Support Vector machine (SVM) untuk Model Klasifikasi dengan Python
Tulisan ini merupakan kelanjutan dari tulisan sebelumnya Support Vector Machine (SVM): Teori dan Konsep Dasar. Pada bagian ini kita akan mengimplementasikan SVM menggunakan python, khususnya untuk pemodelan klasifikasi.
Penyiapan Data
Data yang digunakan adalah dataset wine quality dengan versi yang sudah dikelompokkan menjadi kelas biner ('HIGH' dan 'LOW'). Dataset terdiri 1143 amatan dengan 11 variabel input/fitur yang seluruhnya bertipe numerik dan 1 kolom sebagai label (quality). Terdapat 1 kolom yang perlu dihapus yaitu id karena tidak diperlukan dalam pemodelan.
Python
import pandas as pd
data = pd.read_csv("https://raw.githubusercontent.com/sainsdataid/dataset/main/wine-quality-binary.csv")
# menghapus kolom `id`
data = data.drop("id", axis=1)
data.info()# OUTPUT <class 'pandas.core.frame.DataFrame'> RangeIndex: 1143 entries, 0 to 1142 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 fixed.acidity 1143 non-null float64 1 volatile.acidity 1143 non-null float64 2 citric.acid 1143 non-null float64 3 residual.sugar 1143 non-null float64 4 chlorides 1143 non-null float64 5 free.sulfur.dioxide 1143 non-null float64 6 total.sulfur.dioxide 1143 non-null float64 7 density 1143 non-null float64 8 pH 1143 non-null float64 9 sulphates 1143 non-null float64 10 alcohol 1143 non-null float64 11 quality 1143 non-null object dtypes: float64(11), object(1) memory usage: 107.3+ KB
Eksplorasi Data
Sebelum masuk pada tahap pemodelan kita dapat melakukan berbagai eksplorasi untuk melihat kondisi data termasuk melakukan pengecekan data hilang atau nilai ekstrim jika diperlukan. Data yang kita gunakan pada dasarnya sudah dalam kondisi ‘clean’, sehingga hanya akan disajikan beberapa eksplorasi saja. Silahkan melakukan eksplorasilebih lengkap jika diinginkan.
Jumlah Data Menurut kelas
Berdasarkan hasil berikut, kondisi data relatif berimbang dengan proporsi kelas 'HIGH' sebesar 54,33 persen dan kelas 'LOW' sebesar 45,67 persen. Dengan demikian, kita mungkin tidak perlu mengkhawatirkan kondisi keseimbangan data ataupun melakukan penanganan apapun.
Python
# Jumlah data untuk masing-masing kelas grup = data["quality"].value_counts() grup_prop = grup / data["quality"].count() print(grup) print(grup_prop)
# OUTPUT quality HIGH 621 LOW 522 quality HIGH 0.543307 LOW 0.456693
Nilai Rataan Fitur Menurut Kelas
Kita juga dapat melihat bagaimana karakteristik masing-masing kelas berdasarkan nilai fitur-fiturnya. Misalkan rata-rata kadar alcohol pada kelas 'HIGH' terlihat lebih tinggi dibandingkan kelas 'LOW'. Sebaliknya rata-rata kadar total.sulfur.dioxide pada kelas 'HIGH' jauh lebih rendah dibandingkan kelas 'LOW'. Contoh lainnya pada density dan pH terlihat kedua kelas hampir tidak memiliki perbedaan. Artinya kemungkinan fitur ini tidak memiliki kontribusi besar untuk membedakan kedua kelas. Namun tentu saja ini baru pengamatan awal sehingga berikutnya kita dapat mengeksplorasi lebih dalam lagi.
Python
summary = data.groupby('quality').mean().transpose()
print(summary)# OUTPUT quality HIGH LOW fixed.acidity 8.453140 8.142146 volatile.acidity 0.476884 0.596121 citric.acid 0.296329 0.235096 residual.sugar 2.522544 2.543582 chlorides 0.082575 0.092117 free.sulfur.dioxide 14.952496 16.404215 total.sulfur.dioxide 39.104670 54.016284 density 0.996458 0.997054 pH 3.313205 3.308410 sulphates 0.694283 0.614195 alcohol 10.878878 9.922510
Sebaran Nilai Fitur Menurut Kelas
Jika diperlukan, kita dapat membuat plot sebaran suatu fitur untuk masing-masing kelas untuk melihat perbandingan secara visual. Misalkan kita menyajikan boxplot untuk sebaran nilai alcohol dan pH menurut kelasnya. Dari visualisasi tersebut terlihat bahwa nilai alcohol pada kelas 'HIGH' memiliki kecenderungan lebih tinggi dibandingkaan kelas 'LOW'. Sementara itu, pada boxplot nilai pH sebaran nilainya terlihat tidak terlalu berbeda antar kedua kelas, hal ini bisa menjadi indikasi kemungkinan fitur ini tidak memiliki pengaruh yang besar dalam menentukan kelas data.
Python
# Membuat plot boxplot untuk kolom alcohol
plt.figure(figsize=(8, 4))
sns.boxplot(x='quality', y='alcohol', hue='quality', data=data)
plt.title('Sebaran nilai alcohol Menurut quality')
plt.show()
# Membuat plot boxplot untuk kolom pH
plt.figure(figsize=(8, 4))
sns.boxplot(x='quality', y='pH', hue='quality', data=data)
plt.title('Sebaran nilai pH Menurut quality')
plt.show()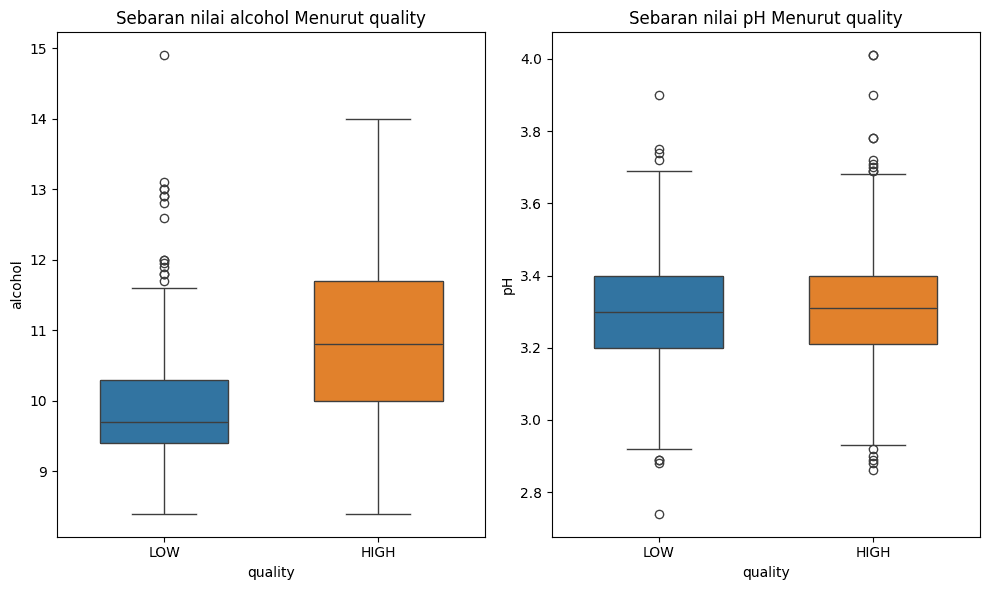
Prapemrosesan Data
Ada dua hal yang akan kita lakukan pada bagian ini yaitu pembagian data dan standardisasi data. Pembagian data tentunya merupakan langkah penting agar model dapat dilatih dan dievaluasi dengan data yang berbeda. Pembagian data akan dilakukan dengan fungsi train_test_split dari modul sklearn.model_selection. Model akan kita latih menggunakan 70 persen data dan sisanya sebanyak 30 persen sebagai data uji.
Adapun standardisasi data (atau dapat juga menggunakan normalisasi), dalam pemodelan SVM juga merupakan langkah penting karena algoritmanya yang sangat bergantung dengan jarak. Oleh karena itu, perbedaan skala data perlu disesuaikan agar pelatihan model tidak terpengaruh akibat perbedaan tersebut. Proses standardisasi akan membuat setiap fitur memiliki nilai rata-rata 0 dan standar deviasi 1. Standardisasi dapat dilakukan menggunakan fungsi StandarScaler dari modul sklearn.preprocessing. Sebagai catatan, standardisasi hanya kita lakukan berdasarkan data latih saja melalui metode fit_transform. Hal ini penting untuk menghindari adanya data leakage pada data uji dalam proses pelatihan model.
Python
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
import numpy as np
# membuat data fitur/input
X = data.drop("quality", axis=1)
# membuat data output
y = data["quality"]
# membagi data traning 70% dan data testing 30%
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=123
)
# membuat objek scaler untuk standardisasi
scaler = StandardScaler()
# Standardisasi skala data fitur
scaled_X_train = scaler.fit_transform(X_train)
scaled_X_test = scaler.transform(X_test)
# menampilkan ringkasan statistik hasil standardisasi
feature_mean = np.round(np.mean(scaled_X_train, axis=0), 2)
feature_sd = np.round(np.std(scaled_X_train, axis=0))
print("Rata-rata :", feature_mean)
print("Standar deviasi:", feature_sd)# OUTPUT Rata-rata : [ 0. -0. -0. 0. -0. 0. -0. -0. -0. 0. -0.] Standar deviasi: [1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
Pemodelan SVM
Pembuatan model SVM untuk klasifikasi dilakukan menggunakan fungsi SVC dari modul sklearn.SVM. Terdapat berbagai parameter yang dapat diatur yaitu:
C: Parameter regulasi (regularization parameter). Parameter ini mengontrol trade-off antara misclassification error pada training data dan margin maksimal. Nilai yang lebih tinggi dariCakan mencoba untuk meminimalkan misclassification error pada training data dengan mengorbankan margin maksimal. Default:1.0kernel: Fungsi kernel yang digunakan untuk memproyeksikan data ke dalam ruang fitur yang lebih tinggi. Kernel yang umum digunakan meliputi'linear'(kernel linear),'poly'(kernel polinomial),'rbf'(Radial Basis Function kernel atau Gaussian kernel), dan'sigmoid'(kernel sigmoid). Dapat juga menggunakan fungsi yang kita definisikan sendiri. Default:'rbf'degree: Tingkat atau derajat polinomial fungsi kernel, digunakan hanya padakernel='poly'. Default:3gamma: Koefisien kernel untuk fungsi kernelrbf,poly, dansigmoid. Nilaigammamengontrol seberapa jauh pengaruh dari satu data training tunggal. Nilai yang kecil berarti pengaruh yang lebih besar dari setiap data poin. Default:'scale'(yaitu1 / (n_features * X.var()))coef0: Parameter untuk bias (intercept) dalam kernel polinomial dan sigmoid. Default:0.0tol: Toleransi untuk menghentikan kriteria yang mengontrol presisi dari solusi akhir. Default:1e-3max_iter: Batas maksimal iterasi untuk algoritma pelatihan. Default:-1(tanpa batas iterasi, penghentian algoritma berdasarkan nilaitol)class_weight: Bobot yang terkait dengan kelas-kelas dalam data input. Berguna untuk menangani data yang tidak seimbang. Default:Noneprobability: JikaTrue, mengaktifkan estimasi probabilitas. Hal ini mengharuskanfitdengan parameter cross-validationn_splits > 1. Default:Falserandom_state: Menetapkan seed tertentu untuk hasil yang dapat direproduksi. Default:None
Pelatihan Model
Pada bagian ini, kita akan membuat 3 model SVM sekaligus. Model pertama menggunakan kernel "linier"; kedua menggunakan kernel "poly" dengan degree=2; dan model ketiga menggunakan kernel "rbf" dengan gamma sesuai nilai default-nya. Silahkan pembaca mengeksplorasi jika ingin merubah pengaturan lainnya.
Python
# Impor kelas SVM dari sklearn from sklearn.svm import SVC # Inisialisasi model SVM dengan kernel linier dan C=1.0 (default) svm_lin = SVC(kernel='linear', C=1.0) # Inisialisasi model SVM dengan kernel poly dengan degree=2 svm_pol = SVC(kernel='poly', degree=2, C=1.0) # Inisialisasi model SVM dengan kernel rbf dan gamma menggunakan nilai default svm_rbf = SVC(kernel='rbf', C=1.0) # Latih model-model SVM pada data latih svm_lin.fit(scaled_X_train, y_train) svm_pol.fit(scaled_X_train, y_train) svm_rbf.fit(scaled_X_train, y_train)
Evaluasi dan Prediksi
Model yang diperoleh selanjutnya digunakan untuk memprediksi data uji sekaligus mengevaluasi hasil model tersebut. Pada contoh dibawah ini, kita menggunakan metrik accuracy sebagai ukuran kinerja model.
Hasil di bawah ini menunjukkan kinerja model SVM pada data uji. Model dengan kernel linier memperoleh nilai akurasi sebesar 0,7551. nilai ini sedikit lebih rendah dibandingkan akurasi model dengan kernel rbf yaitu sebesar 0,7638. Sementara untuk model yang menggunakan kernel poli dengan degree=2 memperoleh akurasi yang jauh di bawah keduanya, yaitu hanya sebesar 0,6385.
Python
# Evaluasi akurasi model
accuracy_lin = svm_lin.score(scaled_X_test, y_test)
accuracy_pol = svm_pol.score(scaled_X_test, y_test)
accuracy_rbf = svm_rbf.score(scaled_X_test, y_test)
print(f'Akurasi SVM (Kernel linier): {accuracy_lin:.4f}')
print(f'Akurasi SVM (Kernel Polinomial-2): {accuracy_pol:.4f}')
print(f'Akurasi SVM (Kernel RBF): {accuracy_rbf:.4f}')
# Prediksi kelas pada data uji
y_pred_lin = svm_lin.predict(scaled_X_test)
y_pred_pol = svm_pol.predict(scaled_X_test)
y_pred_rbf = svm_rbf.predict(scaled_X_test)
# contoh hasil prediksi pada model SVM (Kernel RBF)
print("\nHasil prediksi data uji dengan SVM Kernel RBF:")
print(y_pred_rbf)# OUTPUT Akurasi SVM (Kernel linier): 0.7551 Akurasi SVM (Kernel Polinomial-2): 0.6385 Akurasi SVM (Kernel RBF): 0.7638 Hasil prediksi data uji dengan SVM Kernel RBF: ['HIGH' 'LOW' 'LOW' 'HIGH' 'HIGH' ... 'LOW' 'LOW' 'LOW']
Selain metode score, melalui berbagai fungsi pada modul sklearn.metrics kita dapat menampilkan ukuran kinerja lebih lengkap termasuk accuracy, balanced accuracy, f1-score, precision sampai dengan cofusion matrix dan classification report. Agar lebih ringkas, contoh kode berikut ini hanya menampilkan hasil untuk model SVM dengan kernel RBF. Dengan cara yang sama tentu saja fungsi-fungsi tersebut berlaku juga untuk model lainnya. [lihat: Metrik Evaluasi untuk Model Klasifikasi].
Python
from sklearn.metrics import (
accuracy_score,
balanced_accuracy_score,
confusion_matrix,
classification_report,
)
# Accuracy
acc_rbf = accuracy_score(y_test, y_pred_rbf)
print(f"Accuracy: {acc_rbf: .4f}")
# Bal. Accuracy
bal_rbf = balanced_accuracy_score(y_test, y_pred_rbf)
print(f"\nBalance Accuracy: {bal_rbf: .4f}")
# Evaluasi confusion matrix
cm = confusion_matrix(y_test, y_pred_rbf)
print("\nConfusion Matrix:")
print(cm)
# Evaluasi classification report
print("\nClassification Report:")
print(classification_report(y_test, y_pred_rbf))# OUTPUT
Accruacy: 0.7638
Balance Accuracy: 0.7624
Confusion Matrix:
[[145 41]
[ 40 117]]
Classification Report:
precision recall f1-score support
HIGH 0.78 0.78 0.78 186
LOW 0.74 0.75 0.74 157
accuracy 0.76 343
macro avg 0.76 0.76 0.76 343
weighted avg 0.76 0.76 0.76 343Tuning Hiperparameter
Model-model sebelumnya dibangun dengan menetapkan secara langsung nilai parameternya. Untuk mencari model yang lebih baik kita dapat melakukan tuning hyperparameter seperti Grid Search, Random Search atau teknik lainnya. Pada contoh ini kita akan menggunakan teknik Grid Search. Grid Search bekerja dengan mencoba seluruh kemungkinan model dari berbagai nilai parmeter yang diberikan.
Modul sklearn.model_selection menyediakan berbagai fungsi untuk pencarian hyperparameter ini. Contohnya, untuk teknik Grid Search maka kita dapat menggunakan fungsi GridSearchCV.
Penentuan model terbaik dapat menggunakan berbagai metrik nilai seperti yang disampaikan sebelumnya. Kita akan melakukan iterasi untuk berbagai nilai parameter dan mencari model yang memberikan skor terbaik. Pada contoh ini akan mengunakan metrik accuracy. Semakin tinggi nilai yang diperoleh maka performa model semakin baik.
Penetapan Ruang Hyperaprameter
Ruang hyperparameter adalah daftar nilai-nilai parameter model yang akan diujikan. Pada teknik Grid Search, pencarian model akan dilakukan dengan mencoba keseluruhan kombinasi parameter. Semakin banyak kombinasi maka komputasi yang dibutuhkan menjadi semakin lama. Namun, tentunya peluang menemukan model yang semakin baik juga menjadi lebih besar.
Python
# Definisikan grid parameter yang akan diuji
param_grid = {
"kernel": ["linear", "rbf", "poly", "sigmoid", ], # Kernel yang akan diuji: linear dan rbf
"C": [1, 2, 3, 4, 5], # Nilai C yang akan diuji
"gamma": ["scale", "auto", 0.05, 0.1, 0.2], # Parameter gamma untuk kernel rbf
"degree": [3, 4], # parameter degree hanya untuk kernel poly
"class_weight": [None, "balanced"], # parameter penanganan kelas data
# silahkan tambah/kurangi parameter lainnya yang ingin diatur
}Pencarian Model
Pencarian model dilakukan untuk setiap kombinasi dari ruang hyperparameter yang sudah ditentukan. Evaluasi kinerja selama proses pencarian dilakukan menggunakan K-Fold Cross Validation dengan jumlah fold sebanyak 5. Hasil pencarian melalui fungsi GridSearchCV memperoleh kombinasi parameter terbaik yaitu menggunakan kernel rbf dengan nilai gamma=0.1 dan C=4 (parameter degree dapat diabaikan karena hanya berlaku pada kernel poly).
Python
from sklearn.model_selection import GridSearchCV
# Definisikan model SVM
svm_model = SVC()
# Inisialisasi GridSearchCV dengan model SVM, parameter grid, dan metrik yang digunakan
# evaluasi kinerja dilakukan dengan teknik cross-validation (cv) dengan 5 fold
grid_search = GridSearchCV(
estimator=svm_model,
param_grid=param_grid,
scoring="accuracy",
cv=5,
refit=True,
)
# Lakukan pencarian parameter berdasarkan data latih
grid_search.fit(scaled_X_train, y_train)
# Tampilkan parameter terbaik dan skor validasi silang terbaik
print("Parameter terbaik:", grid_search.best_params_)
print("Skor validasi silang terbaik (train):", grid_search.best_score_)# OUTPUT
Parameter terbaik: {'C': 4, 'class_weight': 'balanced', 'degree': 3, 'gamma': 0.1, 'kernel': 'rbf'}
Skor validasi silang terbaik (train): 0.76875Evaluasi dan Prediksi
Sama seperti sebelumnya, model yang diperoleh perlu dievaluasi menggunakan data uji untuk mengetahui kinerja yang sebenarnya. Hasil evaluasi menunjukkan nilai akurasi model pada data uji sebesar 0,7697.
Python
# Evaluasi model terbaik pada data uji
best_model = grid_search.best_estimator_
y_pred = best_model.predict(scaled_X_test)
# Accuracy
acc_rbf = accuracy_score(y_test, y_pred)
print(f"Accuracy: {acc_rbf: .4f}")
cm = confusion_matrix(y_test, y_pred)
print("\nConfusion Matrix:")
print(cm)
cr = classification_report(y_test, y_pred)
print("\nClassification Report:")
print(cr)# OUTPUT
Accuracy: 0.7697
Confusion Matrix:
[[142 44]
[ 35 122]]
Classification Report:
precision recall f1-score support
HIGH 0.80 0.76 0.78 186
LOW 0.73 0.78 0.76 157
accuracy 0.77 343
macro avg 0.77 0.77 0.77 343
weighted avg 0.77 0.77 0.77 343Prediksi Data Baru
Setelah memperoleh model terbaik, maka kita dapat melakukan prediksi pada data baru. Sebagai contoh, terdapat data 2 wine baru dan kita ingin mengetahui perkiraan kualitasnya. Langkah untuk memprediksi data tersebut adalah sebagai berikut:
Python
# contoh data baru
new_data = pd.DataFrame({'fixed.acidity' : [8.25, 7.94],
'volatile.acidity' : [0.46, 0.48],
'citric.acid' : [0.32, 0.28],
'residual.sugar' : [2.6, 2.6],
'chlorides': [0.065, 0.081],
'free.sulfur.dioxide': [14.7, 14.7],
'total.sulfur.dioxide': [38.24, 38.85],
'density': [0.96, 0.98],
'pH': [3.4, 3.4],
'sulphates': [0.72, 0.70],
'alcohol': [11.4, 9.8]
})
print(new_data.transpose())
# data baru perlu di scaling dengan scaler yang digunakan saat pelatihan
scaled_new_data = scaler.transform(new_data)
# prediksi kelas data
prediksi = svm_lin.predict(scaled_new_data)
print(f"\nKualitas: {prediksi}")# OUTPUT
0 1
fixed.acidity 8.250 7.940
volatile.acidity 0.460 0.480
citric.acid 0.320 0.280
residual.sugar 2.600 2.600
chlorides 0.065 0.081
free.sulfur.dioxide 14.700 14.700
total.sulfur.dioxide 38.240 38.850
density 0.960 0.980
pH 3.400 3.400
sulphates 0.720 0.700
alcohol 11.400 9.800
Kualitas: ['HIGH' 'LOW']Prediksi model menunjukkan bahwa wine pertama masuk dalam kategori kelas "HIGH" dan wine kedua sebagai kelas "LOW".
Selamat mencoba!
API
SVC: SVC — scikit-learn documentationGridSearchCV: GridSearchCV — scikit-learn documentation- Metrik Evaluasi: sklearn.metrics — scikit-learn documentation
- Partisi Data: train_test_split — scikit-learn documentation
- Standardisasi Data: StandardScaler — scikit-learn 1.5.0 documentation