Pemodelan Klasifikasi dengan CatBoost Python

CatBoost, atau Categorical Boosting, adalah implementasi algoritma machine learning berbasis pohon keputusan yang dikembangkan oleh Yandex. Pustaka ini dirancang khusus untuk menangani dataset dengan fitur kategorik tanpa memerlukan preprocessing yang rumit seperti one-hot encoding atau label encoding. Dengan begitu, CatBoost dapat bekerja lebih efisien dan akurat pada dataset yang mengandung banyak fitur kategorik.
Salah satu keunggulan utama CatBoost adalah kemampuannya untuk mengatasi overfitting. Hal ini dicapai melalui teknik gradient boosting yang telah dioptimalkan, sehingga dapat meningkatkan akurasi model. Selain itu, CatBoost memiliki API yang mudah digunakan dan mendukung berbagai bahasa pemrograman, termasuk Python, R, dan C++.
Pada tutorial ini, kita akan fokus mempelajari penggunaan CatBoost dalam bahasa Python. Kita akan menggunakan dataset Heart Failure Prediction yang diambil dari Kaggle (Heart Failure Prediction Dataset). Dataset tersebut juga dapat diakses pada repositori GitHub berikut: Heart Failure Dataset.
Mari kita mulai dengan mempersiapkan data yang diperlukan!
Penyiapan Dataset

Dataset yang akan kita gunakan terdiri dari 918 observasi dengan total 11 fitur. Dari 11 fitur tersebut, 5 diantaranya adalah fitur kategorik sementara 6 lainnya adalah fitur numerik. Kelas respon terdapat pada kolom "HeartDisease" yang memiliki dua kelas, yaitu 0 dan 1. Untuk memudahkan interpretasi hasil analisis, kita akan mengganti kode 0 dan 1 menjadi label "Normal" dan "Heart Disease".
Transformasi ini bersifat opsional dan hanya bertujuan untuk memberikan output yang lebih deskriptif, tanpa mempengaruhi hasil akhir dari proses pemodelan. Berikut adalah langkah-langkah untuk melakukan perubahan tersebut:
Python
import pandas as pd
data = pd.read_csv(
"https://raw.githubusercontent.com/sainsdataid/dataset/main/heart.csv"
)
print(data.info())
# opsional
# untuk memperjelas output kelas respon akan kita ubah menjadi
# 0: Normal, 1: Heart Desease
data["HeartDisease"] = data["HeartDisease"].apply(
lambda x: "Normal" if x == 0 else "Heart Disease"
)
print(data["HeartDisease"].unique())# OUTPUT <class 'pandas.core.frame.DataFrame'> RangeIndex: 918 entries, 0 to 917 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Age 918 non-null int64 1 Sex 918 non-null object 2 ChestPainType 918 non-null object 3 RestingBP 918 non-null int64 4 Cholesterol 918 non-null int64 5 FastingBS 918 non-null int64 6 RestingECG 918 non-null object 7 MaxHR 918 non-null int64 8 ExerciseAngina 918 non-null object 9 Oldpeak 918 non-null float64 10 ST_Slope 918 non-null object 11 HeartDisease 918 non-null int64 dtypes: float64(1), int64(6), object(5) memory usage: 86.2+ KB ['Normal' 'Heart Disease']
Eksplorasi Data
Tahapan eksplorasi data adalah langkah penting untuk memahami karakteristik dataset secara menyeluruh. Namun, dalam tulisan ini, kita hanya akan menyajikan beberapa aspek dasar dari eksplorasi data. Pembahasan mendalam mengenai eksplorasi data akan diserahkan kepada pembaca agar kita dapat lebih fokus pada proses pemodelan.
Berdasarkan analisis jumlah observasi pada kedua kelas, dapat dikatakan bahwa distribusi kelas dalam dataset ini relatif seimbang. Kelas "Heart Disease" terdiri dari 508 observasi, yang merupakan 55,34% dari total data, sedangkan kelas "Normal" terdiri dari 410 observasi atau 44,66% dari total data. Karena distribusi yang sudah relatif seimbang antar kelas, maka kita tidak perlu melakukan penanganan keseimbangan data pada dataset ini.
Python
# menghitung jumlah data menurut kelas
grup = data.groupby("HeartDisease").agg({"HeartDisease": "count"})
# menghitung proporsi setiap kelas
grup["Props"] = round(grup / len(data) * 100, 2)
print(grup)# OUTPUT
HeartDisease Props
HeartDisease
Heart Disease 508 55.34
Normal 410 44.66Ringkasan Statistik
Hasil ringkasan statistik sangat berguna dalam eksplorasi data karena membantu kita memahami kondisi data secara keseluruhan. Melalui ringkasan ini, kita dapat menentukan apakah batas nilai, baik minimal maupun maksimal, sudah sesuai dengan harapan untuk setiap variabel. Jika ditemukan nilai yang tidak ‘masuk akal’, hal ini dapat mengindikasikan adanya nilai ekstrim atau outlier. Oleh karena itu, pemahaman mendalam tentang karakteristik masing-masing variabel sangat diperlukan.
Misalnya, jika kita menemukan nilai minimum atau maksimum yang jauh di luar rentang yang diharapkan, ini bisa menjadi indikasi adanya outlier yang perlu ditangani. Namun, dalam konteks tutorial ini, kita akan menganggap bahwa seluruh data sudah sesuai dan tidak mengandung nilai ekstrim atau tidak masuk akal. Untuk eksplorasi lebih mendalam, silakan lakukan analisis tambahan sesuai kebutuhan.
Python
print(data.describe().round(2))
# OUTPUT
Age RestingBP Cholesterol FastingBS MaxHR Oldpeak
count 918.00 918.00 918.00 918.00 918.00 918.00
mean 53.51 132.40 198.80 0.23 136.81 0.89
std 9.43 18.51 109.38 0.42 25.46 1.07
min 28.00 0.00 0.00 0.00 60.00 -2.60
25% 47.00 120.00 173.25 0.00 120.00 0.00
50% 54.00 130.00 223.00 0.00 138.00 0.60
75% 60.00 140.00 267.00 0.00 156.00 1.50
max 77.00 200.00 603.00 1.00 202.00 6.20Pembagian Data
Pada tahap ini, kita akan membagi dataset menjadi dua bagian, yaitu data latih (training data) dan data uji (testing data). Pembagian dataset ini dilakukan menggunakan fungsi train_test_split dari modul sklearn.model_selection. Kita akan membagi dataset dengan proporsi 70% sebagai data latih dan 30% sebagai data uji. Fungsi ini akan menghasilkan empat set data yang akan kita simpan dalam variabel X_train, y_train, X_test, dan y_test.
Python
from sklearn.model_selection import train_test_split
# Membagi data menjadi fitur dan target
X = data.drop("HeartDisease", axis=1)
y = data["HeartDisease"]
# Membagi data menjadi training dan testing
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=42
)Pemodelan
Pemodelan akan dibagi menjadi dua bagian utama. Pada bagian pertama, kita akan membuat model CatBoost dengan menetapkan nilai-nilai hyperparameter secara langsung. Pada bagian kedua, kita akan melakukan tuning hyperparameter menggunakan metode random search untuk mengoptimalkan kinerja model.
Hyperparameter Model
CatBoost memiliki banyak hyperparameter (103 hyperparameter) yang dapat diatur untuk proses pelatihan. Hyperparameter ini memungkinkan penyesuaian yang sangat mendetail untuk meningkatkan performa model. Berikut adalah beberapa hyperparameter utama dalam CatBoostClassifier yang sangat penting untuk disesuaikan:
iterations: Jumlah pohon keputusan yang akan dibangun oleh model. Meningkatkan jumlah iterasi biasanya meningkatkan akurasi, tetapi juga meningkatkan waktu komputasi dan risiko overfitting. Nilai default untuk iterations adalah 1000learning_rate: Ukuran langkah yang digunakan saat memperbarui bobot dalam setiap iterasi. Nilai yang lebih kecil biasanya menghasilkan model yang lebih stabil, tetapi memerlukan lebih banyak iterasi. Nilai default adalah 0.03depth: Kedalaman maksimum dari setiap pohon keputusan. Kedalaman yang lebih besar memungkinkan model menangkap lebih banyak kompleksitas dalam data, tetapi juga dapat menyebabkan overfitting. Nilai default adalah 6loss_function: Fungsi loss yang digunakan untuk mengukur kesalahan model. Untuk masalah klasifikasi biner, nilai default-nya adalah “Logloss”, sedangkan untuk multi-kelas digunakan “MultiClass”class_weights: Bobot yang diberikan ke setiap kelas untuk menangani masalah ketidakseimbangan kelas. Bobot yang lebih tinggi diberikan ke kelas yang kurang terwakili. Nilai default adalah None, yang berarti kelas dianggap seimbang. Penggunaan bobot yang proporsional (meningkatkan bobot kelas-kelas minoritas secara proporsional) umumnya dapat meningkatkan kinerja model terutama pada kondisi kelas tidak seimbangsubsample: Proporsi data training yang digunakan untuk membangun setiap pohon. Nilai antara 0 dan 1. Nilai yang lebih kecil dapat membantu mencegah overfitting. Nilai default adalah 1, yang berarti menggunakan seluruh datacolsample_bylevel: Proporsi fitur yang dipilih secara acak untuk membangun setiap level pohon. Nilai default adalah 1, yang berarti menggunakan semua fitur. Contoh penggunaan adalah colsample_bylevel=0.8, yang berarti menggunakan 80 persen fitur pada setiap proses splitting pohon- dst
Pelatihan Model
Seperti penjelasan sebelumnya, kita akan membangun model dengan menentukan nilai hyperparameter secara langsung. Nilai-nilai tersebut meliputi iterations=100, learning_rate=0.1, depth=5, dan loss_function=”Logloss”. Nilai hyperparameter lainnya kita tetapkan menggunakan nilai default-nya.
Untuk melatih model, kita dapat memanggil metode fit pada objek CatBoostClassifier yang sudah dibuat sebelumnya. Pada bagian ini, proses pelatihan dilakukan menggunakan data latih yaitu X_train dan y_train. Selain itu, karena dataset memiliki beberapa fitur kategorik, kita perlu menyertakan daftar fitur kategorik tersebut saat pelatihan untuk memberitahu model kolom-kolom fitur yang harus diperlakukan sebagai data kategorik. Jika tidak ditentukan, maka secara otomatis model akan menganggap seluruhnya merupakan fitur numerik.
Python
# import catboost
from catboost import CatBoostClassifier
# Menentukan fitur-fitur kategorik
cat_features = X.select_dtypes(include=["object"]).columns.to_list()
# Membuat model CatBoost
model_cb = CatBoostClassifier(
iterations=100,
learning_rate=0.1,
depth=5,
loss_function="Logloss",
verbose=5,
)
# Melatih model
model_cb.fit(X_train, y_train, cat_features=cat_features)# OUTPUT 0: learn: 0.6623174 total: 1.23ms remaining: 122ms 5: learn: 0.5230669 total: 7.41ms remaining: 116ms 10: learn: 0.4492860 total: 12.7ms remaining: 103ms 15: learn: 0.4047495 total: 18.5ms remaining: 97ms ... ... ... ... 85: learn: 0.2694911 total: 98.1ms remaining: 16ms 90: learn: 0.2682188 total: 105ms remaining: 10.4ms 95: learn: 0.2679034 total: 110ms remaining: 4.58ms 99: learn: 0.2669357 total: 114ms remaining: 0us <catboost.core.CatBoostClassifier at 0x796b5a253bb0>
Prediksi dan Evaluasi
Untuk melihat kinerja model dalam memprediksi, maka model perlu dievaluasi menggunakan data yang belum pernah dilihat selama proses pelatihan dalam hal ini adalah data uji. Kinerja model akan diukur menggunakan metrik accuracy (accuracy_score) dari modul sklearn.metrics . Selain itu kita dapat juga menampilkan output berupa confusion matrix (confusion_matrix) dan classification report (classification_report) dari modul yang sama.
[Lihat juga: Metrik Evaluasi untuk Model Klasifikasi]
Python
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# Memprediksi data uji
y_pred = model_cb.predict(X_test)
# Menghitung akurasi
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# Membuat confusion matrix
cm = confusion_matrix(y_test, y_pred)
print("\nConfusion Matrix:\n", cm)
# membuat classification report
cr = classification_report(y_test, y_pred)
print("\nClassification Report:\n", cr)# OUTPUT
Accuracy: 0.8876811594202898
Confusion Matrix:
[[146 18]
[ 13 99]]
Classification Report:
precision recall f1-score support
Heart Disease 0.92 0.89 0.90 164
Normal 0.85 0.88 0.86 112
accuracy 0.89 276
macro avg 0.88 0.89 0.88 276
weighted avg 0.89 0.89 0.89 276Hasil evaluasi di atas menunjukkan nilai akurasi model yang cukup tinggi yaitu sebesar 0,8877. Nilai ini berarti secara umum model mampu memprediksi dengan benar 88,77 persen keseluruhan data uji. Secara lebih spesifik, kita juga dapat melihat kinerja model menurut kelas-kelasnya. Misalkan untuk kelas Heart Disease, nilai recall adalah 0,89. Ini berarti model mampu memprediksi benar 89 persen data pada kelas tersebut. Dari total 164 data uji dari kelas Heart Disease, model memprediksi benar sebanyak 146 data, sedangkan sisanya sebanyak 18 diprediksi salah sebagai kelas Normal. Selanjutnya, nilai precision 0,92 di mana dari 159 data yang diprediksi sebagai kelas Heart Disease, 146 memang benar merupakan kelas Heart Disease, dan sisanya sebanyak 13 seharusnya adalah bagian dari kelas Normal.
Tuning Hyperparameter
Pada bagian ini, kita akan membuat model menggunakan tuning hyperparameter. Teknik yang akan digunakan adalah random search. Hyperparameter yang akan di-tuning meliputi iterations, learning_rate, depth dan colsample_bylevel. Di luar itu, silahkan jika ingin mencoba dengan tambahan hyperparameter lainnya.
Penentuan Nilai-Nilai Hyperparameter
Proses tuning hyperparameter memerlukan daftar nilai-nilai yang akan dicobakan. Seluruh nilai tersebut perlu kita simpan dalam bentuk dictionary. Setiap key akan berisi nama hyperparameter dan nilainya berupa daftar nilai-nilai yang akan dicobakan untuk hyperparameter tersebut.
Python
# nilai-nilai hyperparameter
param_dist = {
'iterations': [100, 200, 300, 500],
'learning_rate': [0.01, 0.05, 0.1],
'depth': [4, 6, 8, 10],
'colsample_bylevel': [0,3, 0.5, 0.8, 1.0]
}Pencarian Model terbaik
Setelah daftar hyperparameter disiapkan, buat model awal menggunakan fungsi CatBoostClassifier. Pada fungsi ini dapat juga ditambahkan nilai-nilai hyperparameter yang ingin diatur secara manual tanpa proses tuning. Pencarian akan dilakukan dengan teknik random search melalui fungsi RandomizedSearchCV dari modul skelearn.model_selection.
Terdapat parameter-parameter yang perlu ditentukan pada fungsi RandomizedSearchCV, beberapa parameter utamanya yaitu:
estimator: model yang menjadi objek pencarian, dalam hal ini adalahbase_model.param_distributions: daftar hyperparameter modeln_iter: banyaknya iterasi yang akan dilakukan, di mana setiap iterasi akan menggunakan kombinasi acak dari setiap hyperparameter yang diberikan.scoring: metrik yang digunakan untuk membandingkan kinerja antar modelcv: banyaknya fold yang akan digunakan untuk mengukur kinerja model dengan k-fold cv.
Python
from sklearn.model_selection import RandomizedSearchCV
# Definisikan model awal dan parameter untuk RandomizedSearchCV
base_model = CatBoostClassifier(loss_function="Logloss", verbose=0)
random_search = RandomizedSearchCV(
base_model,
param_distributions=param_dist,
n_iter=20,
scoring="accuracy",
cv=5, # Cross-validation 5-fold
random_state=42, # Random seed untuk hasil yang dapat direproduksi
n_jobs=-1, # Menggunakan semua core CPU yang tersedia
)
# Melakukan random search dan fitting data training
random_search.fit(X_train, y_train, cat_features=cat_features)
# Menampilkan parameter terbaik
print(f"Best parameters found: {random_search.best_params_}")
# Menampilkan skor akurasi terbaik hasil CV
print(f"Best CV Score: {random_search.best_score_}")# OUTPUT
Best parameters found: {'learning_rate': 0.1, 'iterations': 100, 'depth': 8, 'colsample_bylevel': 0.5}
Best CV Score: 0.862875484496124Pada contoh di atas, kita melakukan pencarian sebanyak 20 iterasi. Artinya, pencarian dilakukan terhadap 20 kombinasi hyperparameter secara acak. Dari proses ini diperoleh kombinasi dengan skor terbaik adalah pada nilai learning_rate: 0.1, iterations: 100, depth: 8 dan colsample_bylevel: 0.5. Skor yang diperoleh (berdasarkan rata-rata nilai akurasi melalui cross validation dengan 5 fold) adalah sebesar 0,8629.
Prediksi dan Evaluasi
Setelah hyperparameter terbaik diperoleh, kita dapat menghitung kembali nilai akurasi seperti pada model sebelumnya. Hasil penghitungan menunjukkan nilai akurasi model pada data uji adalah 0,9022. Model mampu memprediksi benar sebanyak 90,22 persen data uji. Dengan cara yang sama, kita juga dapat melihat lebih detail melalui confusion matrix dan classification report.
Python
# Memilih model terbaik
model_cb_cv = random_search.best_estimator_
# Memprediksi data uji
y_pred_cv = model_cb_cv.predict(X_test)
# Menghitung akurasi
accuracy_cv = accuracy_score(y_test, y_pred_cv)
print(f"Accuracy: {accuracy_cv}")
cm_cv = confusion_matrix(y_test, y_pred_cv)
print("\nConfusion Matrix:\n", cm_cv)
cr_cv = classification_report(y_test, y_pred_cv)
print("\nClassification Report:\n", cr_cv)# OUTPUT
Accuracy: 0.9021739130434783
Confusion Matrix:
[[150 14]
[ 13 99]]
Classification Report:
precision recall f1-score support
Heart Disease 0.92 0.91 0.92 164
Normal 0.88 0.88 0.88 112
accuracy 0.90 276
macro avg 0.90 0.90 0.90 276
weighted avg 0.90 0.90 0.90 276Persistensi Model
Persistensi model adalah proses menyimpan model yang telah dilatih ke dalam sebuah file sehingga model tersebut dapat digunakan kembali di masa depan tanpa perlu melatih ulang. Ini sangat berguna ketika kita ingin menggunakan model yang sama untuk melakukan prediksi di waktu mendatang atau untuk diterapkan pada aplikasi produksi.
Menyimpan Model
Setelah model terbaik ditemukan melalui proses tuning hyperparameter dan pelatihan, kita menyimpannya menggunakan fungsi dump dari pustaka joblib. File yang dihasilkan akan berisi seluruh informasi yang diperlukan untuk merekonstruksi model, termasuk struktur model dan bobot yang telah dilatih. Misalnya, joblib.dump(best_model, 'model_catboost.pkl') akan menyimpan model terbaik ke dalam file model_catboost.pkl.
Python
import joblib
model_filename = 'model_catboost.pkl'
joblib.dump(model_cb_cv, model_filename)
print(f"Model saved to {model_filename}")# OUTPUT Model saved to model_catboost.pkl
Memuat Model
Model yang telah disimpan dapat dimuat kembali dari file menggunakan fungsi load dari pustaka joblib. Misalnya, loaded_model = joblib.load('model_catboost.pkl') akan memuat model dari file model_catboost.pkl dan menyimpannya dalam variabel loaded_model.
Python
loaded_model = joblib.load(model_filename)
print(f"Model loaded from {model_filename}")# OUTPUT Model loaded from catboost_model.pkl
Prediksi Data Baru
Setelah model dimuat, kita dapat menggunakannya untuk membuat prediksi pada data baru. Misalkan, terdapat data baru dari 3 orang seperti yang disajikan berikut ini. Berdasarkan data tersebut, maka kita dapat memprediksi kemungkinan kondisi ketiganya menggunakan model yang kita miliki.
Hasil prediksi model menunjukkan bahwa orang pertama dan ketiga diperkirakan memiliki kondisi Normal. Adapun untuk orang kedua diprediksi terkena Heart Disease.
Python
# contoh data baru
data_baru = [{'Age': 55,
'Sex': 'M',
'ChestPainType': 'ATA',
'RestingBP': 140,
'Cholesterol': 196,
'FastingBS': 0,
'RestingECG': 'Normal',
'MaxHR': 150,
'ExerciseAngina': 'N',
'Oldpeak': 0.0,
'ST_Slope': 'Up'},
{'Age': 39,
'Sex': 'M',
'ChestPainType': 'ASY',
'RestingBP': 118,
'Cholesterol': 219,
'FastingBS': 0,
'RestingECG': 'Normal',
'MaxHR': 140,
'ExerciseAngina': 'N',
'Oldpeak': 1.2,
'ST_Slope': 'Flat'},
{'Age': 49,
'Sex': 'M',
'ChestPainType': 'ATA',
'RestingBP': 130,
'Cholesterol': 266,
'FastingBS': 0,
'RestingECG': 'Normal',
'MaxHR': 171,
'ExerciseAngina': 'N',
'Oldpeak': 0.6,
'ST_Slope': 'Up'}]
# memformat data dalam bentuk dataframe
data_baru_df = pd.DataFrame(data_baru)
# memprediksi kelas data baru
pred_data_baru = loaded_model.predict(data_baru_df)
print(data_baru_df.transpose())
print("\nHasil Prediksi:\n", pred_data_baru)# OUTPUT
0 1 2
Age 55 39 49
Sex M M M
ChestPainType ATA ASY ATA
RestingBP 140 118 130
Cholesterol 196 219 266
FastingBS 0 0 0
RestingECG Normal Normal Normal
MaxHR 150 140 171
ExerciseAngina N N N
Oldpeak 0.0 1.2 0.6
ST_Slope Up Flat Up
Hasil Prediksi:
['Normal' 'Heart Disease' 'Normal']Feature Importance
Feature Importance adalah metrik yang digunakan untuk menentukan seberapa penting masing-masing fitur dalam membuat prediksi dalam model machine learning. Dalam konteks model CatBoost, fitur importance menunjukkan kontribusi relatif dari setiap fitur dalam meningkatkan akurasi model. Fitur dengan nilai importance yang lebih tinggi memiliki pengaruh yang lebih besar terhadap prediksi model.
Nilai feature importance pada model CatBoostClassifier dapat diakses melalui properti feature_importances_. Nilai-nilai ini biasanya disajikan dalam bentuk visualisasi menggunakan diagram batang. Berdasarkan hasil di bawah ini, fitur dengan tingkat kepentingan tertinggi adalah ST_Slope diikuti dengan ChestPaintType dan Oldpeak.
Python
import matplotlib.pyplot as plt
# Menampilkan Fitur Importance
feature_importances = loaded_model.feature_importances_
feature_names = X.columns
# Membuat DataFrame untuk Fitur Importance
feature_importance_df = pd.DataFrame({
'Feature': feature_names,
'Importance': feature_importances
}).sort_values(by='Importance', ascending=False)
# Menampilkan DataFrame Fitur Importance
print("\nFeature Importances:")
print(feature_importance_df)
# Membuat Plot Fitur Importance
plt.figure(figsize=(6, 4))
plt.barh(feature_importance_df['Feature'], feature_importance_df['Importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importances')
plt.gca().invert_yaxis()
plt.show()# OUTPUT
Feature Importances:
Feature Importance
10 ST_Slope 19.828454
2 ChestPainType 14.311525
9 Oldpeak 12.260473
4 Cholesterol 9.560191
6 RestingECG 8.825954
0 Age 7.784245
3 RestingBP 7.404105
7 MaxHR 5.686459
1 Sex 5.348056
8 ExerciseAngina 5.074764
5 FastingBS 3.915775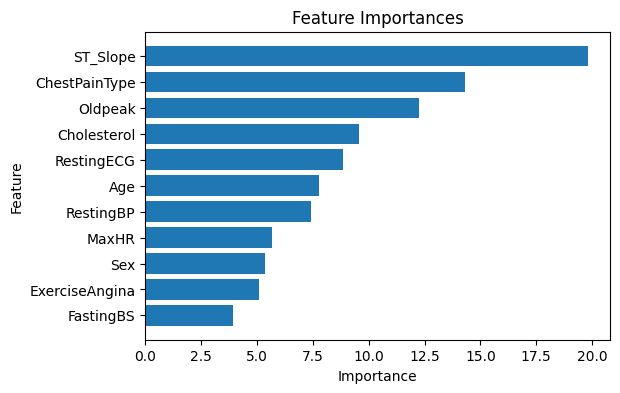
API
- CatBoost: CatBoost Documentation
- RandomSearchCV: RandomizedSearchCV — scikit-learn documentation







