Convolutional Neural Network untuk Klasifikasi Gambar dengan TensorFlow
Convolutional Neural Network (CNN) adalah salah satu jenis deep learning yang populer untuk pemodelan klasifikasi gambar. CNN sangat efektif dalam mengenali objek pada gambar karena model dapat mempelajari fitur-fitur dari data gambar. CNN telah digunakan pada banyak aplikasi, seperti pengenalan wajah, pengenalan karakter tulisan tangan, serta klasifikasi objek.
Pada tutorial kali ini, kita akan mempelajari penggunaan library TensorFlow untuk membuat model CNN. Model akan dilatih untuk memprediksi gambar-gambar dari 15 jenis sayuran. Dataset ini tersedia di kaggle dapat diakses di sini.
Note: Ukuran dataset yang ‘relatif’ besar serta proses pelatihan model CNN cenderung membutuhkan komputasi yang besar maka tidak disarankan menggunakan perangkat dengan CPU saja. Jika perangkat tidak memiliki GPU dedicated, dapat menggunakan layanan gratis seperti google colab atau kaggle. Keduanya menyediakan opsi penggunaan GPU secara gratis untuk pelatihan model neural network. Penggunaan GPU akan mempercepat waktu komputasi secara signifikan. Pada contoh ini, pelatihan menggunakan GPU (menggunakan Kaggle) 15-20 kali lebih cepat dibandingkan menggunakan CPU saja . Selain itu, dengan menggunakan google colab atau kaggle kita juga tidak perlu melakukan instalasi tensorflow ataupun library pendukung lainnya. Sebagai tambahan, jika menggunakan kaggle, maka tidak perlu mengunduh dataset karena tersedia secara publik dan dapat langsung ditambahkan saat membuat proyek baru.
Penyiapan Data
Seperti disampaikan sebelumnya, dataset yang digunakan adalah data gambar dari 15 jenis sayuran. Dataset ini sudah tersusun dengan struktur yang rapi sehingga tidak diperlukan banyak pengaturan. Di dalam direktori data juga sudah tersusun dalam 3 subdirektori terpisah untuk data latih, validasi maupun data uji. Pada masing-masing subdirektori tersebut sudah terdapat 15 subdirektori berdasarkan 15 jenis sayuran.
Mengatur Struktur Direktori
Seluruh data gambar kita simpan di dalam direktori vegetables. Di dalam direktori tersebut gambar-gambar sudah terorganisir menjadi 3 subdirektori yaitu train, validation dan test. Pada setiap subdirektori tersebut terdapat lagi 15 subdirektori dengan nama jenis sayuran mulai dari Bean, Bitter_Gourd hingga Tommato. Setiap subdirektori tersebut berisi gambar-gambar dari jenis sayuran sesuai dengan namanya.
Secara total terdapat 15.000 gambar untuk data training (1.000 gambar untuk setiap jenis sayuran) serta masing-masing 3.000 gambar untuk data validasi dan data testing (200 gambar per jenis sayuran).
Silahkan sesuaikan susunan direktori penyimpanan jika diperlukan, namun khusus subdirektori terakhir yang langsung berisi gambar-gambar jenis sayuran sebaiknya tetap seperti apa adanya. Hal ini sangat penting karena TensorFlow akan memberikan label pada setiap gambar, sesuai dengan nama direktori-direktori tersebut. Setiap gambar di dalam subdirektori yang sama akan masuk ke dalam kelas yang sama pula.
Berikut struktur direktori yang akan digunakan dalam tutorial ini:
Struktur Direktori
Project CNN
-- cnn_vegetables.ipynb
-- vegetables
-- train
-- Bean
-- Bitter_Gourd
-- Bottle_Gourd
-- Brinjal
...
-- Tommato
-- validation
-- Bean
-- Bitter_Gourd
-- Bottle_Gourd
-- Brinjal
...
-- Tommato
-- test
-- Bean
-- Bitter_Gourd
-- Bottle_Gourd
-- Brinjal
...
-- Tommato
Selanjutnya, jika diperlukan kita dapat mengeksplorasi dan mengecek gambar-gambar yang ada. Pada contoh di bawah ini kita menggunakan library os untuk mengakses direktori dan file gambar. Masih pada kode yang sama, kita juga menampilkan daftar subdiektori yang terdapat di dalam direktori train. Daftar ini juga tidak sekedar bermakna nama subdirektori saja, namun juga menunjukkan kelas-kelas yang akan digunakan di dalam model, dimana secara keseluruhan terdapat 15 kelas jenis sayuran.
Python
import os
train_path = "./vegetables/train"
val_path = "./vegetables/validation"
test_path = "./vegetables/test"
subdirectories = [f.name for f in os.scandir(train_path) if f.is_dir()]
print("Daftar Kelas:")
for subdir in subdirectories:
print(f">>> {subdir}")# OUTPUT Daftar Kelas: >>> Bean >>> Bitter_Gourd >>> Bottle_Gourd >>> Brinjal >>> Broccoli ... >>> Cucumber >>> Papaya >>> Potato >>> Pumpkin >>> Radish >>> Tomato
Berikutnya, buat fungsi untuk menampilkan gambar secara acak dari direktori tertentu. Fungsi ini dapat menampilkan beberapa gambar sekaligus dalam bentuk grid berukuran n_row baris dan n_col kolom. Banyaknya gambar yang dapat ditampilkan adalah sebanyak n_row*n_col gambar. Silahkan mencoba gambar jenis sayuran lainnya, baik pada data train, validation ataupun test.
Python
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
import random
# fungsi untuk menampilkan gambar secara acak pada grid n_row x n_col
def view_random_image(data_dir, class_dir, n_row=1, n_col=1):
# menentukan direktori gambar
target_dir = data_dir + "/" + class_dir + "/"
# memilih sebanyak n_row*n_col gambar secara acak
rand_images = random.sample(os.listdir(target_dir), n_row*n_col)
fig, axs = plt.subplots(n_row, n_col)
# menampilkan gambar dalam bentuk grid ukuran n_row*n_col
for i, ax in enumerate(axs.flat):
img = mpimg.imread(target_dir + rand_images[i])
ax.imshow(img)
ax.set_title(f"{class_dir} {i+1}\n{img.shape}")
ax.axis("off")
plt.tight_layout()
plt.show()
# menampilkan contoh beberapa gambar acak dari direktori train
view_random_image(train_path, "Bean", 1, 3)
view_random_image(train_path, "Cucumber", 1, 3)

Membuat Objek ImageDataGenerator
Pelatihan model tensorflow hanya dapat bekerja dengan data-data numerik. Oleh karena itu gambar perlu diproses agar dapat menjadi input bagi model tensorflow. Terdapat dua tahapan yang perlu dilakukan yaitu membuat objek ImageDataGenerator dan menerapkannya pada gambar-gambar pada data latih, data validasi maupun data uji.
ImageDataGenerator merupakan bagian dari modul tensorflow.keras.preprocessing.image. Objek ini digunakan untuk menyimpan representasi numerik dari gambar. ImageDataGenerator memiliki beberapa parameter yang dapat diatur salah satu yang utama adalah rescale. Parameter ini digunakan untuk melakukan features scaling pada data gambar misalkan dengan normalisasi yaitu merubah nilai sehingga berada pada selang nilai 0 hingga 1.
Representasi numerik dari gambar pada objek ImageDataGenerator adalah nilai RGB dengan setiap piksel diwakili dalam 3 chanel warna (R, G, B). Masing-masing chanel memiliki nilai antara 0-255 yang menunjukkan besarnya komposisi chanel tersebut. Karena nilainya berada antara 0-255 maka normalisasi data dapat dilakukan dengan mudah yaitu membagi nilai setiap piksel dengan 255.
Pada data latih kita juga akan mengatur beberapa parameter untuk augmentasi gambar. Augmentasi merupakan teknik untuk memperluas dataset pelatihan dengan membuat variasi dari gambar yang ada. Dengan teknik ini, kita dapat menghasilkan gambar baru dengan melakukan perubahan kecil pada gambar yang sudah ada, seperti memutar, memotong, membalik atau menggeser gambar. Dengan cara ini, kita dapat memberikan variasi dalam data pelatihan yang digunakan serta dapat mencegah terjadinya overfitting.
Dalam contoh berikut, dilakukan augmentasi gambar pada data latih dengan cara merotasi gambar sebesar 20 derajat, melakukan pergeseran pada gambar sebesar 20% dari lebar atau tinggi gambar, melakukan shear sebesar 20%, dan melakukan zoom sebesar 20%. Selain itu, juga melakukan flip secara horizontal pada gambar.
Membangkitkan data Train, Validation dan Test
Objek ImageDataGenerator memiliki metode flow_from_directory untuk membaca gambar dari direktori yang telah ditentukan dan menerapkan pengaturan terhadap gambar-gambar tersebut. Terdapat beberapa parameter yang dapat diatur yaitu:
target_size, nilai default-nya (256, 256). Jika gambar asli memiliki resolusi yang lebih tinggi atau lebih rendah, TensorFlow akan mengubahnya ke resolusi 256×256 piksel sesuai dengan nilai default. Pada contoh dataset yang kita gunakan semua gambar kebetulan dalam ukuran yang lebih kecil yaitu 224×224 piksel, oleh karena itu kita akan menggunakan ukurantarget_size=(224, 224)batch_size: jumlah sampel gambar yang diproses oleh model dalam satu iterasi pelatihan. Selama pelatihan model, data biasanya dibagi menjadi batch-batch kecil untuk efisiensi komputasi. Batch size menentukan berapa banyak sampel yang akan diproses dalam satu waktu sebelum model melakukan penyesuaian bobot (weight adjustment) berdasarkan hasil perhitungan error (loss) pada batch tersebut. Nilai default parameterbatch_sizeadalah32, namun pemilihan batch size dapat diatur pada karakteristik dataset, kompleksitas model, dan sumber daya komputasi yang tersedia.class_mode: bentuk data kelas target. Nilai defaultnya adalah'categorical'yang menunjukkan bahwa kelas target (label) akan dikodekan dalam bentuk one-hot encoding. Dalam konteks klasifikasi multi-kelas, ini berarti bahwa label akan diubah menjadi vektor biner yang memiliki nilai 1 pada indeks yang sesuai dengan kelas yang sesuai dan nilai 0 pada indeks yang lainnya.shuffle: proses pembuatan data apakah akan dilakukan pengacakan atau tidak. Nilai default-nya adalahTrue, oleh karena itu pada contoh di bawah ini, khususnya padatrain datakita menggunakan nilai default. Dengan demikian, pada saat pembentukan data latih urutan gambar akan di acak.seeddapat di-set agar proses pembentukan data dapat direproduksi dengan hasil yang sama. Jika parametershuffle=Trueatau sesuai default-nya maka dengan menentukan nilaiseedyang sama maka pengacakan dapat direproduksi dengan hasil yang sama walaupun dijalankan berulang kali.
Python
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
tf.random.set_seed(42)
# tanpa augmentasi
# train_datagen = ImageDataGenerator(rescale=1.0 / 255)
# Dengan augmentasi
train_datagen = ImageDataGenerator(
rescale=1.0 / 255,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode="nearest"
)
val_datagen = ImageDataGenerator(rescale=1.0 / 255)
test_datagen = ImageDataGenerator(rescale=1.0 / 255)
img_size = (224, 224)
train_data = train_datagen.flow_from_directory(
train_path,
target_size=img_size,
batch_size=32,
class_mode="categorical",
seed=42
)
val_data = val_datagen.flow_from_directory(
val_path,
target_size=img_size,
batch_size=32,
class_mode="categorical",
seed=42
)
test_data = test_datagen.flow_from_directory(
test_path,
target_size=img_size,
batch_size=32,
class_mode="categorical",
shuffle=False # urutan data dibiarkan apa adanya (tidak diacak)
)# OUTPUT Found 15000 images belonging to 15 classes. Found 3000 images belonging to 15 classes. Found 3000 images belonging to 15 classes.
Mengakses Data Gambar
Agar dapat memahami lebih jelas bagaimana struktur dan bentuk data yang sudah dibangkitkan, kita dapat mengakses data tersebut. Sebagai contoh, kita akan menampilkan beberapa informasi dari data latih (train_data).
Dari output dapat dilihat bahwa variabel train_data memiliki panjang 469 yang menunjukkan banyaknya batch. Karena ukuran batch yang digunakan adalah 32, sementara jumlah gambar sebanyak 15.000 maka banyaknya batch adalah 15.000//30=469.
Di dalam masing-masing batch tersebut (misal batch 1) dapat diperoleh objek tuple dengan 2 elemen. Elemen pertama menyimpan informasi numerik dari 32 gambar dalam batch tersebut. Sementara elemen kedua menyimpan informasi kelasnya.
Jika diakses lebih dalam lagi maka dapat diperoleh data gambar pertama di dalam batch 1 pada train_data. Data tersimpan dalam list 3 dimensi dengan ukuran (224, 224, 3) sesuai ukuran gambar yang diatur sebelumnya. Setiap nilai di dalamnya akan berkisar antara 0-1 dan merepresentasikan nilai piksel yang sudah dinormalisasi.
Dengan cara yang sama kita juga dapat mengakses kelas dari gambar tersebut. Data ini tersimpan dalam bentuk one hot encoding atau dalam kasus ini adalah list 1 dimensi dengan 15 elemen. Dari 15 elemen, hanya ada 1 elemen dengan nilai 1 dan selebihnya bernilai 0. Posisi indeks dari nilai 1 menunjukkan kelas dari gambar tersebut. Pada contoh ini nilai 1 berada pada indeks ke-11 (kelas 11 : Potato).
Python
# menampilkan jumlah batch pada data train
print(f"Jumlah batch (training): {len(train_data)}")
# mengambil batch 1 data train
batch_1_train = train_data[0]
# setiap batch tersimpan dalam bentuk tupple
# elemen pertama menyimpan data piksel dari 32 gambar pada batch 1
batch_1_train_data = train_data[0][0]
# elemen kedua menyimpan data label dari 32 gambar pada batch 1
batch_1_train_label = train_data[0][1]
# ukuran batch = 32 (sesuai pengaturan)
print(f"Jumlah gambar pada batch 1: {len(batch_1_train_data)}")
print(f"Jumlah label pada batch 1: {len(batch_1_train_label)}")
# mengambil gambar 1 pada batch 1 data training
image_1_batch_1_train_data = train_data[0][0][0]
# mengambil label (kelas) gambar 1 pada batch 1 data training
image_1_batch_1_train_label = train_data[0][1][0]
# menampilkan data gambar 1 : (224, 224, 3)
print(f"\nBatch 1 Gambar 1 train (data):\n{image_1_batch_1_train_data}")
# menampilkan data label (kelas) gambar 1 pada batch 1 data training
print(f"\nBatch 1 Gambar 1 train (Label):\n{image_1_batch_1_train_label}")# OUTPUT Jumlah batch (training): 469 Jumlah gambar pada batch 1: 32 Jumlah label pada batch 1: 32 Batch 1 Gambar 1 train (data): [[[0.4901961 0.58431375 0.7176471 ] [0.4901961 0.58431375 0.7176471 ] [0.4901961 0.58431375 0.7176471 ] ... [0.7145708 0.8322179 0.9655512 ] [0.7176471 0.8352942 0.9686275 ] [0.7176471 0.8352942 0.9686275 ]] [[0.4901961 0.58431375 0.7176471 ] [0.4901961 0.58431375 0.7176471 ] [0.4901961 0.58431375 0.7176471 ] ... [0.5764706 0.70980394 0.8980393 ] [0.5764706 0.70980394 0.8980393 ] [0.5764706 0.70980394 0.8980393 ]] [[0.54187965 0.65856934 0.7925044 ] [0.54546535 0.6555201 0.7983359 ] [0.54779434 0.65741366 0.79052454] ... [0.5746439 0.7079773 0.8962126 ] [0.5752765 0.7086098 0.89684516] [0.575909 0.7092424 0.8974777 ]]] Batch 1 Gambar 1 train (Label): [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.]
Membuat Model CNN
Terdapat beberapa tahapan yang perlu dilakukan dalam pembuatan model yaitu inisiasi arsitektur model, kompilasi model, pelatihan model hingga evaluasi. Pada bagian ini akan dibahas keseluruhan pada sub-bagian tersendiri untuk masing-masing tahapan.
Menyusun Arsitektur Model
Langkah pertama dalam membangun model neural network tentunya adalah menentukan arsitektur yang akan digunakan.
Pada bagian pertama ini, kita akan membuat model cnn dan kita namakan model_1. Berikut ini adalah pengaturan lapisan-lapisan yang akan digunakan pada model:
- Pertama kita membuat objek
model_1menggunakan modelSequential, yang berarti layer-layer akan ditambahkan satu per satu secara berurutan. - Menambah lapisan convolution (
Conv2D) dengan jumlah filter sebanyak20, ukuran kernel(3, 3), fungsi aktivasi"relu". Selain itu pada layer pertama, kita juga menentukan nilai parameterinput_shapeyaitu(224, 224, 3). Nilai ini sesuai data yang telah kita siapkan sebelumnya, yaitu ukuran gambar yang diatur menjadi 224 piksel x 224 piksel dengan 3 channel warna (RGB). - Menambah lapisan convolution (
Conv2D) yang kedua dengan jumlah filter sebanyak20, ukuran kernel(3, 3)dan fungsi aktivasi"relu". - Menambah lapisan max pooling (
MaxPool2D): setelah beberapa lapisan convolution, perlu dibuat lapisanMaxPool2Dyang menggunakan operasi max-pooling dengan ukuran(2, 2)danpadding="valid". - Menambah 2 lapisan convolution (
Conv2D) dengan jumlah filter sebanyak 50, ukuran kernel(3, 3)dan fungsi aktivasi"relu". - Menambah lapisan max pooling (
MaxPool2D) dengan ukuran pool(2, 2) - Menambah lapisan flatten (
Flatten): setelah beberapa lapisan convolution dan pooling, kita perlu menambahkan lapisanFlatten, yang berfungsi untuk mengubah representasi fitur multidimensi menjadi vektor satu dimensi, agar dapat dihubungkan dengan lapisan Dense (fully connected). - menambah lapisan
Dense: Setelah lapisanFlatten, kita dapat menambahkan beberapa lapisanDense(fully connected) pada model. Pada contoh ini kita hanya menambahkan 1 lapisan dense saja sebagai lapisan terakhir. Karena bertindak sebagai lapisan terakhir, maka jumlah unit yang digunakan harus sama dengan banyaknya kelas yaitu 15 unit. Adapun fungsi aktivasi yang digunakan dalam klasifikasi multi-kelas adalah"softmax".
Mengompilasi Model
Setelah model selesai dibuat, langkah berikutnya adalah mengompilasi model. Kompilasi model dilakukan melalui metode compile pada objek model. Metode ini memiliki beberapa parameter yang dapat diatur. Beberapa parameter utamanya yaitu:
loss: untuk model klasifikasi multi-kelas loss function yang tepat digunakan adalah"categorical_crossentropy".optimizer: terdapat beberapa algoritma optimasi pada TensorFlow yang dapat digunakan seperti SGD, Adam, RMSProp dan sebagainya. Adam (Adaptive Moment Estimation) adalah algoritma optimasi yang populer yang menggabungkan langkah adaptif dan momentum. Algoritma Adam cenderung bekerja dengan baik di berbagai jenis tugas dan sering menjadi pilihan default. Pada contoh ini kita menggunakan adam denganlearning_rate=0.001yang merupakan nilai default-nya.metrics: menunjukkan ukuran yang digunakan untuk mengukur performa model. Dalam permasalahan klasifikasi ukuran yang umum digunakan adalahaccuracy. Parameter ini menerima argumen dalam bentuk list, yang artinya kita dapat menggunakan lebih dari 1 ukuran sekaligus jika memang diperlukan.
Melatih (Fitting) Model
Proses pelatihan model dilakukan dengan memanggil metode fit pada objek model. Pada metode ini juga terdapat beberapa parameter yang perlu ditentukan. Beberapa diantaranya yaitu:
x, y: data untuk proses pelatihan. Dalam hal ini, karena data diperoleh melalui objekImageDataGenerator, kita tidak perlu menyediakan secara terpisah antara data fitur dan label, cukup dengan mengirimkan objektrain_datadimana di dalamnya sudah tersimpan data untuk fitur dan labelnya sekaligus.validation_data: data yang digunakan untuk validasi pada setiap epoch.epochs: banyaknya epoch yang akan dilakukan pada proses pelatihan.
Python
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, Flatten, Dense, MaxPool2D
from tensorflow.keras.optimizers import Adam
tf.random.set_seed(42)
# Arsitektur model
model_1 = Sequential()
model_1.add(
Conv2D(filters=20, kernel_size=(3, 3), activation="relu", input_shape=(224, 224, 3))
)
model_1.add(Conv2D(20, (3, 3), activation="relu"))
model_1.add(MaxPool2D((2, 2), padding="valid"))
model_1.add(Conv2D(50, (3, 3), activation="relu"))
model_1.add(Conv2D(50, (3, 3), activation="relu"))
model_1.add(MaxPool2D((2, 2)))
model_1.add(Flatten())
model_1.add(Dense(15, activation="softmax"))
# MELATIH MODEL
# compiling model
model_1.compile(
loss="categorical_crossentropy",
optimizer=Adam(learning_rate=0.001), # atau optimizer="adam"
metrics=["accuracy"],
)
# fitting model
history_1 = model_1.fit(
train_data,
validation_data=val_data,
epochs=10,
)# OUTPUT Epoch 1/10 469/469 [==============================] - 288s 595ms/step - loss: 1.3449 - accuracy: 0.5491 - val_loss: 0.8320 - val_accuracy: 0.7220 Epoch 2/10 469/469 [==============================] - 198s 421ms/step - loss: 0.7926 - accuracy: 0.7375 - val_loss: 0.4862 - val_accuracy: 0.8590 Epoch 3/10 469/469 [==============================] - 197s 421ms/step - loss: 0.5861 - accuracy: 0.8131 - val_loss: 0.4029 - val_accuracy: 0.8737 Epoch 4/10 469/469 [==============================] - 192s 409ms/step - loss: 0.5085 - accuracy: 0.8366 - val_loss: 0.3414 - val_accuracy: 0.8933 Epoch 5/10 469/469 [==============================] - 191s 407ms/step - loss: 0.4254 - accuracy: 0.8643 - val_loss: 0.2556 - val_accuracy: 0.9253 Epoch 6/10 469/469 [==============================] - 189s 403ms/step - loss: 0.3768 - accuracy: 0.8809 - val_loss: 0.2158 - val_accuracy: 0.9377 Epoch 7/10 469/469 [==============================] - 184s 391ms/step - loss: 0.3410 - accuracy: 0.8961 - val_loss: 0.1882 - val_accuracy: 0.9463 Epoch 8/10 469/469 [==============================] - 185s 394ms/step - loss: 0.3164 - accuracy: 0.9018 - val_loss: 0.2037 - val_accuracy: 0.9430 Epoch 9/10 469/469 [==============================] - 191s 407ms/step - loss: 0.2935 - accuracy: 0.9088 - val_loss: 0.1733 - val_accuracy: 0.9477 Epoch 10/10 469/469 [==============================] - 193s 411ms/step - loss: 0.2696 - accuracy: 0.9154 - val_loss: 0.2488 - val_accuracy: 0.9420
Dari hasil pelatihan dalam 10 epoch, kita memperoleh model dengan performa yang cukup baik. Akurasi yang dicapai pada data train sebesar 0.9154 sementara pada data validasi nilai akurasi lebih baik lagi yaitu mencapai 0.9420. Hal ini menunjukkan 94,2% (2.826 dari 3.000) gambar pada data val_data diprediksi secara tepat. Nilai-nilai ini juga menunjukkan bahwa secara umum model yang dibangun tidak mengalami overfitting.
Menyimpan dan Memuat Model
Berdasarkan setiap proses di atas, dapat dipahami pelatihan model CNN membutuhkan waktu yang tidak sedikit. Oleh karena itu, setelah model selesai dilatih penting untuk menyimpan model tersebut agar dapat digunakan lagi. Dengan menyimpan model ke dalam file, maka kita dapat menggunakannya kembali tanpa harus melakukan pelatihan ulang.
Pada kode di bawah ini, dengan menggunakan fungsi save_model dari modul tensorflow.keras.models ktia menyimpan model_1 dalam bentuk file dengan nama model_1.h5. Selanjutnya misalkan dikesempatan lain kita akan menggunakan model tersebut maka kita dapat memuat model menggunakan fungsi load_model yang juga terdapat pada modul yang sama.
Setelah model dimuat kita dapat melakukan berbagai operasi pada model tersebut, misalkan menampilkan ringkasan model, melakukan prediksi atau dapat pula melakukan proses lainnya termasuk menambahkan layer-layer baru, menambah jumlah epoch dan melakukan pelatihan kembali.
Di bawah ini, model yang dimuat akan kita gunakan untuk melakukan prediksi tanpa melakukan modifikasi apapun.
Python
from tensorflow.keras.models import save_model, load_model
# menyimpan model yang sudah dilatih
model_1.save("model_1.h5")
# membuka model yang sudah dilatih
model_1 = load_model("model_1.h5")
model_1.summary()# OUTPUT
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 222, 222, 20) 560
conv2d_2 (Conv2D) (None, 220, 220, 20) 3620
max_pooling2d_1 (MaxPoolin (None, 110, 110, 20) 0
g2D)
conv2d_3 (Conv2D) (None, 108, 108, 50) 9050
conv2d_4 (Conv2D) (None, 106, 106, 50) 22550
max_pooling2d_2 (MaxPoolin (None, 53, 53, 50) 0
g2D)
flatten_1 (Flatten) (None, 140450) 0
dense_1 (Dense) (None, 15) 2106765
=================================================================
Total params: 2,142,545
Trainable params: 2,142,545
Non-trainable params: 0
_________________________________________________________________Evaluasi dan Prediksi
Di dalam dataset yang kita gunakan, gambar-gambar terbagi ke dalam 3 bagian besar yaitu train, validation dan test. Pembagian seperti ini merupakan bentuk pembagian paling ideal dimana model dilatih berdasarkan data train dan pengukuran performa dilakukan menggunakan data validation. Satu set terakhir yaitu test digunakan sebagai bahan evaluasi model.
Pada kita gunakan test_data untuk mengevaluasi performa model sesungguhnya terhadap data yang belum pernah dilihat. Berdasarkan hasil kode di bawah ini, ternyata model_1 memiliki nilai akurasi sebesar 0.9533 yang artinya 2.860 dari 3.000 gambar pada data testing diprediksi dengan tepat.
Untuk melihat lebih detail performa model_1 kita dapat menggunakan metode predict untuk mendapatkan prediksi kelas dari setiap gambar. Dalam pemodelan klasifikasi multikelas, dimana kita menggunakan fungsi aktivasi softmax maka output dari model adalah nilai probabilitas/ peluang suatu gambar masuk ke dalam 15 kelas yang tersedia.
Tentu saja kelas final dari setiap gambar yaitu kelas dengan nilai peluang terbesar. Sebagai contoh, berdasarkan output di bawah, gambar pertama dan kedua pada data testing akan diprediksi masuk ke kelas 0 karena peluangnya adalah 1 (dalam dua angka desimal), begitu juga data uji ke-3000, akan diprediksi masuk ke kelas 14 dengan nilai peluang 0.98.
Python
print(model_1.evaluate(test_data)) predictions = model_1.predict(test_data) print(predictions.round(2))
# OUTPUT 94/94 [==============================] - 70s 742ms/step - loss: 0.1489 - accuracy: 0.9533 [0.14888080954551697, 0.95333331823349] 94/94 [==============================] - 64s 672ms/step [[1. 0. 0. ... 0. 0. 0. ] [1. 0. 0. ... 0. 0. 0. ] [0.3 0.09 0. ... 0.01 0.04 0.02] ... [0. 0. 0. ... 0. 0. 1. ] [0. 0. 0. ... 0. 0. 1. ] [0. 0. 0. ... 0. 0. 0.98]]
Kita juga dapat mevisualisasikan kelas hasil prediksi terhadap kelas sebenarnya dalam bentuk confusion matrix. Terdapat beberapa cara untuk melakukannya, namun di sini kita akan menggunakan heatmap dari library seaborn, sementara penghitungan confusion matrix dilakukan melalui fungsi confusion_matrix dari modul sklearn.metrics.
Kelas hasil prediksi dapat diperoleh menggunakan fungsi argmax dari library numpy. Fungsi ini akan mengembalikan indeks dari elemen dengan nilai peluang tertinggi di antara 15 kelas yang ada untuk setiap gambar pada test_data. Adapun untuk kelas sebenarnya dapat diperoleh melalui atribut classes pada test_data.
Perlu diperhatikan, atribut classes selalu mengembalikan nilai kelas sesuai urutan subdirektori (kelas) dan gambar di dalam subdirektori test. Oleh karena itu jika ingin membuat confussion matrix, penting untuk mengatur parameter shuffle=False saat pembuatan test_data agar urutan kelas hasil prediksi sama dengan urutan kelas yang sebenarnya.
Python
import seaborn as sns
import numpy as np
from sklearn.metrics import confusion_matrix
# Mengkonversi peluang prediksi menjadi kelas
y_pred_class = np.argmax(predictions, axis=1)
# Mendapatkan kelas sebenarnya dari test_data
y_true_class = test_data.classes
# membuat confusion matrix
conf_matrix = confusion_matrix(y_true_class, y_pred_class)
# menampilkan confusion matrix dalam bentuk heatmap
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(
conf_matrix,
annot=True,
annot_kws={"fontsize": 10},
fmt=".0f",
linewidth=0.5,
square=True,
)
plt.show()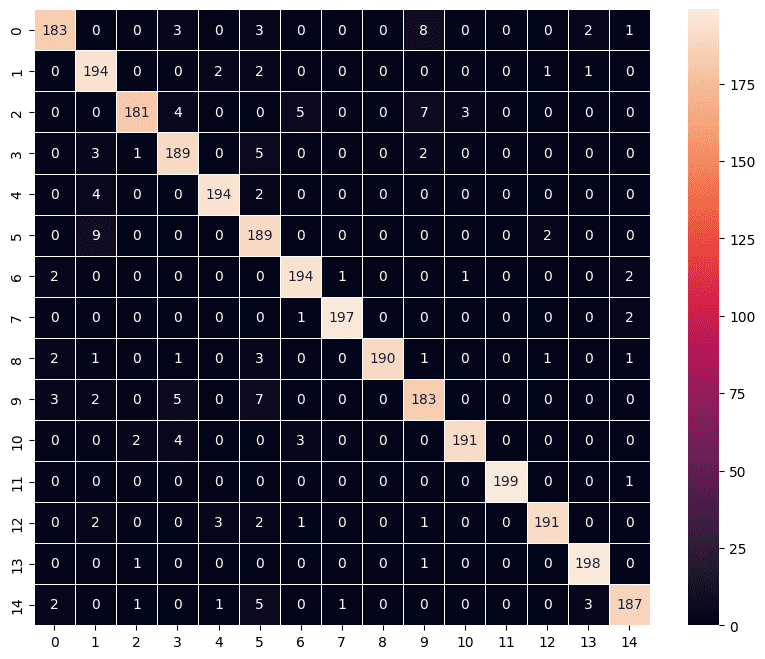
Transfer Learning dengan Pretrained Model
Pretrained model adalah model deep learning yang sudah dilatih sebelumnya pada dataset besar dan kompleks. Beberapa contoh pretrained model yaitu ImageNet, Open Images dan sebagainya. Model-model ini telah melalui proses pelatihan yang memakan waktu dan sumber daya komputasi yang besar untuk mengidentifikasi dan mempelajari pola-pola visual dari jutaan gambar.
Penggunaan pretrained model memiliki beberapa keuntungan. Pertama, pretrained model telah mempelajari fitur-fitur umum dari data gambar yang luas sehingga kita dapat memanfaatkan dan menerapkannya pada tugas-tugas klasifikasi atau deteksi gambar yang berbeda tanpa perlu melatih model dari awal. Pretrained model juga umumnya memiliki kemampuan yang lebih baik dalam mengenali objek-objek umum dalam gambar dibandingkan dengan model yang dilatih pada dataset yang lebih kecil. Model-model pretrained ini telah mempelajari pola-pola visual umum dan memiliki representasi fitur yang lebih kuat.
Dalam banyak kasus, pretrained model seperti VGG16, ResNet, atau InceptionNet dapat menjadi titik awal yang baik dalam tugas-tugas klasifikasi gambar. Kita dapat memanfaatkan arsitektur model tersebut dan menyesuaikannya dengan kebutuhan kita dengan menambahkan layer-layer khusus di atasnya.
Dengan menggunakan pretrained model, kita dapat menghemat waktu dan sumber daya yang diperlukan untuk melatih model dari awal. Ini memungkinkan kita untuk lebih fokus pada pengolahan data, fine-tuning model, atau menambahkan layer-layer khusus untuk memenuhi kebutuhan tugas spesifik.
Menggunakan Pretrained Model
Pada contoh berikut, kita akan membangun model berdasarkan pretrained model VGG16. Langkah-langkah yang dilakukan pada dasarnya sama saja seperti model sebelumnya. Perbedaan utamanya yaitu pada lapisan awal kita tidak menggunakan lConv2D melainkan menggunakan model pre-trained dalam hal ini VGG16.
Pada pembuatan variabel base_model yang menggunakan arsitektur VGG16 terdapat beberapa parameter yang kita atur. Parameter include_top=False menunjukkan bahwa kita tidak mengikutkan layer fully connected teratas dari VGG16. Parameter weights='imagenet' menunjukkan bahwa kita menggunakan bobot yang telah dilatih sebelumnya pada dataset ImageNet. Parameter input_shape=(224, 224, 3), seperti halnya pada model_1, menunjukkan ukuran input gambar yang akan digunakan oleh model.
Dalam kode ini, kita jika membekukan (freeze) parameter dari model VGG16, yang berarti parameter-parameter tersebut tidak akan diperbarui selama pelatihan model. Hal ini dilakukan karena kita ingin menggunakan bobot yang sudah dilatih sebelumnya pada model VGG16 dan hanya melatih lapisan-lapisan baru yang kita tambahkan.
Setelah apisan VGG16, kita dapat menambah beberapa lapisan lainnya misal pada contoh ini kita menambahkan 3 lapisan. Pertama lapisan Flatten, kedua lapisan Dense dengan 128 neuron dengan fungsi aktivasi "relu" dan lapisan Dense terakhir sama seperti model_1 memiliki 15 neuron dengan fungsi aktivasi "softmax".
Hasil pelatihan model_2 menunjukkan performa yang sangat baik walaupun pelatihan hanya dilakukan dalam53 epoch saja. Akurasi model_2 pada data validasi memiliki nilai mencapai 0.9887. Nilai ini menunjukkan model_2 mampu mempredisi secara tepat 98,87% gambar pada data validasi. Nilai ini juga melampaui performa yang kita peroleh pada model_1 dengan akurasi 0.9420.
Python
from tensorflow.keras.applications import VGG16 from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Dense, Flatten # Membuat base model menggunakan VGG16 pre-trained weights base_model = VGG16(include_top=False, weights='imagenet', input_shape=(224, 224, 3)) # Membekukan parameter pada base model base_model.trainable = False # Membuat model sequensial model_2 = Sequential() # Menambahkan base model ke model sequensial model_2.add(base_model) # Menambahkan beberapa layer Dense model_2.add(Flatten()) model_2.add(Dense(128, activation='relu')) model_2.add(Dense(15, activation='softmax')) # Compile model model_2.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) # Melihat ringkasan model model_2.summary()
# OUTPUT
Epoch 1/5
469/469 [==============================] - 194s 405ms/step - loss: 0.6118 - accuracy: 0.8326 - val_loss: 0.1102 - val_accuracy: 0.9723
Epoch 2/5
469/469 [==============================] - 189s 403ms/step - loss: 0.1854 - accuracy: 0.9424 - val_loss: 0.1003 - val_accuracy: 0.9703
Epoch 3/5
469/469 [==============================] - 198s 421ms/step - loss: 0.1294 - accuracy: 0.9597 - val_loss: 0.0794 - val_accuracy: 0.9793
Epoch 4/5
469/469 [==============================] - 195s 416ms/step - loss: 0.1093 - accuracy: 0.9667 - val_loss: 0.0549 - val_accuracy: 0.9823
Epoch 5/5
469/469 [==============================] - 192s 409ms/step - loss: 0.1105 - accuracy: 0.9643 - val_loss: 0.0424 - val_accuracy: 0.9887
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 7, 7, 512) 14714688
flatten_1 (Flatten) (None, 25088) 0
dense_1 (Dense) (None, 128) 3211392
dense_2 (Dense) (None, 15) 1935
=================================================================
Total params: 17,928,015
Trainable params: 3,213,327
Non-trainable params: 14,714,688
_________________________________________________________________Menyimpan dan Memuat Model
Setelah model dilatih, kita dapat menyimpan model_2 sama seperti sebelumnya menggunakan fungsi save_model dari modul tensorflow.keras.models. Berikutnya, model yang sudah disimpan, dapat digunakan kembali dengan memuatnya melalui fungsi load_model dari modul yang sama.
Python
from tensorflow.keras.models import save_model, load_model
# menyimpan model yang sudah dilatih
model_2.save("model_2.h5")
# membuka model yang sudah dilatih
model_2 = load_model("model_2.h5")
model_2.summary()# OUTPUT
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
vgg16 (Functional) (None, 7, 7, 512) 14714688
flatten_1 (Flatten) (None, 25088) 0
dense_1 (Dense) (None, 128) 3211392
dense_2 (Dense) (None, 15) 1935
=================================================================
Total params: 17,928,015
Trainable params: 3,213,327
Non-trainable params: 14,714,688
_________________________________________________________________Evaluasi dan prediksi
Sama seperti model sebelumnya, kita dapat melakukan evaluasi model menggunakan data test. Dari hasil evaluasi di bawah ini, diperoleh performa model_2 sangat baik dengan nilai akurasi mencapai 0,9877. Dengan kata lain model_2 mampu memprediksi tepat 2.963 dari 3.000 gambar pada data test. Jumlah ini juga jauh lebih unggul dibandingkan model_1. Nilai ini juga bisa jadi dapat ditingkatkan lagi dengan menambah jumlah epoch, jumlah lapisan ataupun melakukan pengaturan lainnya pada model_2 tersebut.
Kita juga memvisualisasikan hasil prediksi model_2 dalam bentuk confussion matrix seperti yang ditampilkan pada output kode di bawah ini.
Python
print(model_2.evaluate(test_data))
predictions = model_2.predict(test_data)
# Mengkonversi prediksi menjadi label kelas
y_pred_class = np.argmax(predictions, axis=1)
y_true_class = test_data.classes
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(
confusion_matrix(y_true_class, y_pred_class),
annot=True,
annot_kws={"fontsize": 10},
fmt=".0f",
linewidth=0.5,
square=True,
)
plt.show()# OUTPUT 94/94 [==============================] - 2759s 30s/step - loss: 0.0476 - accuracy: 0.9877 [0.047620803117752075, 0.987666666507721]
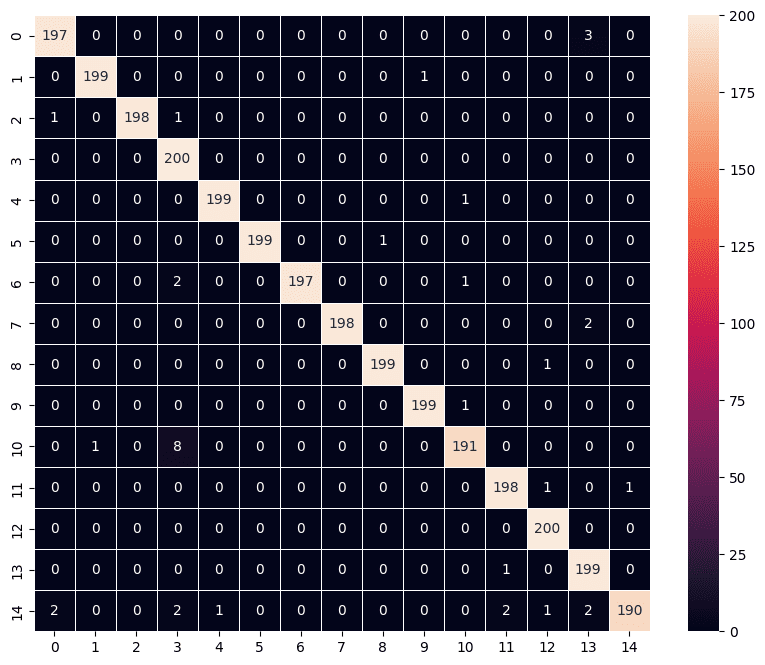
Hasil model_2 menunjukkan bahwa menggunakan pretrained model dapat memberikan keunggulan dengan memberikan performa yang lebih baik bahkan dengan menggunakan lebih sedikit epoch pada proses pelatihan. Hal ini tentu saja tidak lepas dari fakta bahwa arsitektur VGG16 sudah didesain dan dilatih sedemikian rupa serta penggunaan dataset yang besar. Jika ingin memahami lebih jauh arsitektur VGG16, dapat di lihat pada tautan berikut : Understanding VGG16: Concepts, Architecture, and Performance (datagen.tech). Tulisan asli dari rancangan VGG16 juga dapat dilihat di sini : Very Deep Convolutional Networks for Large-Scale Image Recognition.
Kode pada tulisan ini juga dapat diakses pada tautan berikut : https://www.kaggle.com/cahyaalkahfi/cnn-vegetables-ipynb
Ringkasan
Pada tulisan ini kita sudah membahas tahapan dalam membangun model convolution neural network (CNN) menggunakan TensorFlow. Beberapa hal yang disampaikan meliputi penyiapan dataset, pembuatan arsitektur, kompilasi, pelatihan model sampai dengan evaluasi performa model. Selain itu kita juga membuat model dengan memanfaatkan pretrained model VGG16 yang mana memberikan performa sangat baik. Performa tersebut mungkin saja masih dapat ditingkatkan dengan menambahkan lapisan-lapisan baru ataupun memperbanyak epoch pada tahap pelatihan.
Selamat mencoba!
Tulisan Lainnya