Model Neural Network pada R Menggunakan Library Keras

Neural network merupakan algoritma dalam machine learning yang sering digunakan untuk memproses data dan melakukan tugas-tugas seperti klasifikasi, regresi, pengenalan pola hingga pembuatan model generatif. Terdapat berbagai pustaka yang dapat digunakan untuk membuat model, salah satu pustaka yang populer adalah Keras. Keras adalah library open-source yang dapat digunakan untuk membuat model neural network pada berbagai bahasa pemrograman, termasuk R.
Dalam tulisan ini, kita akan fokus pada pembuatan model neural network menggunakan Keras pada bahasa R. Tahapan yang akan dilakukan antara lain penyiapan data, pemodelan neural network, melatih model, mengevaluasi model, dan membuat grafik untuk melihat hasil pelatihan model.
Instalasi pada Lingkungan Kerja R
Tensorflow dan Keras di R adalah wrapper yang memungkinkan pengguna R untuk menggunakan fungsi dan objek dari Tensorflow dan Keras yang ditulis dalam Python. Hal ini dapat dilakukan karena TensorFlow dan Keras memiliki API Python yang dapat digunakan dari R melalui paket reticulate.
R
library(reticulate)
virtualenv_create("r-reticulate", python = install_python())Untuk menggunakan Keras pada R maka perlu menginstall package keras dan tensorflow (sebagai backend dari keras). Adapun cara menginstal keras, tensorflow serta library pendukung lainnya pada virtual environment dapat dilakukan menggunakan kode berikut:
R
install.packages("tensorflow")
install.packages("keras")
tensorflow::install_tensorflow()
keras::install_keras()Neural Network untuk Model Klasifikasi
Pada bagian pertama akan dibahas mengenai pemodelan neural network menggunakan Keras untuk permasalahan klasifikasi. Library yang diperlukan adalah keras dan caret. Libray keras digunakan untuk pemodelan neural network dan caret digunakan untuk features scaling, partisi data serta menampilkan metrik evaluasi.
Penyiapan dan Preprocessing Data
Dataset yang digunakan yaitu data level obesitas yang tersedia di https://archive.ics.uci.edu/ dan dapat diunduh pada url berikut Obesity Level.
Data set ini terdiri dari 2.111 observasi dengan 17 peubah. Terdapat 9 peubah bertipe kategorik dan 8 peubah numerik. Peubah Nobeyesdad merupakan peubah target bertipe kategorik dengan 7 kelas. Peubah ini menunjukkan kondisi berat badan seseorang mulai dari Insufficient_Weight hingga overweight_level_II. Untuk peubah kategorik lainnya memiliki jumlah kategori bervariasi mulai dari 2 kategori hingga 5 kategori.
Library keras tidak dapat memproses secara langsung fitur kategorik dalam pemodelan Neural Network, sehingga perlu dilakukan encoding terlebih dahulu. Terdapat dua tipe yang biasa digunakan yaitu Label Encoder dan One-Hot Encoder (Peubah Dummy). Proses One-Hot Encoding pada keras dapat dilakukan menggunakan fungsi to_categorical. Fungsi ini akan mengonversi kolom kategorik menjadi matriks dengan tipe data biner. Sebagai contoh, jika terdapat 3 kategori, maka hasil encoding akan memiliki 3 kolom dengan nilai 0 atau 1 pada setiap kolomnya. Saat menggunakan fungsi ini, kita biasanya mengurangi nilai vektor kelas dengan 1, hal ini dilakukan karena indeks pada matriks dimulai dari 0, sedangkan nilai kelas pada data biasanya dimulai dari 1.
Pembagian data latih dan data uji dapat menggunakan fungsi createDataPartition. Dataset akan dibagi menjadi 70% data latih dan 30% data uji.
Setiap peubah penjelas pada data latih dan data uji selanjutnya dilakukan scaling. Metode scaling yang kita gunakan adalah normalize atau minmax scaling dimana setiap peubah akan ditrasnformasi sehingga memiliki nilai pada interval 0-1. Proses ini dapat dilakukan menggunakan fungsi preProcess dengan mengatur parameter method=c("range"). Kita dapat juga melakukannya secara manual menggunakan formula sebagai berikut:
$$x_{i\;scaled}=\frac{x_i – min(x)}{max(x)-min(x)}$$
Selanjutnya kita juga perlu melakukan encoding pada peubah target. Peubah target pada model klasifikasi multikelas perlu kita lakukan one-hot encoding karena output layer harus memiliki jumlah neuron yang sama dengan jumlah kelas outputnya. Misalnya, pada dataset ini memiliki 7 kelas output, maka output layer akan memiliki 7 neuron dimana setiap neuron merepresentasikan probabilitas suatu observasi masuk ke masing-masing kelas tersebut.
R
# Library yang digunakan
library(keras)
library(caret)
# Memuat dataset
data <- read.csv("ObesityDataSet.csv", stringsAsFactors = T, )
# Melihat beberapa data pertama
head(data)
# struktur dataset
str(data)
# Ringkasan dataset
summary(data)
# Mengecek missing value
colSums(is.na(data))
# One-Hot Encoding features kategorik
data$Gender <- to_categorical(as.integer(data$Gender)-1)
data$family_history_with_overweight <-
to_categorical(as.integer(data$family_history_with_overweight)-1)
data$FAVC <- to_categorical(as.integer(data$FAVC)-1)
data$CAEC <- to_categorical(as.integer(data$CAEC)-1)
data$SMOKE <- to_categorical(as.integer(data$SMOKE)-1)
data$SCC <- to_categorical(as.integer(data$SCC)-1)
data$CALC <- to_categorical(as.integer(data$CALC)-1)
data$MTRANS <- to_categorical(as.integer(data$MTRANS)-1)
# Contoh hasil Encoding untuk kolom MTRANS
head(data$MTRANS)
# Membagi data menjadi data latih dan data uji
set.seed(123)
train.index <- createDataPartition(data$NObeyesdad, p = 0.7, list = FALSE)
train <- data[train.index, ]
test <- data[-train.index, ]
# Features Scaling MinMax (0, 1)
preprocessParams <- preProcess(train[, -17], method=c("range"))
train_X <- as.matrix(predict(preprocessParams, train[, -17]))
test_X <- as.matrix(predict(preprocessParams, test[, -17]))
# One-Hot Encoding pada peubah target
train_y <- to_categorical(as.integer(train[, 17])-1)
test_y <- to_categorical(as.integer(test[, 17])-1)Fungsi yang digunakan untuk membuat model neural network menggunakan keras adalah fungsi keras_model_sequential().
Kita tidak perlu menentukan secara khusus parameter untuk input layer. Jumlah neuron pada input layer ditentukan melalui parameter input_shape pada hidden layer pertama. Nilai untuk parameter input_shape tersebut adalah sama dengan banyaknya peubah penjelas dari data yang digunakan.
selanjutnya kita menambahkan 1 hidden layer pada model. Penambahan layer dilakukan menggunakan fungsi layer_dense. Sebagai contoh, hidden layer kita set memiliki 64 neuron berdasarkan nilai parameter units . Adapun fungsi aktivasi yang digunakan pada hidden layer ini adalah fungsi Rectified Linier Unit (ReLU).
Layer terakhir adalah output layer. Seperti yang dijelaskan pada bagian sebelumnya, untuk pemodelan klasifikasi jumlah neuron pada output layer adalah sebanyak jumlah kelas dari outputnya (dalam hal ini 7 kelas). Fungsi aktivasi yang dapat digunakan dalam klasifikasi multi kelas adalah fungsi aktivasi softmax. (lihat: Daftar Fungsi Aktivasi).
Proses selanjutnya, kita perlu memanggil fungsi compile untuk menentukan beberapa kriteria pelatihan model seperti loss function yang digunakan, optimizer, metrics serta beberapa kriteria lainnya. Beberapa kriteria yang kita atur pada model ini adalah sebagai berikut:
- Loss Function yang dapat digunakan pada kasus multikelas adalah
categorical_crossentropyatausparse_categorical_crossentropy. Pada contoh ini kita menggunakancategorical_crossentropykarena label akan kita simpan dalam bentuk One Hot Encoding. (lihat: Daftar Loss Function). - Optimizer : algoritma yang digunakan dalam penentuan nilai bobot dan bias selama proses pelatihan. Beberapa optimizer yang dapat digunakan adalah Stochastic Gradient Descent (SGD), Adam, RMSprop, dan Adagrad. (lihat: Daftar Optimizer).
- Parameter metrics digunakan untuk menentukan metrik evaluasi yang digunakan untuk mengukur performa model saat pelatihan dan pengujian. Metrik evaluasi yang umum digunakan pada model klasifikasi adalah
accuracy.
R
# Membuat model neural network dengan 1 hidden layer
model <- keras_model_sequential() %>%
layer_dense(units = 64, activation = "relu", input_shape = ncol(train_X)) %>%
layer_dense(units = ncol(train_y), activation = "softmax")
# Mengkompilasi model
model %>% compile(
loss = "categorical_crossentropy",
optimizer = "adam",
metrics = c("accuracy")
)
summary(model)Output
Model: "sequential_3" ______________________________________________________________________ Layer (type) Output Shape Param # ====================================================================== dense_9 (Dense) (None, 64) 2048 dense_8 (Dense) (None, 7) 455 ====================================================================== Total params: 2,503 Trainable params: 2,503 Non-trainable params: 0 ______________________________________________________________________
Setelah proses kompilasi, selanjutnya adalah melatih model menggunakan fungsi fit. Beberapa parameter yang dapat diataur adalah epochs, batch_size dan validation_split.
Epoch: mengacu pada satu putaran pelatihan pada seluruh data latih yang ada. Dalam setiap epoch, model dijalankan melalui seluruh data pelatihan sebanyak satu kali. Dimana pada setiap iterasi, parameter model diperbarui dengan menggunakan algoritma optimasi yang tentukan.Batch_size: Jumlah sampel data yang dihitung dalam satu iterasi pada saat pelatihan. Jumlah sampel data dalam batch ini akan mempengaruhi waktu komputasi dan memori yang dibutuhkan dalam proses pelatihan model. Semakin besar batch, semakin sedikit iterasi yang dibutuhkan untuk menyelesaikan satu epoch, namun membutuhkan memori yang lebih besar.validation_split: pada proses pelatihan model, data dibagi menjadi dua bagian dimana nilai parametervalidation_splitmenunjukkan proporsi data yang akan digunakan sebagai data validasi untuk mengukur performa model saat pelatihan.
Kita dapat juga menampilkan plot yang menunjukkan hasil pelatihan pada setiap epoch menggunakan fungsi plot.
R
# Melatih model history <- model %>% fit( train_X, train_y, shuffle = T, epochs = 100, batch_size = 32, validation_split = 0.2 ) # Menampilkan plot pembelajaran model pada setiap epoch plot(history)
Output
Epoch 1/100 37/37 [==============] - 1s 23ms/step - loss: 1.8513 - accuracy: 0.1792 - val_loss: 2.8549 - val_accuracy: 0.0000 Epoch 2/100 37/37 [==============] - 0s 8ms/step - loss: 1.6481 - accuracy: 0.3516 - val_loss: 3.4404 - val_accuracy: 0.0068 Epoch 3/100 37/37 [==============] - 0s 7ms/step - loss: 1.5303 - accuracy: 0.4413 - val_loss: 3.7054 - val_accuracy: 0.0068 ... Epoch 98/100 37/37 [==============] - 0s 7ms/step - loss: 0.3273 - accuracy: 0.9146 - val_loss: 0.1722 - val_accuracy: 1.0000 Epoch 99/100 37/37 [==============] - 0s 7ms/step - loss: 0.3243 - accuracy: 0.9163 - val_loss: 0.1868 - val_accuracy: 1.0000 Epoch 100/100 37/37 [==============] - 0s 7ms/step - loss: 0.3194 - accuracy: 0.9180 - val_loss: 0.1723 - val_accuracy: 1.0000
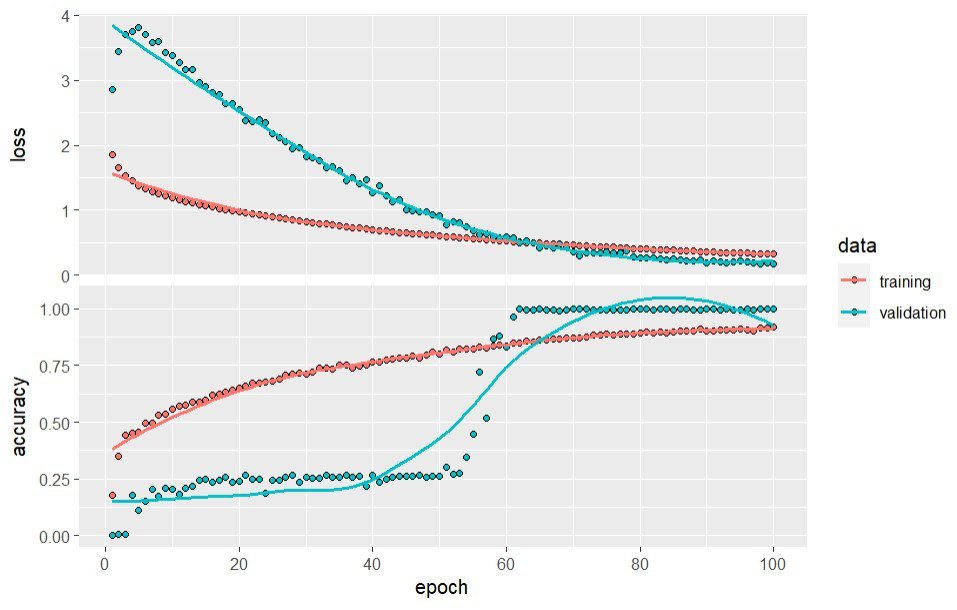
Berdasarkan hasil evaluasi model di atas memberikan hasil yang sangat baik, dimana nilai akurasi dalam proses validasi pada epoch ke-100 mencapai nilai 1,000 dengan nilai loss 0,1723.
Model yang sudah dilatih selanjutnya perlu dievaluasi menggunakan data uji. Proses evaluasi ini dapat dilakukan menggunakan fungsi evaluate. Hasil evaluasi pada data uji menunjukkan nilai akurasi sekitar 0,85 dengan loss sebesar 0,45. Nilai ini dapat dikatakan sudah cukup baik namun pada bagian selanjutnya kita akan mencoba meningkatkan performa model dengan menambah jumlah hidden layer yang digunakan.
R
# Mengevaluasi model menggunakan data uji scores <- model %>% evaluate(test_X, test_y) print(scores)
Output
20/20 [==============================] - 0s 2ms/step - loss: 0.4504 - accuracy: 0.8497
loss accuracy
0.4503970 0.8496835 Untuk membuat model Neural Network dengan 2 hidden layer dapat dilakukan dengan menambahkan fungsi layer_dense sebelum output layer. Contoh di bawah ini, menunjukkan model dengan 2 hidden layer dimana hidden layer pertama memiliki 128 neuron dengan fungsi aktivasi ReLU sementara hidden layer kedua memiliki 64 neuron dengan fungsi aktivasi ReLU.
Selain itu, pada hidden layer pertama dan kedua juga ditambahkan layer_dropout dengan nilai rate sebesar 0.2. Fungsi b` ini adalah salah satu bentuk regularisasi pada model neural network untuk menghindari masalah overfitting. Fungsi ini secara acak akan mengabaikan sebagian neuron pada layer sebelumnya pada saat proses pelatihan. Proses ini bertujuan membuat model untuk belajar dengan cara yang lebih robust dan mengurangi ketergantungan pada unit-unit tertentu, dengan harapan menghasilkan model yang lebih tergeneralisasi. Pada contoh ini setiap neuron pada hidden layer pertama maupun kedua memiliki peluang 20% untuk diabaikan dalam setiap iterasinya.
R
# Membuat model neural network dengan 2 hidden layer
model <- keras_model_sequential() %>%
layer_dense(units = 128, activation = "relu", input_shape = ncol(train_X)) %>%
layer_dropout(0.2) %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dropout(0.2) %>%
layer_dense(units = ncol(train_y), activation = "softmax")
# Mengkompilasi model
model %>% compile(
loss = "categorical_crossentropy",
optimizer = "adam",
metrics = c("accuracy")
)
# Melakukan pelatihan model
history <- model %>% fit(
train_X, train_y,
shuffle = T,
epochs = 100,
batch_size = 32,
validation_split = 0.2,
verbose = F # tidak menampilkan teks ouput pada setiap epoch
)
summary(model)
# Menampilkan plot pembelajaran model pada setiap epoch
plot(history)
# Mengevaluasi model menggunakan data uji
scores <- model %>% evaluate(test_X, test_y)
print(scores)Output
Model: "sequential_4"
______________________________________________________________________
Layer (type) Output Shape Param #
======================================================================
dense_12 (Dense) (None, 128) 4096
dropout_5 (Dropout) (None, 128) 0
dense_11 (Dense) (None, 64) 8256
dropout_4 (Dropout) (None, 64) 0
dense_10 (Dense) (None, 7) 455
======================================================================
Total params: 12,807
Trainable params: 12,807
Non-trainable params: 0
______________________________________________________________________
# Skor Evaluasi
20/20 [==============================] - 0s 2ms/step - loss: 0.2651 - accuracy: 0.9288
loss accuracy
0.2650511 0.9287975 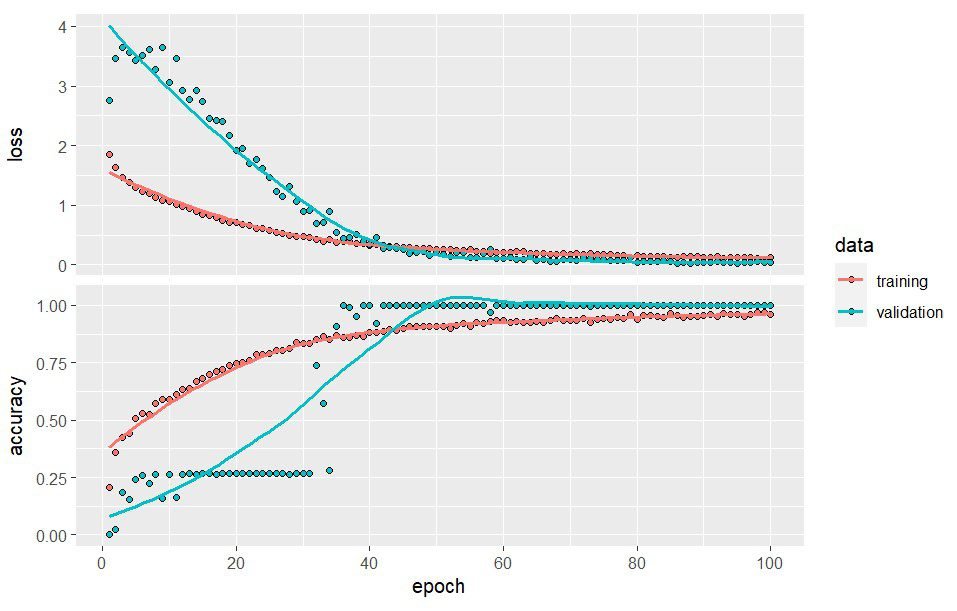
Hasil evaluasi pada model menunjukkan nilai akurasi yang lebih tinggi dari model sebelumnya yaitu dengan tingkat akurasi pada data uji sebesar 0.929 dan loss sebesar 0.265.
Sebagai catatan, hasil ini bisa berbeda-beda karena di dalamnya terdapat beberapa proses acak yang ditentukan oleh keras, seperti penentuan bobot awal ataupun pemilihan neuron yang diabaikan melalui layer_dropout. Namun tentu saja secara umum hasil yang diperoleh seharusnya tidak akan jauh berbeda dibandingkan hasil yang tersaji pada tulisan ini.
Prediksi Data
Prediksi dapat dilakukan denngan memanggil fungsi predict. Pada model dengan output multikelas menggunakan fungsi aktivasi softmax, hasil prediksi yang diberikan adalah matriks dengan jumlah kolom sebanyak jumlah kategori outputnya. Setiap kolom menunjukkan nilai peluang suatu observasi masuk ke dalam kategori kolom tersebut.
R
prediksi <- predict(model, test_X) head(prediksi)
Output
20/20 [==============================] - 0s 1ms/step
[,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] 5.933895e-05 2.474980e-01 1.915716e-07 2.653499e-12 8.932350e-12 0.1670825630 5.853599e-01
[2,] 1.500821e-11 2.014924e-07 6.133271e-01 9.219928e-04 1.326193e-02 0.0013094997 3.711792e-01
[3,] 9.424188e-13 5.953915e-06 4.740215e-06 5.788871e-08 1.386582e-11 0.0032721090 9.967172e-01
[4,] 1.246165e-13 1.146619e-08 9.881797e-01 1.178849e-05 5.719052e-05 0.0012908976 1.046043e-02
[5,] 2.483933e-03 9.972294e-01 1.298267e-16 3.080393e-20 4.473008e-22 0.0002861889 3.892189e-07
[6,] 3.698068e-06 9.917549e-02 1.488270e-11 1.950021e-19 1.309975e-20 0.8975430727 3.277839e-03
...Untuk menentukan kategori dengan peluang terbesar kita dapat menggunakan fungsi which.max yang dikombinasikan dengan fungsi apply.
R
label_pred <- apply(prediksi, 1, which.max) label_pred label_true <- as.integer(test$NObeyesdad) label_true
Output
# Prediksi [1] 7 3 7 3 2 6 6 6 7 2 7 2 2 2 2 6 2 1 3 1 3 2 2 ... 2 2 2 2 6 2 4 2 7 6 2 2 7 6 2 [62] 4 7 3 2 2 6 2 6 4 6 6 2 2 2 6 2 2 2 7 3 2 1 2 ... 2 6 2 2 6 2 7 2 2 2 1 3 2 2 6 [123] 2 2 2 2 2 7 3 1 2 2 6 2 2 2 2 2 1 2 2 2 6 2 2 ... 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ... [550] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 ... 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 [611] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 # Aktual [1] 7 3 7 3 2 6 6 6 7 2 7 2 2 2 2 6 2 1 3 1 3 2 2 ... 2 2 2 2 6 2 4 2 7 6 2 2 7 6 2 [62] 4 7 3 2 2 6 2 6 4 6 6 2 2 2 6 2 2 2 7 3 2 1 2 ... 2 6 2 2 6 2 7 2 2 2 1 3 2 2 6 [123] 2 2 2 2 2 7 3 1 2 2 6 2 2 2 2 2 1 2 2 2 6 2 2 ... 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 ... [550] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 ... 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 [611] 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5
Kita juga dapat menampilkan confussion matrix menggunakan fungsi confusionMatrix untuk membandingkan hasil prediksi dengan kategori sebenarnya.
R
confusionMatrix(as.factor(label_true), as.factor(label_pred))
Output
Confusion Matrix and Statistics
Reference
Prediction 1 2 3 4 5 6 7
1 75 6 0 0 0 0 0
2 5 74 0 0 0 6 1
3 0 0 98 0 0 2 5
4 0 0 1 88 0 0 0
5 0 0 0 1 96 0 0
6 0 4 0 0 0 82 1
7 0 2 1 0 0 10 74
Overall Statistics
Accuracy : 0.9288
95% CI : (0.9059, 0.9476)
No Information Rate : 0.1582
P-Value [Acc > NIR] : < 2.2e-16
Kappa : 0.9169
Mcnemar's Test P-Value : NA
Statistics by Class:
Class: 1 Class: 2 Class: 3 Class: 4 Class: 5 Class: 6 Class: 7
Sensitivity 0.9375 0.8605 0.9800 0.9888 1.0000 0.8200 0.9136
Specificity 0.9891 0.9780 0.9868 0.9982 0.9981 0.9906 0.9764
Pos Pred Value 0.9259 0.8605 0.9333 0.9888 0.9897 0.9425 0.8506
Neg Pred Value 0.9909 0.9780 0.9962 0.9982 1.0000 0.9670 0.9872
Prevalence 0.1266 0.1361 0.1582 0.1408 0.1519 0.1582 0.1282
Detection Rate 0.1187 0.1171 0.1551 0.1392 0.1519 0.1297 0.1171
Detection Prevalence 0.1282 0.1361 0.1661 0.1408 0.1535 0.1377 0.1377
Balanced Accuracy 0.9633 0.9192 0.9834 0.9935 0.9991 0.9053 0.9450Menyimpan dan Memuat Model
Model yang telah dibuat, dapat disimpan ke dalam file menggunakan fungsi save_model_tf. Selanjutnya untuk memuat model dapat menggunakan fungsi load_model_tf. Model yang sudah dimuat, dapat digunakan untuk memprediksi data baru menggunakan fungsi predict ataupun dapat juga menambah proses pelatihan model dengan data baru menggunakan fungsi fit.
R
# Menyimpan model dalam format keras
save_model_tf("model_nn.keras")
# Memuat model dari file keras
my.model <- load_model_tf("model_nn.keras")
summary(my.model)Model Regresi dengan Neural Network
Penerapan neural network untuk model regresi hampir sama dengan pemodelan klasifikasi. Perbedaannya hanya pada pengaturan output layer serta loss function dan metrics yang digunakan. Pada pemodelan regresi dimana peubah respon bertipe numerik maka jumlah units pada output layer cukup dibuat sebanyak 1 unit. Adapun untuk fungsi aktivasinya dapat menggunakan fungsi aktivasi linear.
Berikut ini contoh pemodelan neural network pada data dengan respon numerik.
Penyiapan data
Dataset yang digunakan untuk contoh adalah dataset abalone dan dapat diunduh di sini. Tujuan dari pemodelan ini adalah memprediksi umur dari abalone berdasarkan beberapa karakteristik pada hewan tersebut. Berdasarkan hasil penelitian, umur abalone dapat ditentukan dengan menghitung jumlah ring di dalam tubuh abalone dan menambahkannya dengan 1.5. Namun demikian, untuk menentukan jumlah ring tersebut merupakan pekerjaan yang sulit karena harus melakukan pembedahan pada abalone. Oleh karena itu, dengan memanfaatkan karakteristik lainnya kita akan membangun model prediksi untuk menentukan Umur dari abalone.
R
library(keras)
library(caret)
# Memuat data:
data.ab <- read.csv('abalone.csv', stringsAsFactors = T)
# Melihat Struktur dataset
str(data.ab)
# Mengecek Missing Value:
# Tidak ada missing value sehingga tidak memerlukan penanganan data
colSums(is.na(data.ab))
# Menambah kolom `Age`
data.ab$Age <- data.ab$Rings + 1.5
# Menghapus kolom `Rings`
data.ab$Rings <- NULL
head(data.ab)
# Encoding peubah kategorik
data.ab$Sex <- to_categorical(as.integer(data.ab$Sex)-1)
head(data.ab$Sex)Pada kode di atas, kita juga menambah kolom Age dan menghapus kolom Rings. Berdasarkan jurnal rujukan pada dataset ini, umur dari abalone dapat ditentukan dengan menambahkan nilai 1.5 dari peubah Rings. Oleh karena itu, untuk contoh ini kita akan membuat peubah baru dengan nama Age serta menghapus peubah Rings.
Selanjutnya kita juga perlu melakukan One-Hot Encoding pada kolom dengan tipe kategorik. Terdapat 1 kolom kategorik pada dataset ini yaitu kolom Sex yang terdiri dari 3 kategori (Male, Female, dan Infant).
Partisi Data dan Features Scaling
R
# Membagi data menjadi data latih dan data uji dengan createDataPartition
set.seed(123)
train.index <- createDataPartition(data.ab$Age, p = 0.7, list = FALSE)
train <- data.ab[train.index, ]
test <- data.ab[-train.index, ]
# Melakukan Feature Scaling min max (0, 1)
preprocessParams <- preProcess(train[, -9], method=c("range"))
train_X <- as.matrix(predict(preprocessParams, train[, -9]))
test_X <- as.matrix(predict(preprocessParams, test[, -9]))
train_y <- train[, 9]
test_y <- test[, 9]Pembuatan Model
Pengaturan model yang akan digunakan adalah menggunakan 2 hidden layer dimana masing-masing layer memiliki 64 neuron. Selain itu, untuk menghindari overfitting, kita menambahkan layer_dropout pada masing-masing layer dengan rate=0.3. Adapun untuk output layer menggunakan fungsi aktivasi linear dengan 1 neuron.
Pengaturan lainnya untuk proses kompilasi model yaitu loss menggunakan nilai mean_squared_error, optimizer menggunakan adam serta untuk metrics menggunakan 2 ukuran yaitu mean_squared_error dan mean_absolute_error.
R
# Membuat model neural network dengan 2 hidden layer
model <- keras_model_sequential() %>%
layer_dense(units = 64, activation = "relu", input_shape = ncol(train_X)) %>%
layer_dropout(0.3) %>%
layer_dense(units = 64, activation = "relu") %>%
layer_dropout(0.3) %>%
layer_dense(units = 1, activation = "linear")
# Mengkompilasi model
model %>% compile(
loss = "mean_squared_error",
optimizer = "adam",
metrics = list("mean_squared_error", "mean_absolute_error")
)
# Melakukan tahapan pelatihan model
history <- model %>% fit(
train_X, train_y,
shuffle = T,
epochs = 50,
batch_size = 32,
validation_split = 0.2,
verbose = F
)
print(model)
# Menampilkan plot pembelajaran model pada setiap epoch
plot(history)
# Mengevaluasi model menggunakan data uji
scores <- model %>% evaluate(test_X, test_y)
print(scores)
# Melakukan prediksi
prediksi <- predict(model, test_X)
head(prediksi)Output
Model: "sequential_13"
___________________________________________________________________________________
Layer (type) Output Shape Param #
===================================================================================
dense_38 (Dense) (None, 64) 704
dropout_21 (Dropout) (None, 64) 0
dense_37 (Dense) (None, 64) 4160
dropout_20 (Dropout) (None, 64) 0
dense_36 (Dense) (None, 1) 65
===================================================================================
Total params: 4,929
Trainable params: 4,929
Non-trainable params: 0
___________________________________________________________________________________
40/40 [=========] - 0s 2ms/step - loss: 5.7096 - mean_squared_error: 5.7096 - mean_absolute_error: 1.5628
loss mean_squared_error mean_absolute_error
5.70957 5.70957 1.56280
40/40 [=========] - 0s 1ms/step
[,1]
[1,] 9.644324
[2,] 9.164648
[3,] 15.413136
[4,] 12.544915
[5,] 11.205744
[6,] 9.148586
...
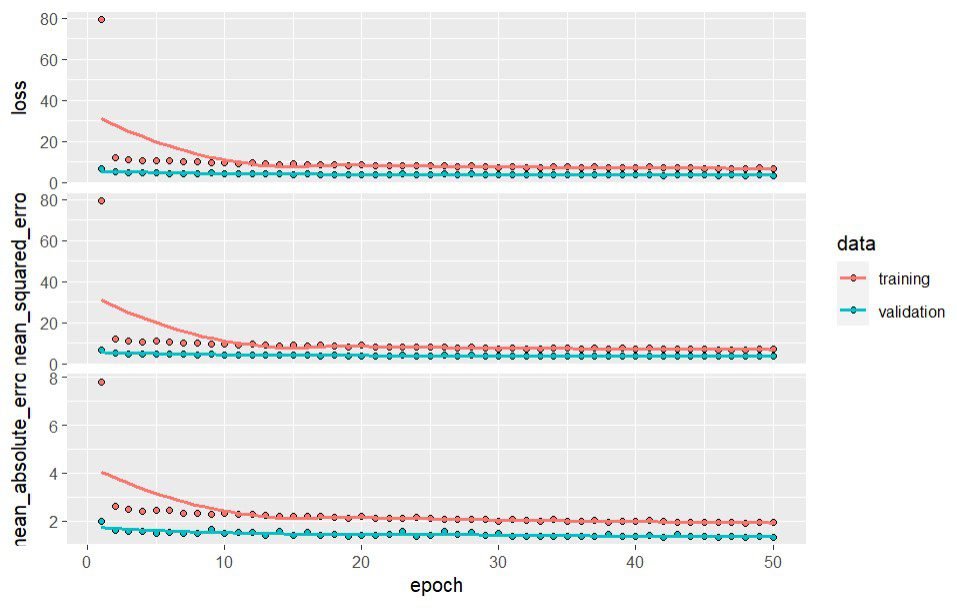
Berdasarkan model yang telah dibuat, hasil evaluasi menggunakan data uji menunjukkan nilai MSE sebesar 5,71 dan MAE sebesar 1,56. Seperti sebelumnya, Hasil ini tentu dapat kita optimalkan lagi dengan mencoba berbagai kombinasi nilai-nilai hiperparameter pada model.
Referensi
- Keras R Documentation : https://www.rdocumentation.org/packages/keras/versions/2.11.0
- Jose M Sallan (May 17, 2020). Neural networks : https://rpubs.com/jmsallan/nn_intro
- Max Pichler (June 6, 2018). An Introduction to machine learning with Keras in R: https://www.r-bloggers.com/2018/06/an-introduction-to-machine-learning-with-keras-in-r/







