Deteksi Objek pada Video dengan YOLOv11

YOLO (You Only Look Once) adalah salah satu model deep learning paling populer untuk mendeteksi objek dalam gambar atau video secara real-time. Dengan model ini, kita bisa membuat aplikasi untuk mengenali berbagai objek seperti orang, kendaraan, hewan, dan benda lainnya dengan efisien. Tidak hanya untuk deteksi objek, YOLO juga dapat digunakan untuk segmentasi, pelacakan objek, dan klasifikasi gambar. Terdapat berbagai versi YOLO yang dapat digunakan. Saat ini versi terbaru yang tersedia yaitu YOLOv11.
Sekilas YOLOv11
YOLOv11 adalah generasi lanjutan dari model deteksi objek Ultralytics yang dirancang ulang dengan fokus pada kesederhanaan, fleksibilitas, dan efisiensi. Model ini menggunakan arsitektur decoupled head yang memungkinkan peningkatan kinerja pada berbagai tugas seperti deteksi objek pada gambar dan video, segmentasi, dan pelacakan. Model YOLOv11 juga didukung oleh training pipeline yang lebih cepat serta hasil prediksi yang lebih stabil.
Berikut beberapa keunggulan dari YOLOv11:
- Ekstraksi Fitur yang Lebih Baik: YOLOv11 menggunakan arsitektur backbone dan neck yang ditingkatkan untuk menghasilkan fitur yang lebih kaya, sehingga deteksi objek menjadi lebih akurat dan mampu menangani tugas yang lebih kompleks.
- Optimal untuk Efisiensi dan Kecepatan: Desain arsitektur yang lebih ringkas dan pipeline pelatihan yang dioptimalkan memungkinkan YOLOv11 untuk memproses data lebih cepat tanpa mengorbankan presisi.
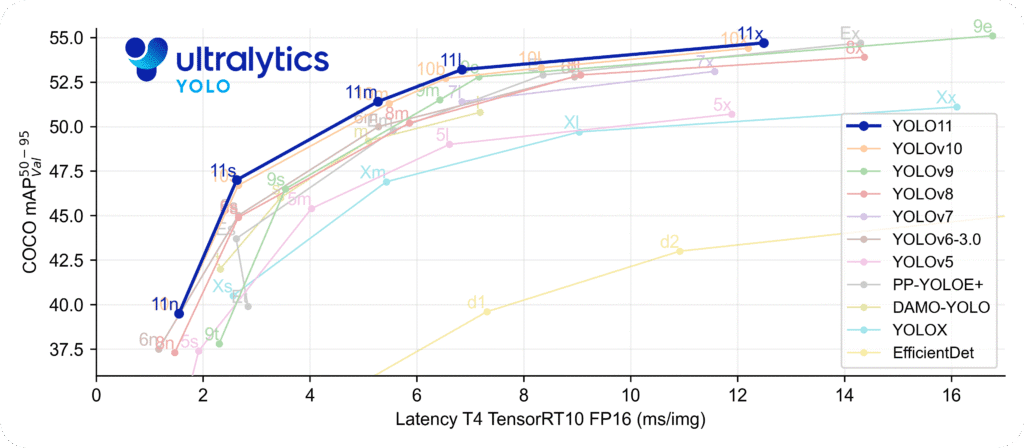
- Akurasi Lebih Tinggi dengan Parameter Lebih Sedikit: YOLOv11m mencapai nilai mAP yang lebih tinggi pada dataset COCO dengan jumlah parameter 22% lebih sedikit dibanding YOLOv8m, menjadikannya efisien secara komputasi.
- Adaptif untuk Berbagai Lingkungan: Model dapat dijalankan secara fleksibel baik di edge devices, platform cloud, maupun sistem dengan dukungan GPU NVIDIA.
- Mendukung Banyak Jenis Tugas: YOLOv11 dirancang untuk menangani berbagai tantangan computer vision seperti deteksi objek, segmentasi instance, klasifikasi gambar, estimasi pose, dan deteksi objek berorientasi (OBB).
Berikut adalah perbandingan YOLOv11 dengan versi-versi sebelumnya serta beberapa model lain:
Penyiapan Lingkungan Kerja
Sebelum memulai, instal terlebih dahulu beberapa dependensi penting berikut ini:
Python
pip install ultralytics opencv-python torch
Berikut penjelasan fungsi masing-masing paket:
ultralytics: Library resmi dari Ultralytics yang menyediakan antarmuka Python untuk menjalankan model YOLO (termasuk versi terbaru seperti YOLOv11). Library ini memungkinkan kita untuk memuat model, melakukan inferensi, dan mengakses hasil prediksi dengan mudah.opencv-python: Digunakan untuk membaca, menampilkan, dan menulis video serta gambar. Library ini juga digunakan untuk menggambar bounding box dan label hasil deteksi ke dalam frame.torch: Merupakan library utama dari PyTorch yang digunakan sebagai framework deep learning untuk menjalankan model YOLO. Torch juga digunakan untuk mendeteksi apakah perangkat GPU tersedia atau tidak agar proses inferensi dapat berjalan lebih cepat.
Sebagai catatan, pastikan versi yang digunakan adalah Python 3.8 atau lebih baru. dan telah menginstal PyTorch dengan CUDA jika ingin menggunakan GPU.
Deteksi Objek dengan YOLOv11
Berikut ini adalah kode lengkap untuk deteksi berbagai objek menggunakan model YOLOv11. Untuk penjelasan lebih detail setiap blok kode dapat dilihat pada bagian selanjutnya.
Kode dapat juga diakses pada Github Repository berikut: sainsdataid/object-detection-yolov11
Python
# 1. Memuat library yang diperlukan
from ultralytics import YOLO
import torch
import cv2
import numpy as np
# 2. Pilih perangkat: GPU jika tersedia, jika tidak gunakan CPU
device = "cuda" if torch.cuda.is_available() else "cpu"
# 3. Memuat model YOLOv11 dan pindahkan ke device yang sesuai (GPU atau CPU)
model = YOLO("yolo11m.pt")
model.to(device)
# 4. Daftar kelas yang ingin difokuskan (berdasarkan COCO)
focused_classes = ["person", "bicycle", "car", "motorbike", "bus", "truck"]
# 5. Menentukan video yang digunakan
video_path = "free_video_george_morina.mp4"
cap = cv2.VideoCapture(video_path) # untuk video dari file (misal mp4)
# cap = cv2.VideoCapture(0) # untuk video langsung dari Webcam
# 6. Mengambil informasi properti video
# Untuk keperluan menyimpan video output, hanya jika diinginkan
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
fps = cap.get(cv2.CAP_PROP_FPS)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
output_path = "output_video.mp4"
out = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
# 7. Pemrosesan video per frame
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
# Lakukan proses deteksi objek
results = model(frame)
# Iterasi tiap hasil deteksi
for result in results:
boxes = result.boxes
names = model.names
# Hitung jumlah objek per label
label_counts = {label: 0 for label in focused_classes}
for box in boxes:
x1, y1, x2, y2 = np.asarray(box.xyxy[0]).astype(int)
cls_id = int(box.cls[0])
confidence = float(box.conf[0])
label = names[cls_id]
if confidence > 0.3 and label in focused_classes:
label_counts[label] += 1
# Gambar bounding box dan label
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
cv2.putText(
frame,
f"{label} {confidence*100:.0f}%",
(x1, y1 - 10),
cv2.FONT_HERSHEY_PLAIN,
1.0,
(0, 255, 0),
2,
)
# Tampilkan teks ringkasan jumlah objek di pojok kiri atas
summary = ", ".join([f"{v} {k}" for k, v in label_counts.items() if v > 0])
box_padding = 12
(text_width, text_height), _ = cv2.getTextSize(summary, cv2.FONT_HERSHEY_SIMPLEX, 0.6, 2)
cv2.rectangle(frame, (5, 5), (5 + text_width + box_padding, 5 + text_height + box_padding), (0, 255, 0), -1)
cv2.putText(frame, summary, (10, 25), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 0), 2, cv2.LINE_AA
)
# Simpan frame ke output (jika diperlukan -> Poin 6)
out.write(frame)
# Tampilkan frame dengan deteksi objek
cv2.imshow("YOLOv11 Object Detection", frame)
# jika diinginkan ukuran layar video dapat diubah
# resized_frame = cv2.resize(frame, (960, 540))
# cv2.imshow("YOLOv11 Object Detection", resized_frame)
# Tekan 'q' untuk keluar
if cv2.waitKey(1) & 0xFF == ord("q"):
break
# 8. Bersihkan sumber daya
cap.release()
out.release()
cv2.destroyAllWindows()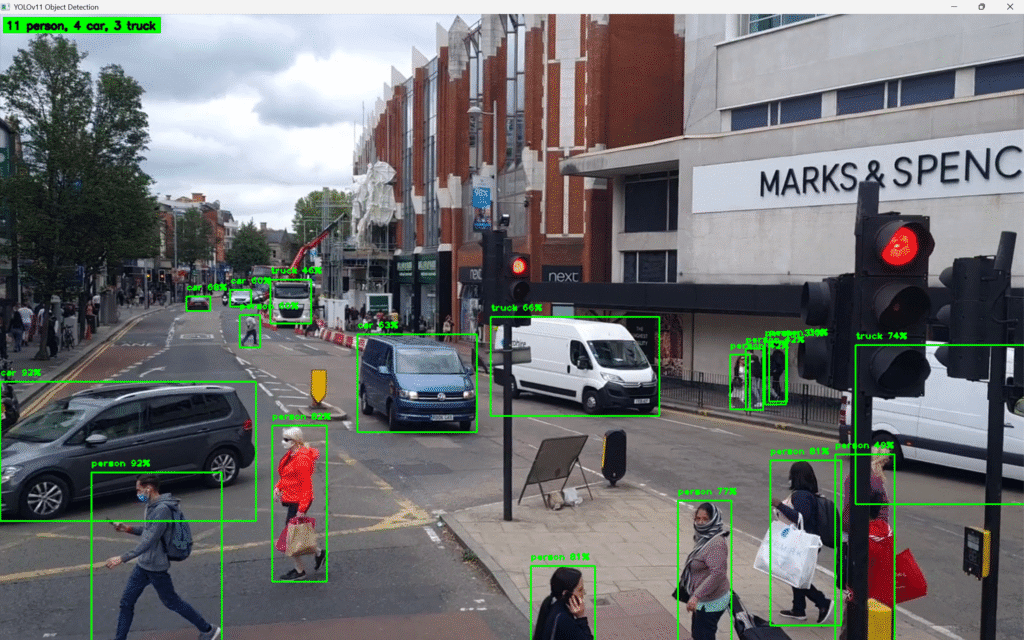
Penjelasan Singkat
1. Memuat Library yang Diperlukan
Mengimpor modul ultralytics, torch, cv2, dan numpy untuk menjalankan model, memilih perangkat, manipulasi gambar/video, serta operasi array numerik.
2. Memilih Perangkat
Pada bagian ini, kita mengecek apakah tersedia GPU atau tidak. Jika tersedia maka proses akan dilakukan di GPU, jika tidak, terpaksa hanya mengandalkan CPU saja. Idealnya proses pemodelan dan rendering video ini membutuhkan GPU dedicated agar berjalan lancar. Namun, tidak setiap perangkat terpasang GPU dedicated tersebut. Jika kode hanya dijalankan dengan CPU saja maka kemungkinan besar akan terjadi lag atau video tidak dapat berjalan mulus.
3. Memuat model
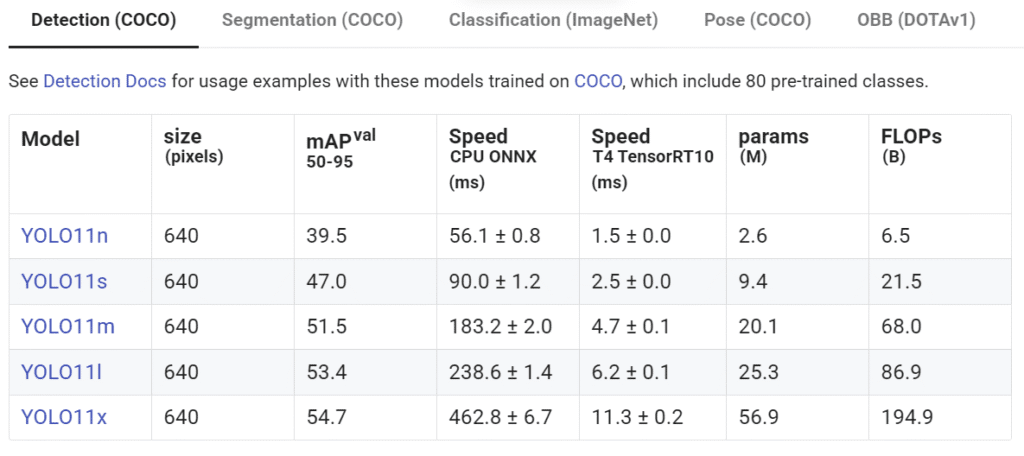
Model YOLO tersedia dalam berbagai ukuran, seperti yolo11n.pt (nano), yolo11s.pt (small), yolo11m.pt (medium), yolo11l.pt (large), dan yolo11x.pt (extra large). Pemilihan model tergantung pada kebutuhan kecepatan dan akurasi. Versi kecil cocok untuk perangkat terbatas, sedangkan versi besar cocok untuk akurasi tinggi di perangkat bertenaga.
Pada bagian YOLO("yolo11m.pt"), model otomatis diunduh dan dimuat jika terkoneksi internet. Model yang sudah diunduh akan tersimpan secara lokal. Sehingga proses unduh hanya satu kali saja ketika model belum tersedia. Selain itu, model juga dapat diunduh manual dari situs resmi Ultralytics dan disimpan secara lokal untuk digunakan secara offline.
Secara detail untuk masing-masing model dapat dilihat serta diunduh pada link berikut: Model YOLOv11
4. Menentukan Fokus Kelas Objek
Model YOLO dilatih pada dataset COCO (Common Objects in Context) yang berisi 80 kelas objek umum. Beberapa diantaranya seperti orang, sepeda, mobil, motor, truk, kursi, hewan, alat makan, dan lainnya. Namun, dalam aplikasi ini kita hanya memfokuskan deteksi pada kelas-kelas penting terkait mobilitas dan lalu lintas, yaitu: person, bicycle, car, motorbike, bus, dan truck. Pemilihan ini dilakukan agar hasil deteksi lebih relevan dan tidak terganggu oleh objek lain yang tidak diperlukan.
Jika pembaca ingin membuat aplikasi untuk deteksi kelas objek lainnya tentu saja sangat dimungkinkan. Daftar lengkap 80 kelas COCO dapat dilihat pada tautan berikut: coco.yaml.
5. Menyiapkan Video
Bagian ini digunakan untuk menentukan sumber video yang akan diproses. Kita bisa menggunakan webcam dengan sintaks cv2.VideoCapture(0) untuk input secara real-time. Penggunaan webcam cocok untuk aplikasi langsung seperti pengawasan CCTV atau demo.
Jika tidak, kita juga dapat menggunakan file video lokal melalui sintaks seperti cv2.VideoCapture('free_video_george_morina.mp4'). Pada tutorial ini, kita juga akan menggunakan stock video gratis yang diambil dari George Morina – Photography
6. Mengambil Properti Video
Bagian ini digunakan untuk mendapatkan informasi seperti frame rate (FPS), lebar dan tinggi frame dari video yang sedang diproses. Informasi ini diperlukan untuk menyusun ulang video dengan benar saat ingin menyimpan hasilnya. Pembuatan objek cv2.VideoWriter adalah opsional dan hanya diperlukan jika kita ingin menyimpan hasil deteksi ke dalam sebuah file video. Misalnya untuk dokumentasi, keperluan analisis lebih lanjut, atau diunggah ke platform seperti YouTube. Format video yang digunakan (mp4v) juga dapat disesuaikan dengan kebutuhan dan kompatibilitas sistem.
7. Pemrosesan Video untuk Deteksi Objek
Bagian ini merupakan inti dari aplikasi. Setiap frame yang dibaca dari sumber video akan diproses oleh model YOLO untuk mendeteksi objek-objek yang termasuk dalam focused_classes. Setiap objek yang terdeteksi, selanjutnya ditandai dengan membuat bounding box, label kelas, dan tingkat kepercayaan (confidence score).
Tingkat confidence yaitu nilai probabilitas yang menunjukkan seberapa yakin model bahwa suatu objek yang terdeteksi memang termasuk dalam kelas tertentu. Misalnya, nilai 0.85 berarti model 85% yakin bahwa objek tersebut adalah mobil. Pada kode ini, kita membatasi objek yang dideteksi berdasarkan tingkat confidence yang diberikan model. Jika confidence di atas ambang batas (misalnya 0.3) dan label sesuai dengan kelas yang menjadi fokus kita, maka objek tersebut kita tandai. Sebaliknya, jika di bawah ambang batas, maka akan kita abaikan. Tentunya nilai ini dapat diatur sesuai keinginan pembaca.
Pada bagian pojok kiri atas, kita juga menampilkan informasi tambahan yaitu jumlah objek dari setiap kelas. Ringkasan ini bersifat dinamis dan akan berubah sesuai objek yang terdeteksi di setiap frame.
Baris kode out.write(frame) sifatnya adalah opsional. Kode ini hanya diperlukan jika kita ingin menyimpan outputnya ke dalam format video.
Ringkasan
YOLOv11 adalah versi YOLO terbaru yang menawarkan peningkatan signifikan dalam hal akurasi, efisiensi, dan fleksibilitas. Dengan arsitektur yang disempurnakan dan dukungan penuh terhadap berbagai skenario implementasi, YOLOv11 semakin powerful digunakan untuk berbagai tugas seperti deteksi objek, segmentasi, dan pelacakan. Pada tulisan ini dibahas bagaimana menggunakan YOLOv11 untuk deteksi objek dari video. Kita juga membahas fitur tambahan seperti pemfilteran label fokus, visualisasi bounding box, dan ringkasan jumlah objek secara real-time. Contoh sederhana tentunya dapat dikembangkan misalnya untuk pengawasan lalu lintas, pemantauan kerumunan, serta penggunaan lainnya di bidang keamanan dan analisis video.







