Model Regresi Linier Ridge Menggunakan Scikit-Learn

Regresi Ridge atau disebut juga Regularisasi L2 merupakan salah satu bentuk regularisasi peubah pada model regresi. Koefisien regresi ridge diperoleh dengan meminimumkan Residual Sum of Squares (RSS) seperti pada model regresi (OLS) ditambah dengan penalti $\lambda \sum{(\beta_j)^2}$. Besaran penalti dikontrol melalui koefisien $\lambda$ dimana semakin besar nilai $\lambda$, maka nilai koefisien regresi akan semakin mendekati 0.
Berbeda dengan regularisasi menggunakan LASSO, walaupun nilai koefisien regresi Ridge dapat dibuat sekecil mungkin menuju 0, namun tidak akan pernah tepat bernilai 0. Selain itu, sangat penting untuk menentukan nilai $\lambda$ yang tepat untuk memperoleh model yang optimal.
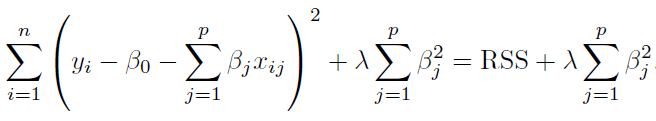
Pada tulisan ini, kita akan membangun model Regresi Ridge menggunakan library scikit-learn pada bahasa pemrograman python. Selain itu, kita akan membandingkan hasilnya dengan model regresi linier biasa (tanpa regularisasi) serta melakukan tuning hyperparameter untuk menentukan nilai lambda yang optimal.
Penyiapan Data
Dataset yang akan digunakan pada pembuatan model Ridge merupakan data simulasi dan dapat di-download pada link berikut:
Python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv("data_simulasi.csv")
data.info()Output
<class 'pandas.core.frame.DataFrame'> RangeIndex: 10000 entries, 0 to 9999 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 X1 10000 non-null float64 1 X2 10000 non-null float64 2 X3 10000 non-null float64 3 X4 10000 non-null float64 4 X5 10000 non-null float64 5 X6 10000 non-null float64 6 X7 10000 non-null float64 7 X8 10000 non-null float64 8 X9 10000 non-null float64 9 X10 10000 non-null float64 10 Y 10000 non-null float64 dtypes: float64(11) memory usage: 859.5 KB
Dataset terdiri dari 10 peubah bebas yaitu X1, X2 sampai X10 dengan semua data bertipe numerik. Adapun peubah Y sebagai peubah respon juga bertipe numerik. Total observasi dalam dataset adalah sebanyak 10.000.
Python
# Menghitung nilai korelasi corr = data.corr() mask = np.triu(np.ones_like(corr, dtype=bool)) cmap = sns.diverging_palette(230, 20, as_cmap=True) sns.heatmap(corr, mask=mask, cmap=cmap, vmax=1, center=0, linewidths=.1)
Output
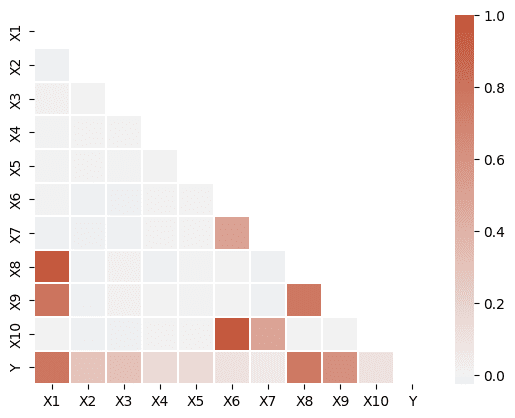
Pada dataset yang digunakan, terdapat beberapa peubah yang memiliki korelasi tinggi, seperti X1 dengan X8 dan X9, x6 dan X10, X8 dan X9. Dimana, dalam regresi linier, khususnya untuk inferensia, kemungkinan terdapat problem multikolinearitas pada model. Hasil uji signifikansi signifikansi peubah menjadi kurang reliabel untuk digunakan.
Namun demikian, tulisan ini berfokus pada bagaimana membentuk model prediksi terbaik menggunakan regresi ridge, sehingga kita tidak akan melakukan pengecekan terlalu jauh atau penanganan apapun untuk kondisi tersebut. Secara umum kondisi multikolinearitas tidak mempengaruhi performa model dalam memprediksi.
Untuk hubungan masing-masing peubah X dengan peubah Y juga tampak bervariasi, seperti X1, X8, dan X9 memiliki korelasi yang cukup besar dengan peubah Y, sementara beberapa lainnya relatif kecil.
Pembagian Data dan Features Scaling
Proses splitting data menjadi data training dan testing penting dilakukan dalam pemodelan machine learning. Data training akan digunakan sebagai dasar pembentukan model. Adapun evaluasi model dilakukan berdasarkan data testing. Pengujian model dengan data yang berbeda agar evaluasi menjadi lebih “fair” dan mengurangi kemungkinan model overfitting.
Untuk proses splitting dapat menggunakan fungsi train_test_split dari modul sklearn.model_selection. Pada contoh ini kita menggunakan proporsi 70% sebagai data training dan 30% data testing.
Selanjutnya kita juga perlu melakukan features scaling. Dalam hal ini kita akan menggunakan fungsi StandardScaler dari modul sklearn.preprocessing. Fungsi ini akan membuat setiap fitur memiliki rataan 0 dan standar deviasi 1. Dengan begitu, skala dan rentang nilai pada semua fitur relatif sama.
Dengan data yang sudah terstandardisasi, nilai koefisien pada model secara mutlak menunjukkan besar kecilnya kontribusi fitur tersebut terhadap peubah responnya. Semakin besar nilai koefisien maka semakin besar kontribusinya terhadap nilai peubah respon dan begitu pula sebaliknya.
Python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
X = data.drop("Y", axis=1)
y = data["Y"]
# membuat data training dan testing
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=100)
# features scaling
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.fit_transform(X_test)Model Regresi Linear
Model pertama yang akan dibuat adalah model regresi linear (OLS) tanpa regularisasi. Fungsi pada sklearn yang dipakai adalah fungsi LinearRegression dari modul sklearn.linear_model.
Python
from sklearn.linear_model import LinearRegression model_reg = LinearRegression() # Fitting model model_reg.fit(X_train, y_train)
Setelah model terbentuk, langkah berikutnya adalah mengeevaluasi model. Terdapat banyak metrik yang dapat digunakan untuk mengukur performa model regresi. Di sini kita akan menggunakan Root Mean Square Error (RMSE) atau akar dari MSE. Jika diinginkan, kita dapat menghitung nilai MSE secara manual dengan membandingkan nilai prediksi terhadap nilai yang sebenarnya. Namun pada sklearn terdapat fungsi mean_squared_error yang dapat kita gunakan langsung.
Python
from sklearn.metrics import mean_squared_error
# Prediksi data testing
y_pred_reg = model_reg.predict(X_test)
# menghitung RMSE model regresi pada data testing
rmse_reg = mean_squared_error(y_test, y_pred_reg)**0.5
print("RMSE (Testing):", rmse_reg)
print(model_reg.coef_)Output
RMSE (Testing): 10.031543304211139
# (Koef X1 - X10)
array([20.74785254, 8.0149942 , 7.84860767, 3.97249809, 3.81190903,
3.06322583, 0.32076385, -0.48497973, 0.11595971, -0.26297624])Dari hasil di atas diperoleh RMSE untuk model regresi linier adalah sebesar 10,0315. Selanjutnya, untuk melihat koefisien dari masing-masing peubah dapat mengakses properti coef_. Berdasarkan nilai koefisien regresi di atas, dapat dinyatakan bahwa X1 memiliki kontribusi paling besar dibandingkan peubah lainnya terhadap nilai peubah respon (Y).
Regresi Ridge
Untuk membuat model regresi Ridge kita menggunakan fungsi Ridge dari modul sklearn.linear_model. Pada fungsi Ridge, konstanta lambda ditentukan melalui parameter alpha.
Python
from sklearn.linear_model import Ridge
# Model Ridge dengan alpha=1
model_ridge = Ridge(alpha=1)
# Fitting model Ridge
model_ridge.fit(X_train, y_train)
# prediksi data testing
y_pred_ridge = model_ridge.predict(X_test)
# menghitung RMSE model Ridge pada data testing
rmse_ridge = mean_squared_error(y_test, y_pred_ridge)**0.5
print("RMSE (Testing):", rmse_ridge)
print("Koefisien :")
print(model_ridge.coef_)Output
# Output RMSE (Testing): 10.031330766086805 Koefisien : [20.64883333 8.01381231 7.84781432 3.97199296 3.81147774 3.0416103 0.32106351 -0.39263421 0.12251613 -0.24157768]
Seperti yang sudah disampaikan di awal, regularisasi L2 atau Ridge dapat membuat koefisien regresi semakin mendekati 0. Namun, koefisien regresi dengan ridge tidak akan pernah tepat bernilai 0 (kecuali dengan lambda tak hingga).
Model dengan nilai alpha=1 membuat koefisien dari X7, X8, X9 dan X10 berilai cukup kecil dibandingkan koefisien lainnya. Nilai RMSE model ini yaitu 10.0313, dan sangat dekat dengan hasil dari regresi linier biasa yang dihasilkan sebelumnya.
Tuning Hyperparameter
Pada model Ridge sebelumnya, kita menentukan nilai alpha sebesar 1. Nilai alpha yang optimal dapat kita cari melalui tuning hyperparameter menggunakan validasi silang (cross validation). Pada skelarn, fungsi yang digunakan adalah RidgeCV.
Python
from sklearn.linear_model import RidgeCV
list_alpha = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 0.9, 0.99, 1, 2, 5, 10]
model_ridge_cv = RidgeCV(alphas=list_alpha, cv=10)
# Fitting model Ridge CV
model_ridge_cv.fit(X_train, y_train)
# Prediksi data testing
y_pred_ridge_cv = model_ridge_cv.predict(X_test)
# Menghitung RMSE pada data testing
rmse_ridge_cv = mean_squared_error(y_test, y_pred_ridge_cv)**0.5
# Nilai alpha pada model terbaik
print("alpha:", model_ridge_cv.alpha_)
print("RMSE (Testing):", rmse_ridge_cv)
print("Koefisien:")
print(model_ridge_cv.coef_)Output
# Output alpha: 2.0 RMSE (Testing): 10.031154540430938 Koefisien: [20.55153364 8.01263082 7.84701583 3.97148655 3.81104423 3.02054694 0.32135601 -0.30195216 0.12900281 -0.22073073]
Pertama, tentukan daftar nilai alpha yang akan dicobakan pada model:
Selanjutnya, dengan menggunakan fungsi RidgeCV kita buat model dengan parameter alphas berupa list_alpha yang sudah dibuat sebelumnya.
Parameter cv merupakan jumlah fold yang digunakan dalam proses validasi silang. Nilai yang umum adalah 5 atau 10 (default). Penentuan model terbaik di sini adalah berdasarkan hasil validasi silang pada data training.
Hasil validasi silang menunjukkan model Regresi Ridge terbaik diperoleh ketika nilai alpha=2. Adapun hasil evaluasi pada data testing diperoleh nilai RMSE 10,0311. Walaupun tidak terlalu jauh berbeda, nilai ini sedikit lebih baik dibandingkan model regresi linier biasa maupun pada model Ridge dengan alpha=1.
Referensi
- James, G., Witten, D., Hastie, T., Tibshirani, R. 2014, An Introduction to Statistical Learning with Applications in R, Springer.
- Dokumentasi Ridge (Scikit-Learn) : sklearn.linear_model.Ridge
- Dokumentasi RidgeCV (Scikit-Learn): sklearn.linear_model.RidgeCV







