Algoritma K-Nearest Neighbors (KNN) dengan Python Scikit-Learn

Konsep KNN
K-Nearest Neighbors (KNN) adalah metode klasifikasi yang populer dalam bidang machine learning. Konsep dasar dari algoritma KNN adalah mencari k-nearest neighbors atau k tetangga terdekat dari suatu objek berdasarkan metrik jarak tertentu. KNN umumnya digunakan untuk pemodelan klasifikasi namun dapat juga digunakan untuk pemodelan regresi.
Dalam model klasifikasi, algoritma KNN menghitung jarak antara objek yang akan diklasifikasikan dengan dataset yang sudah ada, dan memilih k tetangga terdekat berdasarkan jarak tersebut. Setelah itu, algoritma ini melakukan voting atau pemungutan suara untuk menentukan kelas mayoritas dari tetangga terdekat, dan mengklasifikasikan objek yang akan diklasifikasikan berdasarkan mayoritas kelas tersebut.
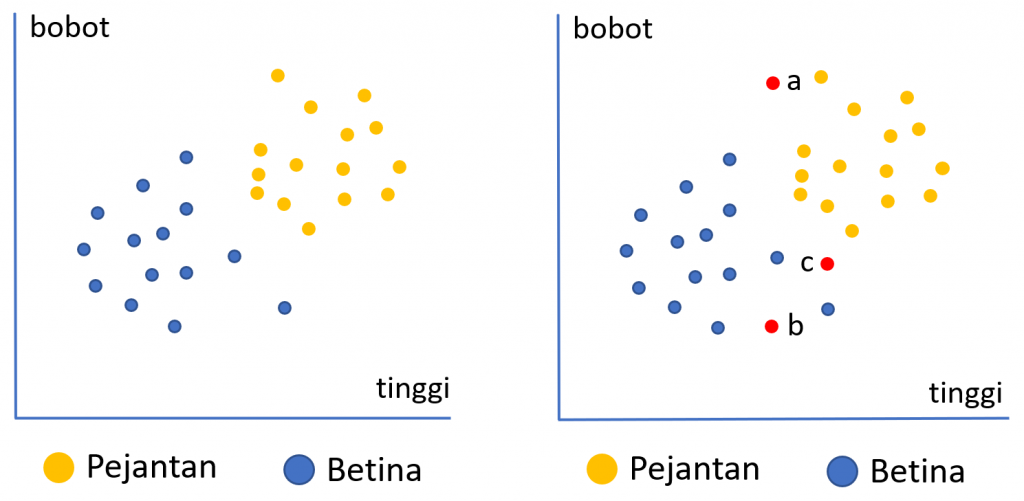
Ilustrasi di atas menunjukkan data historis mengenai karakteristik anak ayam yang baru menetas menurut dua kriteria yaitu tinggi dan bobot. Warna biru menunjukkan anak ayam betina dan orange anak ayam jantan. Secara visual dapat dilihat bahwa kecenderungan anak ayam jantan memiliki bobot dan tinggi yang lebih besar dibandingkan anak ayam betina. Pertanyaannya adalah jika kita memiliki 3 anak ayam yang baru menetas, dan belum diketahui jenis kelaminnya bagaimana kita dapat memprediksi jenis kelamin dari ketiga anak ayam tersebut.
Penentuan kelas prediksi pada algoritma KNN diukur dari kedekatan jarak data baru tersebut dengan tetangga terdekatnya. Sebagai contoh, berdasarkan 3 tetangga terdekat, anak ayam a kemungkinan akan diprediksi sebagai pejantan karena tiga tetangga terdekatnya adalah pejantan. Begitu pula anak ayam b akan diprediksi sebagai betina. Untuk anak ayam c, 2 dari 3 tetangga terdekatnya adalah pejantan maka akan diprediksi sebagai pejantan.
Untuk memperoleh model KNN yang baik, parameter penting yang perlu ditentukan adalah nilai k, atau jumlah tetangga terdekat yang akan digunakan. Nilai k tentu saja akan berbeda tergantung dari permasalahan dan data yang dihadapi. Penentuan nilai k optimal ini dapat dilakukan melalui proses tuning hyperparameter.
KNN dengan Scikit-Learn
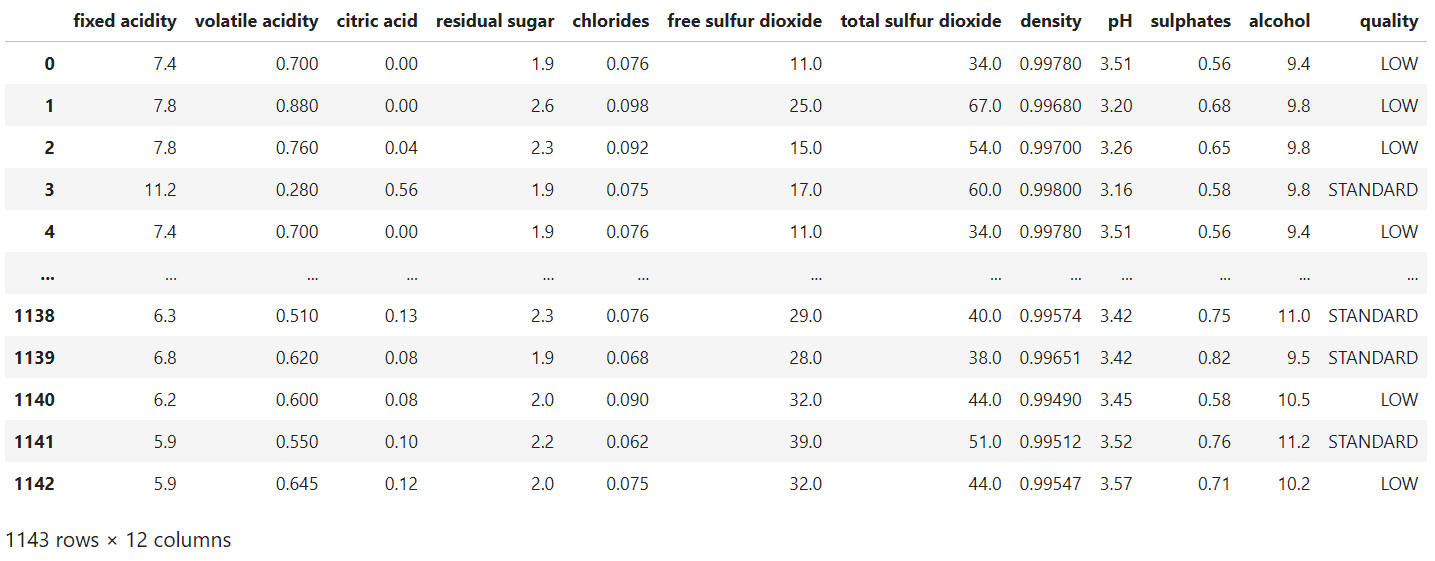
Data yang digunakan untuk pemodelan KNN ini adalah dataset wine quality dengan versi yang sudah dikelompokkan menjadi 3 kelas.Dataset terdiri 1143 amatan dengan 11 variabel input/fitur dan 1 kolom sebagai label (3 kelas kualitas wine).
Python
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("https://raw.githubusercontent.com/sainsdataid/dataset/main/wine-quality-multiclass.csv")
dataOutput
Eksplorasi Data
Python
grup = data.groupby('quality').agg({"quality": "count"})
grup_prop = grup / len(data)
print(grup)
print(grup_prop)Output
quality
quality
HIGH 159
LOW 522
STANDARD 462
quality
quality
HIGH 0.139108
LOW 0.456693
STANDARD 0.404199Dari tabulasi di atas, dapat dilihat jumlah data untuk masing-masing kelas yaitu HIGH sebanyak 159 amatan, LOW sebanyak 522 amatan dan STANDARD sebanyak 462 amatan. Secara proporsi, kelas LOW dan STANDARD memiliki proporsi yang relatif mirip, sedangkan untuk kelas HIGH jumlahnya lebih sedikit yaitu sekitar 13,9 persen saja. Adanya ketidakseimbangan ini, kemungkinan akan mempengaruhi kinerja model, khususnya saat memprediksi data yang seharusnya masuk kelas HIGH.
Python
summary = data.groupby('quality').mean().transpose()
print(summary)Output
# OUTPUT quality HIGH LOW STANDARD fixed acidity 8.846541 8.142146 8.317749 volatile acidity 0.395314 0.596121 0.504957 citric acid 0.391195 0.235096 0.263680 residual sugar 2.748428 2.543582 2.444805 chlorides 0.074711 0.092117 0.085281 free sulfur dioxide 14.188679 16.404215 15.215368 total sulfur dioxide 36.672956 54.016284 39.941558 density 0.996019 0.997054 0.996610 pH 3.282453 3.308410 3.323788 sulphates 0.745849 0.614195 0.676537 alcohol 11.528407 9.922510 10.655339
Kita juga dapat melihat bagaimana karakteristik masing-masing kelas berdasarkan nilai fitur-fiturnya. Misalkan rata-rata kadar alcohol pada kelas HIGH terlihat lebih tinggi dibandingkan kelas STANDARD dan LOW. Sebaliknya rata-rata kadar total.sulfur.dioxide pada kelas HIGH jauh lebih rendah dibandingkan dua kelas lainnya. Contoh lainnya pada pH terlihat ketiga kelas hampir tidak memiliki perbedaan. Artinya kemungkinan fitur ini tidak memiliki kontribusi besar untuk membedakan ketiga kelas.
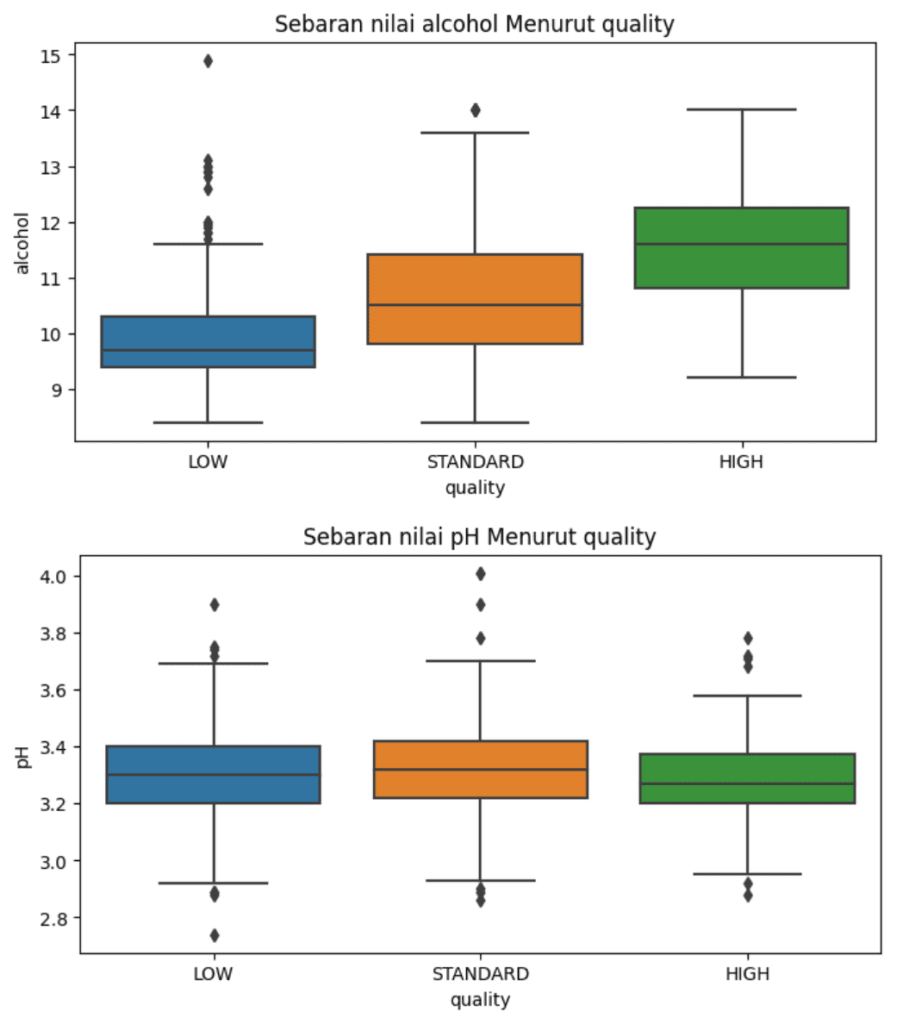
Jika diperlukan, dapat pula dibuat plot sebarannya untuk masing-masing kelas untuk melihat perbandingan secara visual. Misalkan pada contoh di bawah ini kita menyajikan boxplot untuk sebaran nilai alcohol dan pH menurut kelasnya. Dari visualisasi tersebut terlihat bahwa cenderung terdapat perbedaan nilai alcohol dimana nilai pada kelas HIGH relatif lebih tinggi dibandingkaan kelas STANDARD, begitu juga untuk kelas LOW dimana nilainya relatif lebih rendah dibandingkan kelas lainnya. Sementara itu, pada boxplot nilai pH sebaran nilainya terlihat tidak terlalu berbeda antar ketiga kelas, hal ini bisa menjadi indikasi kemungkinan fitur ini tidak memiliki pengaruh yang besar dalam menentukan kelas data.
Python
# Membuat plot boxplot untuk kolom alcohol
plt.figure(figsize=(8, 4))
sns.boxplot(x='quality', y='alcohol', hue='quality', data=data)
plt.title('Sebaran nilai alcohol Menurut quality')
plt.show()
# Membuat plot boxplot untuk kolom pH
plt.figure(figsize=(8, 4))
sns.boxplot(x='quality', y='pH', hue='quality', data=data)
plt.title('Sebaran nilai pH Menurut quality')
plt.show()Output
Data Training dan Testing
Langkah selanjutnya adalah membagi data untuk traning dan testing. Data traning digunakan sebagai dasar pelatihan model, sementara data testing untuk evaluasi performa model. Pembagian data kita lakukan dengan fungsi train_test_split yang tersedia pada pustaka sklearn.model_selection.
Python
from sklearn.model_selection import train_test_split
# membuat data fitur/input
X = data.drop('quality', axis=1)
# membuat data output
y = data['quality']
# membagi data traning 70% dan data testing 30%
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)Pembagian data kita atur dengan proporsi data training 70% dan data testing 30%. Parameter random_state dapat di-set berapa saja. Dengan nilai random_state yang sama, maka pembagian data yang sama dapat direproduksi ulang. Setiap kali menjalankan ulang fungsi rain_test_split maka pembagian data akan selalu sama bahkan jika dilakukan pada perangkat manapun.
Features Scaling
KNN merupakan algoritma berbasis jarak sehingga ukuran jarak merupakan hal penting. Perbedaan skala data antar fitur akan mempengaruhi performa model yang dihasilkan. Untuk menghindari hal tersebut, disarankan untuk selalu melakukan scaling terhadap fitur, khususnya ketika perbedaan skala sangat besar. Metode scaling yang dapat digunakan salah satunya adalah standardize, Proses standardize akan membuat setiap fitur memiliki nilai rata-rata 0 dan standar deviasi 1.
Standardize dapat dilakukan secara manual, namun untuk memudahkan, kita dapat menggunakan fungsi StandarScaler dari scikit-learn.
Python
from sklearn.preprocessing import StandardScaler scaler = StandardScaler() # Standardisasi skala data fitur scaled_X_train = scaler.fit_transform(X_train) scaled_X_test = scaler.transform(X_test)
Membuat Model KNN
Model KNN dapat kita bangun menggunakan fungsi KNeighborsClassifier pada pustaka sklearn.neighbors. Fungsi ini memiliki beberapa parameter yang bisa kita atur. beberapa parameter yang terpenting yaitu jumlah tetangga (n_neighbors, default=5), metrik jarak (metric, default='minkowski'), bobot setiap titik (weight, default='uniform' : semua k tetangga memiliki bobot sama) dan parameter lainnya.
Pada bagian ini, kita akan membuat model KNN dengan mengatur nilai-nilai parameter menggunakan nilai defaultnya.
Setelah mendapatkan model KNN berdasarkan data training, perlu dilakukan evaluasi terhadap model untuk memprediksi output dari data testing. Metrik yang dapat digunakan untuk masalah klasifikasi adalah accuracy, balanced accuracy, F1 Score (khusus klasifikasi biner) dan sebagainya. Dalam model klasifikasi, juga dapat dilihat confussion matrix untuk membandingkan hasil prediksi terhadap klasifikasi yang sebenarnya.
Python
from sklearn.neighbors import KNeighborsClassifier from sklearn.metrics import confusion_matrix, classification_report # help(KNeighborsClassifier) knn_model = KNeighborsClassifier(n_neighbors=5) # Membuat model berdasarkan data training knn_model.fit(scaled_X_train, y_train) # Memprediksi output dari data testing y_pred = knn_model.predict(scaled_X_test) # menampilkan confusion matriks print(confusion_matrix(y_test, y_pred)) # menampilkan nilai akurasi dan metrik lainnya print(classification_report(y_test, y_pred))
Output
[[ 17 6 22]
[ 8 106 38]
[ 21 57 68]]
precision recall f1-score support
HIGH 0.37 0.38 0.37 45
LOW 0.63 0.70 0.66 152
STANDARD 0.53 0.47 0.50 146
accuracy 0.56 343
macro avg 0.51 0.51 0.51 343
weighted avg 0.55 0.56 0.55 343Berdasarkan hasil di atas, dengan mengunakan 5 tetangga diperoleh model dengan akurasi yang cukup rendah yaitu 0,56. Seperti yang disampaikan sebelumnya kinerja model sangat buruk ketika memprediksi data pada kelas HIGH. Dengan nilai presisi hanya 0,37, model hanya benar memprediksi 17 dari 46 data kelas HIGH (8 salah prediksi sebagai kelas LOW dan 21 sebagai kelas STANDARD). Ini artinya lebih dari setengahnya salah diprediksi yang menunjukkan hasil yang buruk.
Untuk kelas lainnya nilai presisi juga beragam, yaitu 0,63 untuk kelas LOW dan 0,53 untuk kelas STANDARD. Hasil ini tentunya juga tidak bisa disebut baik. Pada bagian selanjutnya, kita akan mencoba melakukan pengaturan nilai k serta hiperparameter lainnya, untuk mencari model dengan kinerja yang lebih baik.
Tuning Hiperparameter
Model sebelumnya dengan nilai k=5 menghasilkan kinerja yang kurang memuaskan. Hal ini tidak terlepas dari kondisi data yang tidak seimbang. Untuk mencari model yang lebih baik kita dapat menggunakan fungsi GridSearchCV. Terdapat beberapa parameter yang dapat diatur pada fungsi KNeighborsClassifier. Namun, pada contoh ini hanya dua yang akan diatur yaitu n_neighbors yang menunjukkan nilai k atau banyaknya tetangga, serta weights untuk mengatur bobot masing-masing kelas. Pengaturan bobot ini memungkinkan kita untuk memperbesar bobot kelas HIGH dengan harapan meningkatkan kinerja model khususnya pada kelas tersebut.
Penentuan model terbaik dapat menggunakan berbagai metrik nilai seperti yang disampaikan sebelumnya. Kita akan melakukan iterasi untuk berbagai nilai k dan mencari model yang memberikan skor terbaik. Pada contoh ini akan mengunakan metrik akurasi dimana semakin tinggi nilai akurasi maka performa model semakin baik.
Python
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import confusion_matrix, classification_report
from sklearn.model_selection import GridSearchCV
param_grid = {
'n_neighbors': np.arange(1, 20, 1), # 1, 2, 3, ....19
'weights' : ['uniform', 'distance']
}
model_knn = KNeighborsClassifier()
model_knn_cv = GridSearchCV(model_knn,
param_grid=param_grid,
scoring="accuracy" , cv=5, refit=True,
n_jobs=4)
# fitting model
model_knn_cv.fit(scaled_X_train, y_train)
# menampilkan pengaturan parameter da skor terbaik
print("Best Param:", model_knn_cv.best_params_)
print("best Score:", model_knn_cv.best_score_)
# membuat prediksi data uji
y_pred = model_knn_cv.predict(scaled_X_test)
print(y_pred)
print(confusion_matrix(y_test, y_pred))
print("Accuracy :", accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))Output
# Output
Best Param: {'n_neighbors': 17, 'weights': 'distance'}
best Score: 0.6625
['LOW' 'STANDARD' 'LOW', ..., 'STANDARD' 'LOW' 'LOW']
[[ 33 2 10]
[ 3 116 33]
[ 10 46 90]]
Accuracy : 0.6967930029154519
precision recall f1-score support
HIGH 0.72 0.73 0.73 45
LOW 0.71 0.76 0.73 152
STANDARD 0.68 0.62 0.65 146
accuracy 0.70 343
macro avg 0.70 0.70 0.70 343
weighted avg 0.70 0.70 0.70 343Dari hasil di atas kita peroleh model dengan nilai k (n_neighbors) sebanyak 17 serta weights menggunakan distance dengan nilai akurasi saat pelatihan sebesar 0,6625. Saat model digunakan untuk memprediksi data uji, diperoleh hasil yang baik di mana akurasi model mencapai 0,7. Nilai ini jauh lebih tinggi dibandingkan model sebelumnya dengan akurasi hanya sebesar 0,56. Nilai presisi dan recall juga menunjukkan hasil yang baik. Pada kelas HIGH misalnya, nilai presisi mencapai 0,72, dari 46 data kelas HIGH sebanyak 33 diprediksi dengan tepat dan sisanya (3 diprediksi sebagai kelas LOW dan 10 sebagai kelas STANDARD).
Hasil ini mungkin masih dapat ditingkatkan dengan pengaturan lebih lanjut hiperparameter model. Silahkan untuk mencoba kombinasi dan pengaturan lainnya.
Prediksi Data Baru
Setelah memperoleh model terbaik, maka kita dapat melakukan prediksi pada data baru. Sebagai contoh, terdapat data 2 wine baru dan kita ingin mengetahui perkiraan kualitasnya. Langkah untuk memprediksi data tersebut adalah sebagai berikut:
Python
# contoh data baru
new_data = pd.DataFrame({'fixed acidity' : [8.25, 7.94],
'volatile acidity' : [0.46, 0.48],
'citric acid' : [0.32, 0.28],
'residual sugar' : [2.6, 2.6],
'chlorides': [0.065, 0.081],
'free sulfur dioxide': [14.7, 14.7],
'total sulfur dioxide': [38.24, 38.85],
'density': [0.96, 0.98],
'pH': [3.4, 3.4],
'sulphates': [0.72, 0.70],
'alcohol': [11.4, 11.0]
})
print(new_data.transpose())
# data baru perlu di scaling dengan scaler yang digunakan saat pelatihan
scaled_new_data = scaler.transform(new_data)
# prediksi kelas data
prediksi = knn_model.predict(scaled_new_data)
print(f"\nKualitas: {prediksi}")Output
# OUTPUT fixed acidity 8.250 7.940 volatile acidity 0.460 0.480 citric acid 0.320 0.280 residual sugar 2.600 2.600 chlorides 0.065 0.081 free sulfur dioxide 14.700 14.700 total sulfur dioxide 38.240 38.850 density 0.960 0.980 pH 3.400 3.400 sulphates 0.720 0.700 alcohol 11.400 11.000 Kualitas: ['HIGH' 'STANDARD']
Berdasarkan hasil di atas, kita memprediksi bahwa wine pertama memiliki kualitas HIGH dan untuk wine kedua masuk kelas STANDARD.
Selamat mencoba dengan data lainnya!
Referensi
- James, G., Witten, D., Hastie, T., Tibshirani, R. 2014, An Introduction to Statistical Learning with Applications in R, Springer.
- sklearn.neighbors.KNeighborsClassifier — scikit-learn 1.5 documentation
Tulisan Lainnya







