Pemodelan Klasifikasi dengan Algoritma KNN (Prediksi Penderita Diabetes)

K-Nearest Neighbor (KNN) termasuk pemodelan supervised machine learning dan dapat digunakan untuk problem klasifikasi maupun regresi. KNN termasuk model sederhana dibandingkan model machine learning lainnya. Pada model KNN, prediksi nilai atau kelas data baru ditentukan dari kedekatan jarak data tersebut terhadap data-data di sekitarnya.
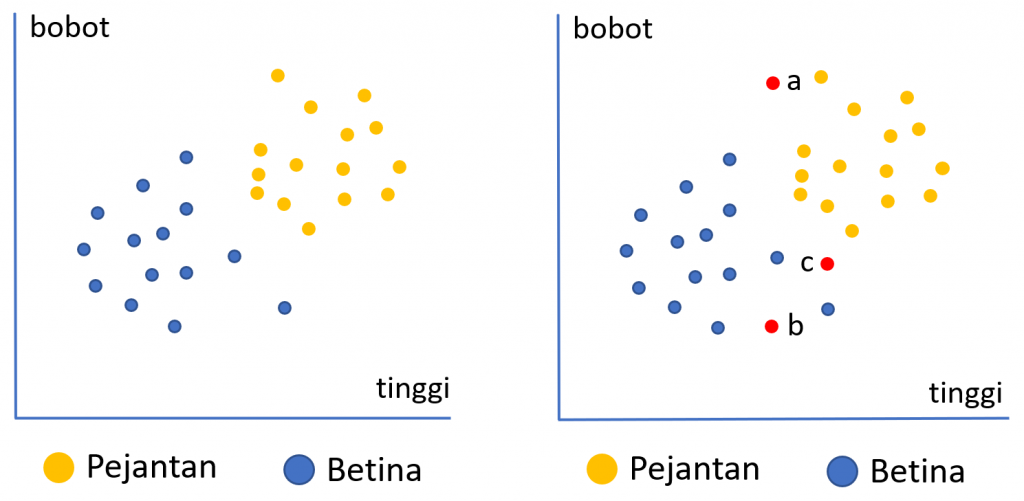
Ilustrasi di atas menunjukkan data historis perbandingan anak ayam pejantan dan betina menurut features tinggi dan bobot saat menetas. Menurut gambar (bagian kiri) anak ayam jantan cenderung memiliki tinggi dan bobot yang lebih besar dibanding betina. Sementara itu pada gambar bagian kanan terdapat 3 titik baru berwarna merah (a, b, c) yang belum diketahui labelnya. Dengan model KNN, prediksi jenis kelamin diukur berdasarkan kedekatan titik-titik tersebut dengan k tetangga terdekatnya.
Titik a, dengan nilai k=3, diperoleh 3 tetangga terdekat adalah jantan maka anak ayam a akan diprediksi sebagai pejantan. Begitu juga anak ayam b akan diprediksi sebagai betina. Anak ayam c, 2 dari 3 tetangga terdekatnya adalah jantan maka anak ayam c diprediksi sebagai pejantan.
Penentuan nilai k optimal sangat tergantung dengan konteks permasalahan dan data yang digunakan. Oleh karena itu terdapat proses tuning hyperparameter untuk mencari model terbaik.
Pada tulisan ini kita akan membuat model klasifikasi KNN untuk memprediksi seseorang memiliki penyakit diabetes atau tidak. Tutorial ini menggunakan dataset PIMA Indians Diabetes Database. Model KNN akan dibangun dengan python dan menggunakan library scikit-learn (sklearn)
Tahapan yang diperlukan untuk mendapatkan model KNN terbaik mencakup persiapan, preprocessing data, pembagian data latih dan data uji, pembuatan model serta tuning hyperparameter dan evaluasi model.
Penyiapan Data
Python
# manajemen dataframe
import pandas as pd
# operasi aritmetika
import numpy as np
# visualsiasi data
import seaborn as sns
# pembagian data training dan testing
from sklearn.model_selection import train_test_split
# Penanganan imbalance dengan teknik BorderLineSmote
from imblearn.over_sampling import BorderLineSMOTE
# pemodelan KNN
from sklearn.neighbors import NearestNeighbors
# Grid search CV untuk tuning hyperparameter
from sklearn.model_selection import GridSearchCV
# Mengukur performa model
from sklearn.metrics import confusion_matrix, accuracy_score, balanced_accuracy
# memuat dataset
diabetes = pd.read_csv('diabetes.csv')
print(diabetes.info())Output
# Output <class 'pandas.core.frame.DataFrame'> RangeIndex: 768 entries, 0 to 767 Data columns (total 9 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Pregnancies 768 non-null int64 1 Glucose 768 non-null int64 2 BloodPressure 768 non-null int64 3 SkinThickness 768 non-null int64 4 Insulin 768 non-null int64 5 BMI 768 non-null float64 6 DiabetesPedigreeFunction 768 non-null float64 7 Age 768 non-null int64 8 Outcome 768 non-null int64 dtypes: float64(2), int64(7) memory usage: 54.1 KB
Dataset diabetes terdirid dari 768 amatan dan 8 kolom. Tidak terdapat missing value pada dataset, namun tetap perlu dicek lebih jauh validitas data. Kolom Outcome merupakan variabel target dengan nilai 0 (non diabetes) dan 1 (diabetes). Kolom 1 sampai 7 bertipe numerik sebagai features atau variabel penjelas.
Pemeriksaan dan Penanganan Data
np.round(diabetes.iloc[:,:8].describe(), 2)
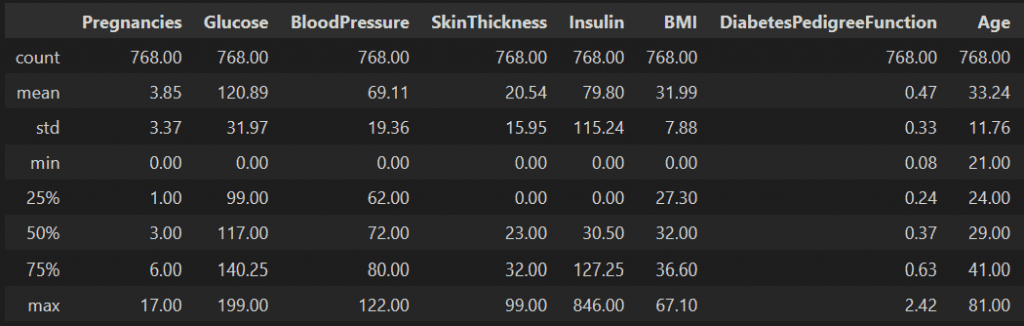
Terdapat beberapa data yang mungkin bermasalah. Contohnya kolom Glucose, BloodPressure dan 3 kolom lainnya memiliki nilai minimum 0. Angka tersebut pasti merupakan kekeliruan, karena kadar gula atau tekanan darah tidak mungkin bernilai 0. Selanjutnya pada masing-masing kolom akan dilakukan pengecekan sebelum masuk pemodelan KNN.
Pregnancies
Kolom Pregnancies menunjukkan banyaknya kehamilan yang pernah dialami oleh subjek amatan.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 3))
sns.histplot(data = diabetes["Pregnancies"], kde=True, ax=axes[0])
sns.boxplot(x=diabetes["Pregnancies"], width=0.5, ax=axes[1])
fig.tight_layout()
sns.boxplot(data=diabetes, x="Outcome", y="Pregnancies", width=0.5)
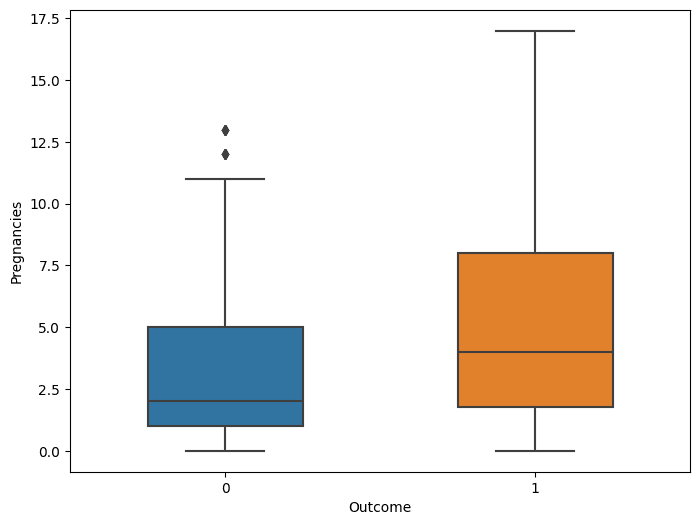
Sebaran nilai Pregnancies cenderung menjulur jauh ke kanan. Terdapat beberapa data outlier namun secara umum masih dalam batas yang wajar. Apalagi jika melihat boxplot antara Pregnancies dan Outcome sebaran data relatif baik. Oleh karena itu Kolom Pregnancies tidak perlu penanganan.
Glucose
Kolom Glucose menunjukkan nilai tekanan darah dan tidak mungkin bernilai 0.
diabetes["Glucose"][diabetes["Glucose"]==0].count() # Ouutput # 5
Terdapat 5 amatan dengan nilai glucose 0. Untuk penanganannya kita akan melihat penyebaran data lainnya (yang bukan 0). Jika sebarannya cenderung simetris maka dapat menggunakan nilai rataan, namun jika menjulur cukup jauh pilihan yang lebih baik yaitu menggunakan median.
Pendekatan yang lebih baik dapat menggunakan rata-rata atau median per kelompok Outcome. Nilai Glucose 0 pada kelas dengan Outcome 0 (tidak diabetes) diperbaiki menggunakan rata-rata nilai Glucose pada kelas 0. Begitu pula untuk nilai Glucose 0 pada kelas dengan Outcome 1 (diabetes) diperbaiki dengan rata-rata nilai Glucose pada kelas 1. Namun dalam pembahasan ini kita cukup menggunakan nilai rata-rata Glucose secara total.
non_zero_glucose = diabetes["Glucose"][diabetes["Glucose"]!=0]
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 3))
sns.histplot(x = non_zero_glucose, kde=True, ax=axes[0])
sns.boxplot(x = non_zero_glucose, width=0.5, ax=axes[1])
fig.tight_layout()
Distribusi data Glucose relatif simetris serta tidak terdapat outlier, maka penanganan untuk imputasi data bernilai 0 akan menggunakan rataan.
glucose_mean = non_zero_glucose.mean() diabetes['Glucose'] = diabetes['Glucose'].replace(0, glucose_mean)
BloodPressure
Kolom BloodPressure berisi informasi nilai tekanan darah dan tidak mungkin bernilai 0 sehingga terdapat total 35 amatan yang perlu ditangani.
diabetes["BloodPressure"][diabetes["BloodPressure"]==0].count() # Output # 35
non_zero_bloodpress = diabetes["BloodPressure"][diabetes["BloodPressure"]!=0]
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 3))
sns.histplot(x = non_zero_bloodpress, kde=True, ax=axes[0])
sns.boxplot(x = non_zero_bloodpress, width=0.5, ax=axes[1])
fig.tight_layout()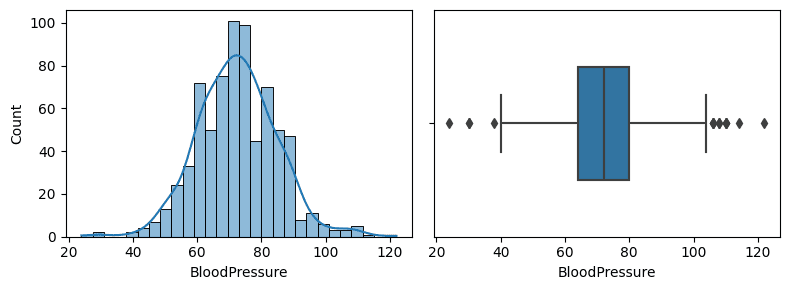
Kolom BloodPressure memiliki bentuk sebaran simetris, maka kita akan gunakan nilai rataan untuk imputasi data bernilai 0.
Dari boxplot terdapat beberapa titik outlier pada kedua sisi. Namun nilai tersebut masih memungkinkan untuk ukuran tekanan darah sehingga akan kita biarkan apa adanya.
bloodpress_mean = non_zero_bloodpress.mean() # mengganti nilai 0 dengan nilai rata-rata bloodpressure diabetes['BloodPressure'] = diabetes['BloodPressure'].replace(0, bloodpress_mean)
SkinThickness
Kolom SkinThickness berisi ukuran ketebalan lipatan kulit trisep (mm) dimana nilainya juga tidak mungkin 0. Kondisi kolom ini cukup parah karena terdapat 227 amatan dengan nilai 0. Oleh karena itu kolom ini tidak digunakan dalam pembentukan model.
diabetes["SkinThickness"][diabetes["SkinThickness"]==0].count() # Output # 227
diabetes.drop(["Insulin"], axis=1, inplace=True)
Insulin
Sama seperti SkinThickness, kolom Insulin memiliki nilai 0 yang sangat banyak. Terdapat 374 amatan bernilai 0. Jumlah ini hampir separuh dari total 768 amatan. Kita juga menghapus kolom ini karena terlalu banyak data hilang.
diabetes["Insulin"][diabetes["Insulin"]==0].count() # Output # 374
diabetes.drop(["SkinThickness"], axis=1, inplace=True)
BMI
Kolom BMI berisi informasi indeks masa tubuh dan tidak mungkin bernilai 0. Pada kolom ini terdapat 11 data bernilai 0. Untuk penanganannya menggunakan nilai rataan karena sebaran data relatif simetris.
diabetes["BMI"][diabetes["BMI"]==0].count() # Output # 11
non_zero_bmi = diabetes["BMI"][diabetes["BMI"]!=0]
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 3))
sns.histplot(x = non_zero_bmi, kde=True, ax=axes[0])
sns.boxplot(x = non_zero_bmi, width=0.5, ax=axes[1])
fig.tight_layout()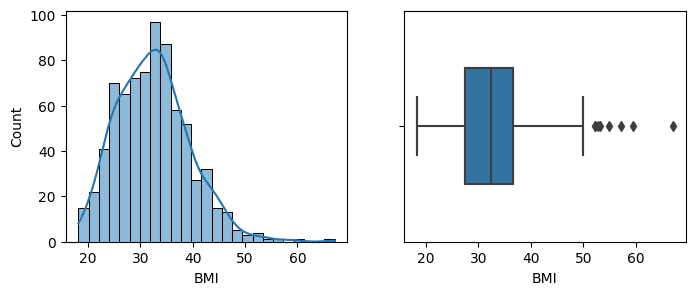
bmi_mean = non_zero_bmi.mean() # mengganti nilai 0 dengan nilai rata-rata bmi diabetes['BMI'] = diabetes['BMI'].replace(0, bmi_mean)
DiabetesPedigreeFunction
Kolom DiabetesPedigreeFunction tidak terdapat nilai 0 dimana nilai minimum adalah 0,8 dan maksimum 2,4. Adapun sebaran datanya menjulur ke kanan dengan beberapa amatan outlier namun masih pada nilai yang memungkinan.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 3))
sns.histplot(x = diabetes["DiabetesPedigreeFunction"], kde=True, ax=axes[0])
sns.boxplot(x=diabetes["Outcome"], y = diabetes["DiabetesPedigreeFunction"], width=0.5, ax=axes[1])
fig.tight_layout()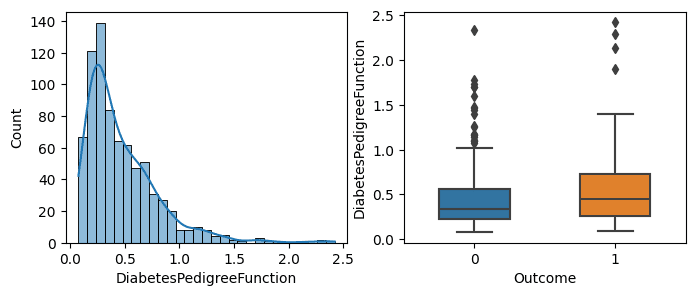
Age
Nilai pada kolom Age berkisar antara 21 hingga 81 tahun, sehingga tidak terdapat data bernilai 0 dan tidak perlu penanganan apapun.
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(8, 3)) sns.histplot(x = diabetes["Age"], kde=True, ax=axes[0]) sns.boxplot(x=diabetes["Outcome"], y = diabetes["Age"], width=0.5, ax=axes[1])
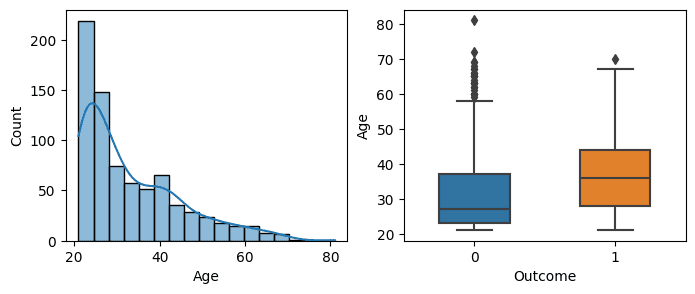
Pembagian Data Training dan Testing
Pembagian data traning dan data testing sangat penting dalam pemodelan machine learning. Data training digunakan sebagai dasar pembentukan model KNN. Data testing digunakan untuk mengevaluasi model. Penggunaan data testing penting agar model dapat diuji dengan data yang belum pernah dilihat saat proses training model. Penggunakan data yang sama untuk mengevaluasi mengakibatkan kecenderungan model menjadi overfitting. Model tidak dapat dievaluasi secara fair karena data pengujian sama dengan data untuk pembetukan model.
Pembagian data training dan testing dapat menggunakan fungsi train_test_split dari library sklearn.model_selection. Kita akan menggunakan proporsi 80 persen untuk training dan 20 persen testing. Pemilihan dilakukan secara acak dan proporsional (stratified random sampling), sehingga kedua jenis Outcome (0 dan 1) memiliki keterwakilan yang sama pada data training maupun testing.
from sklearn.model_selection import train_test_split
X = diabetes.drop('Outcome', axis=1)
y = diabetes['Outcome']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=50)## Komposisi Data latih ##
train_diab = np.count_nonzero(y_train == 1)
train_non_diab = np.count_nonzero(y_train == 0)
train_prop_diab = np.round(train_diab/(train_diab+train_non_diab), decimals=3)
print('============================')
print('Train Diabetes = ', train_diab)
print('Train Non-Diabetes = ', train_non_diab)
print("Train Proporsi : ", train_prop_diab)
## Komposisi Data uji ##
test_diab = np.count_nonzero(y_test == 1)
test_non_diab = np.count_nonzero(y_test == 0)
test_prop_diab = np.round(test_diab/(test_diab+test_non_diab), decimals=3)
print('============================')
print('Test Diabetes = ', test_diab)
print('Test Non-Diabetes = ', test_non_diab)
print("Test Proporsi : ", test_prop_diab)
print('============================')
# Output ============================ Train Diabetes = 214 Train Non-Diabetes = 400 Train Proporsi : 0.349 ============================ Test Diabetes = 54 Test Non-Diabetes = 100 Train Proporsi : 0.351 ============================
Dari Total 768 amatan, 614 data menjadi data training dan 154 menjadi data testing. Pada data training, 214 data memiliki label 1 (diabetes) dan 400 label 0 (Tidak diabetes). Proporsi label 1 adalah 35% dan label 0 sebesar 65%. Begitu pula untuk data testing memiliki proporsi yang serupa.
Penanganan Data Tidak Seimbang
Proporsi data dapat dikatakan tidak seimbang dimana jumlah data dengan label 0 hampir 2 kali lipat dari data label 1. Penanganan data diperlukan karena kondisi tersebut (dalam contoh ini sebenarnya tidak terlalu besar, namun akan tetap kita lakukan proses balancing data). Beberapa teknik yang dapat digunakan yaitu random under sampling, random over sampling, SMOTE, Adasyn over sampling dan sebagainya. Proses ini dilakukan hanya pada data training saja.
Kita akan menggunakan teknik border line SMOTE yang tersedia melalui fungsi BorderLineSMOTE dari modul imblearn.over_sampling. Parameter sampling_strategy bertujuan untuk menentukan berapa proporsi kelas minoritas terhadap kelas mayoritas setelah proses over sampling. Nilai default parameter sampling_strategy=1, artinya kelas minoritas akan dilakukan over sampling sehingga jumlah data sama persis dengan kelas mayoritas.
Di sini, agar tidak terlalu banyak menggunakan data sintetik, kita akan menggunakan nilai sampling_strategy=0.7.
# random over sampling dilakukan pada data training
bos = BorderlineSMOTE(random_state=10, sampling_strategy=0.7)
X_train, y_train = bos.fit_resample(X_train, y_train)
# cek jumlah data training
print("Train diabetes", np.count_nonzero(y_train == 1))
print("Train non-diabetes", np.count_nonzero(y_train == 0))
# Output
# Train diabetes 280
# Train non-diabetes 400Jumlah data traning setelah dilakukan over sampling menggunakan border line SMOTE adalah 680 dengan proporsi 59% kelas 0 dan 41% kelas 1.
Feature Scaling
Feature scaling adalah proses mengubah skala data pada sebuah feature. Contoh dari feature scaling adalah standardisasi dan normalisasi. Standardisasi merubah skala data dimana data baru memiliki nilai rata-rata 0 dan standar deviasi 1. Normalisasi merubah skala data sehingga memiliki nilai antara 0 sampai 1.
Pada tutorial ini kita akan menggunakan standardisasi dengan fungsi StandarScaler dari modul sklearn.preprocessing.
scaler = StandardScaler() # Standardisasi features data training dan testing scaled_X_train = scaler.fit_transform(X_train) scaled_X_test = scaler.fit_transform(X_test)
Pemodelan KNN
Model Awal
Pada sklearn, pembuatan model klasifikasi KNN adalah menggunakan fungsi KNeighborsClassifier. Parameter utama yang perlu ditentukan adalah n_neighbors. Parameter ini merupakan banyaknya tetangga terdekat yang digunakan untuk prediksi.
Model KNN yang kita buat berikut ini menggunakan nilai n_neighbors=3. Untuk parameter lainnya tetap dengan nilai default-nya.
model_knn = KNeighborsClassifier(n_neighbors=3) model_knn.fit(scaled_X_train, y_train)
Berdasarkan model KNN tersebut, kita lanjutkan dengan memprediksi output dari daja uji.
y_pred = model_knn.predict(scaled_X_test) y_pred
# Output
array([0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 0,
0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 0, 1,
0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0, 1,
0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 1,
1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0])Evaluasi Model Awal
Hasil prediksi model KNN pada data uji dapat kita bandingkan dengan nilai sebenarnya. Perbandingan ini untuk melihat seberapa baik model dalam memprediksi. Kita akan menggunakan metrik balanced accuracy karena metrik ini cocok pada kondisi data yang tidak seimbang. Namun sebagai perbandingan kita juga akan menampilkan metrik accuracy.
print(confusion_matrix(y_test, y_pred))
print("Accuracy :", accuracy_score(y_test, y_pred))
print("balanced Accuracy :", balanced_accuracy_score(y_test, y_pred))
# Output [[80 20] [20 34]] Accuracy : 0.7402597402597403 balanced Accuracy : 0.7148148148148148
Berdasarkan confussion matriks, model berhasil memprediksi benar 80 dari 100 data dengan label 0 (tidak diabetes), sementara 20 sisanya salah. Pada data uji dengan label 1 (diabetes), 34 dari 54 diprediksi tepat dan 20 lainnya salah.
Skor accuracy yang diperoleh adalah sebesar 74,03%. Jika melihat performa model untuk masing-masing kelas ternyata terdapat perbedaan yang besar. Model mampu memprediksi benar pada kelas 0 hingga 80/(80+20) = 80% sedangkan untuk kelas 1 hanya 34/(20+34)=63%.
Dari 100 orang yang benar-benar menderita diabetes, kita hanya mampu memprediksi secara tepat 63% saja, 37% sisanya dianggap tidak memiliki penyakit diabetes. Dalam konteks penyakit, tentu diharapkan mampu memprediksi sebaik mungkin orang-orang yang memang memiliki penyakit.
Adapun balanced accuracy yang diperoleh adalah 71,48%. Skor ini lebih kecil dibandingkan skor accuracy. Namun mengingat performa model dalam memprediksi kelas 1 (diabetes), nilai ini menjadi lebih relevan.
Tuning Hyperparameter
Pada bagian sebelumnya kita sudah membuat model KNN dengan parameter n_neighbors=3. Dari begitu banyak nilai yang dapat dipilih sangat mungkin ada model yang lebih baik. Oleh karena itu perlu dilakukan tuning hyperparameter, Satu teknik yang dapat digunakan adalah Grid Search Cross Validation. Fungsi GridSearchCV pada modul sklearn.model_selection dapat digunakan untuk mencari model terbaik berdasarkan kombinasi parameter.
param_grid = {
'n_neighbors': np.arange(1, 30, 1),
'weights' : ['uniform', 'distance']
}
model_knn = KNeighborsClassifier()
model_knn_cv = GridSearchCV(model_knn,
param_grid=param_grid,
scoring="balanced_accuracy" , cv=5, refit=True,
n_jobs=4)
model_knn_cv.fit(scaled_X_train, y_train)
Pertama tentukan nilai-nilai parameter model KNN yang akan dibandingkan. Pada kode di atas kita menyiapkan sebanyak 29 nilai n_neighbors dari 1, 2, 3 hingga 29.
Parameter berikutnya yaitu weights dengan 2 nilai ("uniform" dan "distance"). Parameter ini mengatur pembobotan jarak tetangga yang digunakan. Misalkan model dengan n_neighbors=5, maka nilai "uniform" artinya 5 tetangga tersebut memiliki bobot yang sama. Adapun nilai "distance" memberikan bobot lebih besar untuk tetangga yang lebih dekat di antara 5 tetangga tersebut.
Terdapat parameter lain yang dapat diatur jika diinginkan, namun di sini kita menentukan 2 parameter saja.
Dengan 29 nilai n_neighbors dan 2 nilai weights, jika dikombinasikan akan menghasilkan 58 model KNN. Fungsi GridSearchCV akan mencari model terbaik berdasarkan kombinasi parameter tersebut. Untuk kriteria model terbaik kita atur menggunakan scoring="balanced_accuracy". Model dengan nilai balanced accuracy tertinggi (hasil cross validation pada data training) akan dipilih menjadi model terbaik.
Parameter cv pada fungsi GridSearchCV adalah jumlah fold yang digunakan untuk proses validasi silang. Nilai yang lazim digunakan adalah 5 atau 10.
Parameter n_jobs untuk menentukan banyaknya proses parallel yang digunakan untuk komputasi. Nilai n_jobs=-1 menunjukkan proses akan menggunakan semua core pada CPU dalam proses komputasi pembentukan model. Sementara itu nilai n_jobs=4 menunjukkan jumlah proses paralel sebanyak 4 proses sekaligus.
print("Best Param:", model_knn_cv.best_params_)
print("best Score:", model_knn_cv.best_score_)# Output
Best Param: {'n_neighbors': 16, 'weights': 'distance'}
best Score: 0.7648214285714285Model KNN terbaik menurut hasil GridSearchCV adalah dengan parameter n_neighbors=16 dan weights='distance'. Skor balanced accuracy dari model terbaik adalah 76,48%. Perlu diingat angka ini adalah nilai terbaik hasil validasi silang dengan data training. Model perlu dievaluasi kembali menggunakan data testing.
y_pred = model_knn_cv.predict(scaled_X_test) y_pred
# Output
array([0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 0,
0, 1, 0, 0, 1, 0, 1, 1, 1, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0,
0, 0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 0, 0,
1, 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 1, 0, 1, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1,
1, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 1, 0, 0, 1, 0, 0, 0])Evaluasi Model Terbaik
Evaluasi model KNN terbaik pada data uji menunjukkan skor balanced accuracy 78,11%. Angka ini jauh lebih tinggi dibandingkan model awal tanpa GridSearchCV. Begitu pula skor accuracy model mencapai skor 79,87% lebih tinggi dibandingkan model awal.
Performa model dalam memprediksi kelas 0 (non diabetes) adalah 84/(84+16) = 84% dan kelas 1 (diabetes) sebesar 39/(15+39) = 72%. Masih terdapat berbedaan antara dua nilai ini, namun model KNN terbaik mampu memprediksi kelas 1 (diabetes) jauh lebih baik dibandingkan model sebelumnya yaitu 63%.
print(confusion_matrix(y_test, y_pred))
print("Accuracy :", accuracy_score(y_test, y_pred))
print("Balanced Accuracy :", balanced_accuracy_score(y_test, y_pred), "\n")
print(classification_report(y_test, y_pred))# Output [[84 16] [15 39]] Accuracy : 0.7987012987012987 Balanced Accuracy : 0.7811111111111111
Performa model tentunya dapat bervariasi tergantung bagaimana penanganan data, penentuan data training dan testing, penanganan data tidak seimbang termasuk juga penentuan nilai random_state. Namun secara umum, dengan tahapan yang sama tentunya performa model seharusnya tidak akan jauh berbeda.
Ringkasan
Pada tutorial ini, kita sudah membuat model KNN untuk memprediksi penderita diabetes. Tahapan dalam pembentukan model meliputi persiapan dan penanganan data, pembagian data training dan testing, penanganan data tidak seimbang hingga proses tuning hyperparameter menggunakan GridSearchCV. Model juga dievaluasi pada data testing dengan mengukur metrik accuracy dan balanced accuracy.







