Tuning Hyperparameter Model XGBoost dengan Optuna

Tuning hyperparameter adalah proses mengoptimalkan parameter-parameter tertentu dalam model machine learning untuk meningkatkan performa model tersebut. Parameter ini tidak dipelajari dari data, namun ditentukan sebelum proses pelatihan model dimulai. Dalam praktiknya, memilih nilai hyperparameter yang tepat dapat sangat meningkatkan akurasi model dan efisiensi komputasi.
Optuna adalah framework open-source untuk otomatisasi tuning hyperparameter. Dengan menggunakan metode Bayesian optimization, Optuna menawarkan cara yang efisien dan mudah untuk menemukan set hyperparameter terbaik. Keunggulan utama Optuna adalah kemampuannya untuk mengelola proses tuning secara dinamis, yang memungkinkan pengguna untuk mengoptimalkan hyperparameter secara adaptif berdasarkan hasil eksperimen sebelumnya.
Selain Bayesian Optimization, Optuna juga mendukung Grid Search, Random Search, Pruning, Multi-objective Optimization, dan Hyperband untuk mempercepat proses tuning. Dengan kombinasi teknik-teknik ini, Optuna mampu mengoptimalkan hyperparameter model machine learning dengan efisien dan efektif.
Tutorial ini akan membahas bagaimana melakukan tuning hyperparameter menggunakan Optuna dengan studi kasus pada model XGBoost. Namun, prinsip dan metode yang digunakan dapat diaplikasikan pada model machine learning lainnya, termasuk model-model deep learning yang dibangun dengan TensorFlow dan PyTorch serta model dari pustaka Scikit-Learn, LightGBM, dan CatBoost.
Penyiapan Environment dan Dataset
Untuk menjalankan tutorial ini kita harus menyiapkan beberapa pustaka yaitu optuna, xgboost, scikit-learn dan pandas. Berikut cara instalasi pustaka-pustaka tersebut menggunakan pip:
pip install optuna xgboost scikit-learn pandas
Setelah semua pustaka tersedia, maka langkah berikutnya adalah memuatnya ke dalam lingkungan kerja yang digunakan
Kode di bawah ini digunakan untuk mempersiapkan data mulai dari membaca dataset, preprecossing data serta membagi data menjadi set pelatihan dan pengujian. Pada dataset terdapat kolom id yang hanya berisi urutan data saja dan tidak terkait dengan pemodelan sehingga dapat dihapus.
Selanjutnya, tentukan kolom-kolom fitur dan juga kolom peubah respon. Peubah respon berada pada kolom terakhir yaitu quality. Kolom tersebut berisi nilai LOW atau HIGH yang mengindikasikan kelas dari observasi tersebut. Adapun 11 kolom lainnya seluruhnya bertipe numerik dan akan digunakan untuk memprediksi kelas quality. Karena label kelas masih berupa teks maka perlu dirubah menjadi numerik, misal digunakan 0 untuk kelas LOW dan 1 untuk kelas HIGH.
Langkah berikutnya adalah membagi data untuk data latih dan data uji dengan fungsi train_test_split. Di sini kita menggunakan proporsi data latih sebanyak 70 persen dan data uji sebanyak 30 persen.
Python
import pandas as pd
from sklearn.model_selection import train_test_split
# Membaca dataset
data = pd.read_csv("https://raw.githubusercontent.com/sainsdataid/dataset/main/wine-quality-binary.csv")
# Menghapus kolom id (tidak digunakan untuk pemodelan)
data = data.drop(columns="id")
# Menentukan fitur dan target
X = data.drop('quality', axis=1)
y = data['quality'].apply(lambda q: 1 if q=="HIGH" else 0)
# Membagi data latih dan data uji
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# OUTPUT <class 'pandas.core.frame.DataFrame'> RangeIndex: 1143 entries, 0 to 1142 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fixed.acidity 1143 non-null float64 1 volatile.acidity 1143 non-null float64 2 citric.acid 1143 non-null float64 3 residual.sugar 1143 non-null float64 4 chlorides 1143 non-null float64 5 free.sulfur.dioxide 1143 non-null float64 6 total.sulfur.dioxide 1143 non-null float64 7 density 1143 non-null float64 8 pH 1143 non-null float64 9 sulphates 1143 non-null float64 10 alcohol 1143 non-null float64 11 quality 1143 non-null object dtypes: float64(11), object(1) memory usage: 107.3+ KB
Hyperparameter Model XGBoost
Hyperparameter adalah komponen penting yang mempengaruhi kinerja model XGBoost. Berikut adalah beberapa hyperparameter pada model XGBoost:
etaataulearning_rate: Mengontrol ukuran langkah saat memperbarui bobot. Nilai yang lebih rendah membuat proses pelatihan lebih lambat tetapi lebih stabil. Sebaliknnya, jika terlalu tinggi bisa menyebabkan model melewatkan pola penting dalam data.max_depth: Batasan maksimum pada kedalaman pohon. Semakin dalam pohon, semakin kompleks model, dan semakin tinggi risiko overfitting.n_estimators: Jumlah pohon yang akan dibangun dalam model boosting.subsample: Proporsi sampel data yang digunakan untuk melatih setiap pohon.colsample_bytree: Proporsi fitur yang digunakan untuk proses splitting node.min_child_weight: Bobot minimum dari daun pohon. Parameter ini mencegah terjadinya overfitting dengan mengatur batas minimum jumlah contoh yang diperlukan untuk membagi node.gamma: Ambang batas untuk membuat pembagian pada node akhir (leaf node). Semakin besar nilaigammadapat membuat model menjadi terlalu sederhana dan kehilangan kemampuan untuk menangkap kompleksitas data.
Selain tujuh parameter di atas, terdapat parameter lainnya yang juga dapat dikontrol untuk pelatihan model XGBoost. Selengkapnya dapat dilihat pada dokumentasi resminya di XGBoost Parameters — xgboost 2.1.0 documentation
Tuning Hyperparameter dengan Optuna
Dalam praktiknya, mungkin tidak semua hyperparameter model perlu dilakukan tuning. Kita dapat menerapkannya pada beberapa parameter saja, sementara parameter lainnya ditentukan secara langsung atau menggunakan nilai defaultnya. Pada contoh ini, kita akan memfokuskan tuning pada hyperparameter yang dijelaskan sebelumnya yaitu max_depth, learning_rate, n_estimators, subsample, colsample_bytree, min_child_weight, dan gamma. Silahkan jika anda ingin mengatur hyperparameter lainnya atau menguranginya.
Fungsi Objektif
Pada proses tuning, langkah pertama yang perlu dilakukan yaitu membuat fungsi objektif. Fungsi ini berisi daftar hyperparameter model serta batas-batas nilai pencarian. Untuk parameter bertipe integer seperti maksimal kedalaman pohon (max_depth) dan jumlah pohon (n_estimators) kita dapat menyiapkan nilai-nilai dengan fungsi suggest_int. Sementara untuk parameter dengan nilai desimal seperti learning_rate menggunakan fungsi suggest_float. Tidak hanya itu, jika terdapat parameter dalam bentuk kategorik (misalkan parameter optimizer pada model-model neural network) maka dapat disiapkan dengan fungsi suggest_categorical.
Masih di dalam fungsi objektif, kita lakukan inisiasi model XGBoost dengan parameter yang sudah ditentukan. Selanjutnya, untuk mengukur kinerja model, kita akan gunakan teknik validasi silang k-fold dengan 3 fold. Nilai balik dari fungsi objektif adalah skor rata-rata berdasarkan evaluasi tersebut. Secara default, metrik evaluasi yang digunakan pada problem klasifikasi adalah accuracy. Namun, tentu saja dapat menggunakan metrik lainnya seperti balanced_accuracy, average_precision, f1 dan sebagainya (lihat Metrics and Scoring).
Python
import xgboost as xgb
from sklearn.model_selection import cross_val_score
# Menentukan fungsi objektif
def objective(trial):
param = {
'max_depth': trial.suggest_int('max_depth', 3, 10),
'learning_rate': trial.suggest_float('learning_rate', 0.01, 0.1),
'n_estimators': trial.suggest_int('n_estimators', 100, 1000),
'subsample': trial.suggest_float('subsample', 0.5, 1.0),
'colsample_bytree': trial.suggest_float('colsample_bytree', 0.5, 1.0),
'min_child_weight': trial.suggest_int('min_child_weight', 1, 10),
'gamma': trial.suggest_float('gamma', 0, 5),
}
model = xgb.XGBClassifier(**param) # inisiasi model XGBoost
score = cross_val_score(model, X_train, y_train, cv=3).mean() # menghitung skor dengan validasi silang
return scorePencarian Hyperparameter
Berdasarkan fungsi objektif , selanjtunya kita dapat membuat objek untuk pencarian hyperparameter model dengan create_study. Parameter direction diatur menjadi maximize, sesuai dengan fungsi objektif yaitu mencari nilai akurasi yang berartti semakin tinggi nilai akurasi maka model semakin baik.
Setelah objek study dibuat, jalankan metode optimize. Pada contoh di bawah ini, pencarian dilakukan sebanyak 100 kali. Kita dapat mengatur n_jobs=-1 yang berarti proses komputasi akan menggunakan seluruh processor yang tersedia. Nilai ini dapat disesuaikan misalkan 1 artinya menggunakan 1 processor atau nilai lainnya sesuai perangkat yang digunakan.
Setelah proses pencarian selesai, nilai parameter terbaik dapat diakses pada properti best_params dari objek study.
catatan: hasil yang disajikan di sini dapat berbeda karena adanya beberapa proses yang melibatkan bilangan acak, baik pada saat pembentukan model di dalam fungsi objektif maupun saat proses pencarian hyperparameter.
Python
import optuna
# Membuat dan menjalankan proses optimasi sebanyak 100 percobaan
study = optuna.create_study(study_name="contoh_xgboost_study", direction='maximize')
study.optimize(objective, n_trials=100, show_progress_bar=True, n_jobs=-1)
# Mendapatkan nilai parameter terbaik
best_params = study.best_params
print(f"Best parameters: {best_params}")# OUTPUT
[I 2024-07-23 12:17:59,487] A new study created in memory with name: contoh_xgboost_study
...
Best parameters: {'max_depth': 10,
'learning_rate': 0.057624696536847514,
'n_estimators': 114,
'subsample': 0.9504903622288657,
'colsample_bytree': 0.7050414176580851,
'min_child_weight': 3,
'gamma': 0.13370663308043607}Optuna menyediakan alat visual untuk menampilkan parameter mana yang memiliki pengaruh besar untuk meningkatkan kinerja model selama proses pencarian. Pada contoh ini, parameter gamma merupakan parameter yang memiliki tingkat kepentingan paling besar diikuti dengan subsample dan min_child_weight.
Python
import optuna.visualization as vis display(vis.plot_param_importances(study)) display(vis.plot_optimization_history(study))
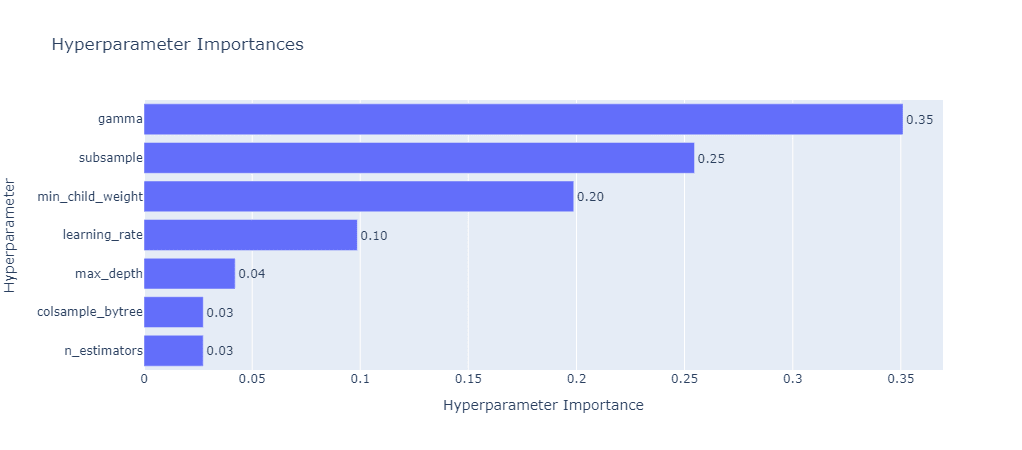
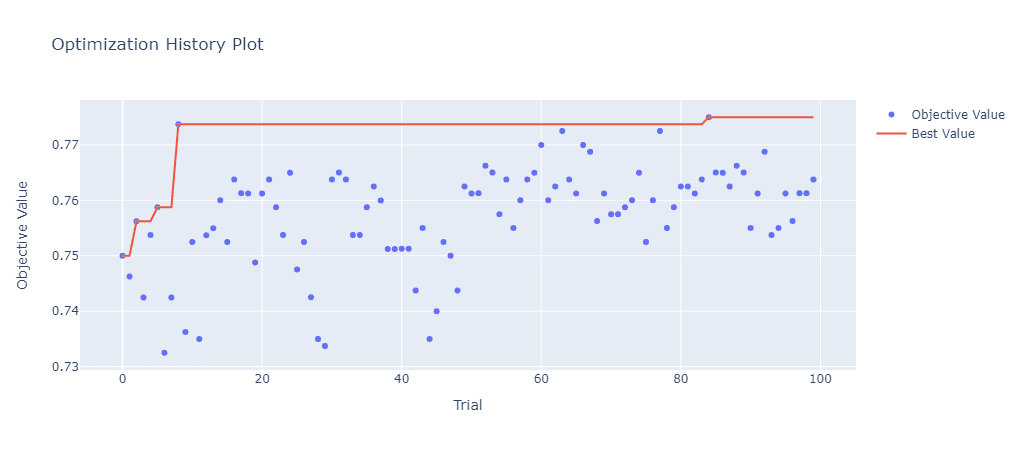
Pelatihan Model terbaik dan Evaluasi
Tahapan terakhir adalah melakukan pelatihan model dengan parameter terbaik yang ditemukan pada seluruh data latih. Model selanjutnya dapat digunakan untuk memprediksi data uji. Agar dapat digunakan kembali, kita juga dapat menyimpan model ke dalam file, misal dengan menggunakan fungsi dump dari pustaka joblib.
Python
from sklearn.metrics import accuracy_score, classification_report
# Melatih model dengan parameter terbaik
best_model = xgb.XGBClassifier(**best_params)
best_model.fit(X_train, y_train)
# Memprediksi data uji
y_pred = best_model.predict(X_test)
# Menghitung nilai akurasi
accuracy = accuracy_score(y_test, y_pred)
print(f"Akurasi: {accuracy}")
# Membuat classification report
cr = classification_report(y_test, y_pred)
print(f"\nReport:\n{cr}")# OUTPUT
Akurasi: 0.7696793002915452
Report:
precision recall f1-score support
0 0.73 0.77 0.75 152
1 0.81 0.77 0.79 191
accuracy 0.77 343
macro avg 0.77 0.77 0.77 343
weighted avg 0.77 0.77 0.77 343Selamat Mencoba!
API
- Optuna: API Reference — Optuna 3.6.1 documentation
- XGBoost Python API Reference — xgboost 2.1.0 documentation