin menampilkan dalam bentuk visual maka dapat menggunakan ConfussionMatrixDisplay dengan tambahan pustaka matplotlib.
Python
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# ingat variabel lenc (encoding peubah target)
# label asli dapat diakses pada atribut classes_
print(lenc.classes_)
# Evaluasi model pada data test
loss, accuracy = model_5.evaluate(X_test, y_test)
# melihat prediksi pada data test
y_pred = model_4.predict(X_test)
# Mengkonversi prediksi menjadi label kelas
y_pred_class = np.argmax(y_pred, axis=1)
# Menampilkan hasil prediksi
print(y_pred_class)
# memvisualisasikan confusion matrix
disp = ConfusionMatrixDisplay(
confusion_matrix(y_pred_class, y_test), display_labels=lenc.classes_
)
disp.plot()
plt.show()Output
['Insufficient' 'Normal' 'Obesity' 'Overweight'] 17/17 [==============================] - 0s 1ms/step - loss: 0.1190 - accuracy: 0.9527 17/17 [==============================] - 0s 1ms/step # output dalam bentuk peluang [[1.18677307e-22 6.68677624e-13 9.99999642e-01 3.28039988e-07] [1.32066503e-04 5.14231980e-01 6.05750689e-03 4.79578465e-01] [7.84581403e-07 4.64998605e-03 9.22671519e-03 9.86122549e-01] ... [3.23932694e-13 5.31596129e-07 9.97674882e-01 2.32454971e-03] [1.51934853e-06 1.29436925e-02 2.20790016e-03 9.84846950e-01] [2.35353610e-07 3.05640721e-03 1.25635946e-02 9.84379768e-01]] # merubah output menjadi kelas dengan peluang tertinggi [2 1 3 2 2 2 3 2 2 2 2 3 2 3 1 2 3 2 3 3 3 2 3 2 3 2 3 0 2 3 2 2 2 2 0 3 2 1 2 2 3 3 3 2 1 2 2 2 0 0 2 2 3 2 3 2 0 2 2 2 3 3 3 2 3 2 3 0 3 2 2 2 1 0 2 1 2 2 0 2 0 2 2 0 3 3 3 0 2 0 2 2 2 2 2 2 3 2 3 2 1 3 1 2 2 3 2 2 3 3 3 3 1 2 3 2 0 3 1 2 2 2 2 3 1 2 3 1 1 3 3 1 0 2 2 1 0 2 2 2 2 2 0 3 2 2 0 0 2 0 2 1 3 0 2 2 2 3 2 3 0 3 2 2 2 1 2 2 1 1 3 2 2 3 3 3 3 2 2 0 2 3 2 1 3 3 2 2 0 2 3 2 3 1 3 3 3 0 2 1 0 1 0 2 3 2 2 3 1 3 2 2 2 3 2 2 2 0 2 2 2 2 3 0 3 2 0 2 0 0 2 3 1 2 2 2 1 2 2 3 3 2 2 2 1 2 3 2 2 2 2 3 2 2 0 3 2 3 2 2 3 3 3 2 1 2 2 2 3 1 3 2 3 3 2 1 2 0 2 3 2 2 3 3 1 0 1 0 2 2 1 2 2 3 0 3 2 2 2 3 3 2 2 2 3 1 2 2 3 3 0 3 3 3 0 2 0 2 0 2 3 3 1 3 2 3 2 0 2 2 2 3 3 2 1 3 3 3 3 3 2 3 2 2 2 3 2 2 2 2 2 2 1 2 3 2 1 2 1 2 2 3 2 2 0 3 0 3 0 2 2 0 3 2 2 3 3 3 3 2 1 0 3 3 3 2 0 2 2 2 1 0 3 0 0 1 2 1 2 1 1 3 1 2 2 3 3 3 2 3 3 3 1 3 2 3 2 3 2 0 3 3 3 0 2 1 0 2 0 2 3 2 1 2 3 3 1 2 2 0 1 2 1 3 2 1 3 2 3 2 2 3 3 3 3 1 1 1 0 2 1 2 2 2 2 0 1 0 2 2 2 2 2 3 2 2 2 2 3 3 2 1 0 2 1 3 2 2 2 2 3 3 0 3 2 1 2 2 2 0 2 2 1 0 3 2 1 2 2 3 2 0 2 3 2 0 1 2 0 2 2 3 1 3 0 2 3 3]
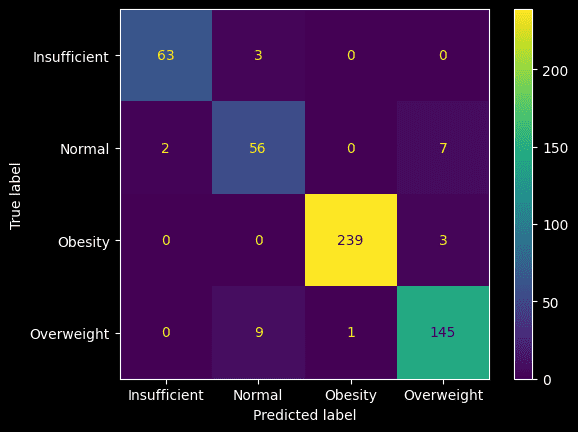
Confusion matrix di atas menunjukkan hasil prediksi data uji. Sebagai contoh, dari 65 amatan yang memiliki label Normal, 56 nya diprediksi benar, sementara 2 salah prediksi menjadi "Insufficient" dan 7 salah prediksi menjadi "Overweight". Adapun dari 242 amatan yang memiliki label "Obesity", hanya 3 yang dipredisi salah masuk sebagai "Overweight".
Menyimpan dan Memuat Model
Di bagian sebelumnya, sudah ditunjukkan bagaimana model dapat disimpan ke dalam file melalui mekanisme checkpoint. Juga sudah dibahas bagaimana memuat kembali model yang tersimpan.
Selain kedua hal tersebut, kita juga dapat menyimpan model secara langsung tanpa melalui checkpoint. Penyimpanan model dilakukan dengan memanggil method save pada model. Model yang sudah disimpan, dapat diakses kembali dengan fungsi load_model. Selanjutnya, model yang dimuat dapat digunakan seperti sebelumnya, misal untuk melakukan prediksi, malakukan penambahan pelatihan dan lain sebagainya.
Python
from keras.models import load_model
# menyimpan model_1
model_1.save("model_10_epoch.keras")
# memuat model
model = load_model("model_10_epoch.keras")